یادگیری همترازی کلمات همزمان با ترجمه، رویکردی نو در ترجمه ماشینی عصبی
ترجمه ساراناز عبداللهی از مقاله NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE

چکیده
تا پیش از سال 2014 و ظهور ترجمه ماشینی مبتنیبر شبکههای عصبی (NMT)، ترجمه ماشینی اغلب مبتنیبر روشهای آماری (SMT) انجام میشد. مدلهای اولیهی NMT عمدتا به خانوادهی مدلهای کدگذار-کدگشا تعلق داشتند. در این گونه مدلها، کدگزار دنبالهی ورودی را به برداری با اندازه ثابت نگاشت کرده و کدگشا با توجه به بردار کدشده، ترجمهی هدف را تولید میکند. پژوهشگران باور داشتند که محدود کردن مدل به استفاده از یک بردار با اندازهی ثابت برای بازنمایی دنبالههای ورودی با طولهای مختلف، مانع اصلی در بهبود عملکرد مدلها میباشد. به همین دلیل رویکردی نو در جهت حذف محدودیت ثابت بودن طول بردار بازنمایی ارائه دادند. در این رویکرد، به جای محدود کردن مدل به نگاشت جملهی ورودی به برداری با طول ثابت، هر جملهی ورودی به دنبالهای از بردارها نگاشت شده و تنها مرتبطترین زیرمجموعه از این بردارها برای روند کدگشایی انتخاب میشود. در این حالت به مدل اجازه داده میشود تا بهصورت خودکار به جستوجوی نرم در جملهی ورودی بپردازد و به بخشهایی از جمله مبدأ توجه کند که دارای مرتبطترین اطلاعات به کلمه هدف (کلمه ترجمه) میباشد. این رویکرد جدید، توانست در وظیفه ترجمه انگلیسی به فرانسوی، عملکرد قابل مقایسهای با سیستمهای پیشرو مبتنیبر عبارات بهدست آورد. علاوهبراین، مطابق با تجزیهوتحلیل کیفی، همترازیهای یافتشده توسط مدل با استنتاج انسانی ما همخوانی نزدیکی داشت.
مقدمه
ترجمه ماشینی مبتنیبر شبکههای عصبی (NMT) بهعنوان یک رویکرد ترجمه ماشینی در حدود سالهای 2014-2013 معرفی شد. برخلاف مدل سنتی ترجمه مبتنیبرعبارت که از زیربخشهای کوچک متعدد تشکیل شده، در مدلهای NMT هدف ساخت یک شبکه عصبی یکپارچهی واحد و بزرگ میباشد که با خواندن جملهی ورودی، ترجمهی صحیحی را بهعنوان خروجی ارائه دهد.
بیشتر مدلهای NMT، به خانواده مدلهای کدگذار-کدگشا تعلق دارند. کدگذار، جمله مبدأ را خوانده و آن را به شکل یک بردار با طول ثابت کد میکند و کدگشا، بردار کدشده را به دنبالهی هدف ترجمه میکند. در تمام سیستمهای کدگذار-کدگشا، این دو بخش با هم آموزش داده میشوند تا احتمال ارائه ترجمه درست را بیشینه کنند.
مشکل بالقوه در روش کدگذار-کدگشا این است که شبکه عصبی باید قادر به فشردهسازی تمام اطلاعات جمله مبدأ در یک بردار با طول ثابت باشد. محدودیت ثابت بودن طول بردار، باعث کندی و بعضاً شکست شبکه عصبی در هنگام مواجهه با جملات بلند میشود، بهخصوص در جملاتی که بلندتر از جملات موجود در مجموعه آموزشی هستند.
برای حل این مشکل، مدل کدگذار-کدگشا بهگونهای توسعه داده شد که مدل جدید بتواند در ترجمهی جملات طولانی عملکرد قابل قبولی بهدست آورد. ویژگی مهم و تمایزدهنده این رویکرد نسبت به کدگذار-کدگشا پایه این بود که در آن تلاشی برای کدگذاری کل جمله ورودی به برداری با طول ثابت نمیشود. به جای آن، مدل، جمله ورودی را به دنبالهای از بردارها کد کرده و در حین کدگشایی ترجمه، یک زیرمجموعه از این بردارها را بهصورت تطبیقی انتخاب میکند. این رویکرد، NMT را از فشردهسازی تمامی اطلاعات جمله مبدأ(بدون توجه به طول جمله) در یک بردار با طول ثابت بینیاز میکند. در نتیجه، مدل با جملات طولانی سازگاری بهتری پیدا میکند.
ویژگی دیگر مدل توسعهیافته یادگیری همزمان همترازی کلمات و ترجمه بود. در ترجمه ماشینی، برای ترجمه یک جمله مبدأ به زبان هدف، باید کلمات و جملات مبدأ را بهصورت دقیقی به کلمات و جملات معادل در زبان هدف ترجمه کرد. این کار بسیار پیچیده است، زیرا ممکن است معادل کلمات و جملات در زبان هدف وجود نداشته باشد و یا ترتیب کلمات در زبان هدف و زبان مبدأ متفاوت باشد. برای حل این مشکلات و دستیابی به یک ترجمه دقیق، نیاز است که هر کلمه از جمله مبدأ را با معادل مناسب آن در زبان هدف همتراز کنیم. برای مثال، اگر "I have a cat" را به زبان فرانسه "J'ai un chat" ترجمه کنیم، کلمه "I" باید با "J'" و "cat" باید با "chat" همتراز شود.
پیشینه پژوهش
از نظر احتمالاتی، ترجمه معادلِ یافتن مقدار بیشینه احتمال شرطی جمله هدف y با توجه به جمله مبدأ x، یا بهعبارت دیگر ![]() میباشد. هنگامیکه این توزیع شرطی توسط مدل آموخته شد، با مدنظر قرار دادن جمله مبدأ، ترجمه متناظر با جستوجوی جملهای که احتمال شرطی را به حداکثر میرساند، تولید میشود.در سال 2014، تعدادی مقاله پیشنهاد دادند تا از شبکههای عصبی برای یادگیری مستقیم این توزیع شرطی استفاده شود.
میباشد. هنگامیکه این توزیع شرطی توسط مدل آموخته شد، با مدنظر قرار دادن جمله مبدأ، ترجمه متناظر با جستوجوی جملهای که احتمال شرطی را به حداکثر میرساند، تولید میشود.در سال 2014، تعدادی مقاله پیشنهاد دادند تا از شبکههای عصبی برای یادگیری مستقیم این توزیع شرطی استفاده شود.
استفاده از شبکههای عصبی در ترجمه ماشینی
در سال 2003 مدل زبان احتمالاتی عصبی معرفی شد، که از شبکه عصبی برای مدلسازی احتمال شرطی یک کلمه با توجه به تعداد ثابتی از کلمات قبلی استفاده میکرد. پس از این پژوهش، شبکههای عصبی بهطور گستردهای در ترجمه ماشینی استفاده شدند. هر چند که نقش شبکههای عصبی تا مدتها به اضافه کردن یک ویژگی در سیستمSMT یا رتبهبندی مجدد لیستی از ترجمههای کاندید، محدود شده بود.
برای مثال، در سال 2012 از یک شبکه عصبی روبهجلو برای امتیازدهی به جفت عبارات مبدأ و هدف استفاده گردید. سپس این امتیاز بهعنوان یک ویژگی به سیستمSMT مبتنیبر عبارت اضافه شد. در سالهای 2013 و 2014، استفاده موفقی از شبکههای عصبی بهعنوان یک جزء فرعی از سیستم ترجمه گزارش شد.
اگرچه رویکردهای فوق توانستند عملکرد ترجمه ماشینی را بهبود دهند، اما پژوهشگران به دنبال یک هدف بلندپروازانهتر برای طراحی یک سیستم ترجمه کاملاً جدید مبتنیبر شبکههای عصبی بودند که متفاوت از آثار قبلی باشد. آنها به دنبال طراحی سیستمی بودند که به جای اینکه بخشی از یک سیستم ترجمه باشد، به تنهایی کار کند و بتواند مستقیماً ترجمه هدف را از جمله ی ورودی تولید کند.
همترازی
در سال 2013 رویکردی برای همتراز کردن یک نماد خروجی با یک نماد ورودی در زمینه ترکیب دستخط ارائه شد. در وظیفه ترکیب دستخط، از مدل خواسته میشود تا دستخط یک دنباله معین از کاراکترها را ایجاد کند. به این منظور، از ترکیبی از هستههای گاوسی برای محاسبه وزن حاشیهنویسی استفاده شد که در آن مکان، عرض و ضریب ترکیب هر هسته از یک مدل همتراز پیشبینی شده بود. تفاوت اصلی این مطالعه با رویکردی که در ادامه به بررسی آن میپردازیم، این است که در این پژوهش حالتهای وزن حاشیهنویسی تنها در یک جهت حرکت میکردند. در زمینه ترجمه ماشینی، این یک محدودیت شدید است، زیرا برای یک ترجمه صحیح گرامری(بهعنوان مثال، انگلیسی به آلمانی) به مرتبسازی مجدد نیاز دارد. از سوی دیگر، رویکرد این پژوهش مستلزم محاسبه وزن حاشیهنویسی برای هر کلمه در جمله مبدأ نسبت به هر کلمه در ترجمه است. این نکته منفی در ترجمهای که در آن بیشتر جملات ورودی و خروجی آن بین 15 تا 40 کلمه هستند، نمود زیادی ندارد اما ممکن است کاربرد این رویکرد را برای استفاده در وظایف دیگر محدود کند.
یادگیری همزمان همترازی و ترجمه
مدل توسعه یافته در این مقاله براساس مدل پایهی RNNencdec که درسال 2014 معرفی شد، ارائه شده است(برای آشنایی بیشتر با شبکهی RNNencdec به پست مربوط مراجعه کنید). معماری مدل توسعه یافته، شامل یک RNN دو طرفه بهعنوان کدگذار (بخش2. 3) و یک RNN ساده بهعنوان کدگشا است. در این مدل، کدگزار جملهی ورودی را به دنبالهای از بردارها نگاشت میکند. سپس کدگشا با استفاده از یک مکانیزم جستوجو، مرتبطترین بردارها به کلمه هدف را انتخاب کرده و در فرآیند ترجمه از آن استفاده میکند. در ادامه با جزئیات بیشتری به دو بخش کدگزار و کدگشا میپردازیم.
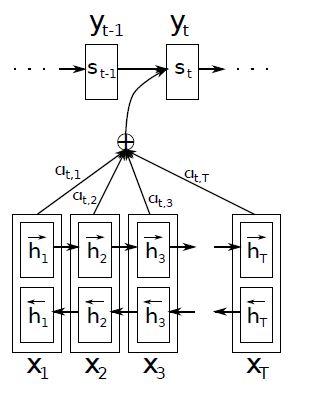
کدگذار: شبکه عصبی بازگشتی دوطرفه برای حاشیهنویسی دنبالهها
شبکهی RNN دنباله ورودی x را بهترتیب از اولین نماد xt تا آخرین نماد یعنی ![]() میخواند. اما پژوهشگران به دنبال این بودند تا حاشیهنویسی هر کلمه، نهتنها کلمات قبل بلکه کلمات بعدی را نیز خلاصه کند. از این رو، آنها یک شبکه عصبی بازگشتی دو طرفه (BiRNN) را بهکار گرفتند که در سال 2013 با موفقیت در تشخیص گفتار استفاده شده بود.
میخواند. اما پژوهشگران به دنبال این بودند تا حاشیهنویسی هر کلمه، نهتنها کلمات قبل بلکه کلمات بعدی را نیز خلاصه کند. از این رو، آنها یک شبکه عصبی بازگشتی دو طرفه (BiRNN) را بهکار گرفتند که در سال 2013 با موفقیت در تشخیص گفتار استفاده شده بود.
یک BiRNN از دو RNN به نام پیشرو و عقبرو تشکیل شدهاست. RNN پیشرو ![]() ، دنباله ورودی را بهترتیب خوانده (از x1 تا
، دنباله ورودی را بهترتیب خوانده (از x1 تا ![]() ) و دنبالهای از حالتهای پنهان پیشرو
) و دنبالهای از حالتهای پنهان پیشرو ![]() را محاسبه میکند. RNN عقبرو ، دنباله را بهصورت معکوس خوانده(از
را محاسبه میکند. RNN عقبرو ، دنباله را بهصورت معکوس خوانده(از ![]() تا x1) و دنبالهای از حالتهای پنهان عقبرو
تا x1) و دنبالهای از حالتهای پنهان عقبرو ![]() را میسازد. یک حاشیهنویسی برای هر کلمه xj، با الحاق حالت پنهان پیشرو
را میسازد. یک حاشیهنویسی برای هر کلمه xj، با الحاق حالت پنهان پیشرو ![]() و عقبرو
و عقبرو ![]() به یکدیگر بهصورت
به یکدیگر بهصورت ![]() حاصل میشود.
حاصل میشود.
به این ترتیب، حاشیهنویسی hj حاوی خلاصههایی هم از کلمات قبل و هم از کلمات بعدی است. با توجه به تمایل RNNها به بازنمایی بهتر ورودیهای جدید، حاشیهنویسی hj روی کلمات اطراف xj متمرکز خواهد شد. این دنباله ی حاشیهنویسی در مراحل بعدی در کدگشا و مدل همتراز، برای محاسبه بردار متنی استفاده میشود (معادله 3 در بخش2. 3). تصویر گرافیکی مدل پیشنهادی در شکل1 قابل مشاهدهاست.
کدگشا
کدگشا، کلمه هدف yt` را با توجه به بردار متنی C و تمام کلمات پیشبینیشده قبلی![]() ، تولید میکند. بهعبارت دیگر، کدگشا با تجزیه احتمال مشترک به شرطهای مرتبشده، احتمالی را بر روی ترجمه y تعریف میکند که در کدگشای پایه به شکل زیر فرمول میشود:
، تولید میکند. بهعبارت دیگر، کدگشا با تجزیه احتمال مشترک به شرطهای مرتبشده، احتمالی را بر روی ترجمه y تعریف میکند که در کدگشای پایه به شکل زیر فرمول میشود:
(1) ![]()
(2) ![]()
در این رابطه، si حالت پنهان RNN در زمان i است که توسط عبارت زیر محاسبه میشود:
![]()
لازم به ذکر است که برخلاف رویکرد کدگذار-کدگشا پایه، در اینجا بردار ci برای هر کلمه هدف yi بهصورت متمایز تعریف میشود.
بردار متنی ci به دنبالهای از حاشیهنویسیها ![]() که توسط کدگذار به جمله ورودی نگاشت شده، وابسته است. هر حاشیهنویسی hi حاوی اطلاعاتی در مورد کل دنباله ورودی با تمرکز بر روی بخشهای اطراف کلمه iام است. بردار متنی ci بهعنوان یک جمع وزندار از حاشیهنویسیهای hi به شکل زیر محاسبه میشود:
که توسط کدگذار به جمله ورودی نگاشت شده، وابسته است. هر حاشیهنویسی hi حاوی اطلاعاتی در مورد کل دنباله ورودی با تمرکز بر روی بخشهای اطراف کلمه iام است. بردار متنی ci بهعنوان یک جمع وزندار از حاشیهنویسیهای hi به شکل زیر محاسبه میشود:
(3) ![]()
وزن aij هر حاشیهنویسی hi بهصورت زیر فرمول میشود:
(4) 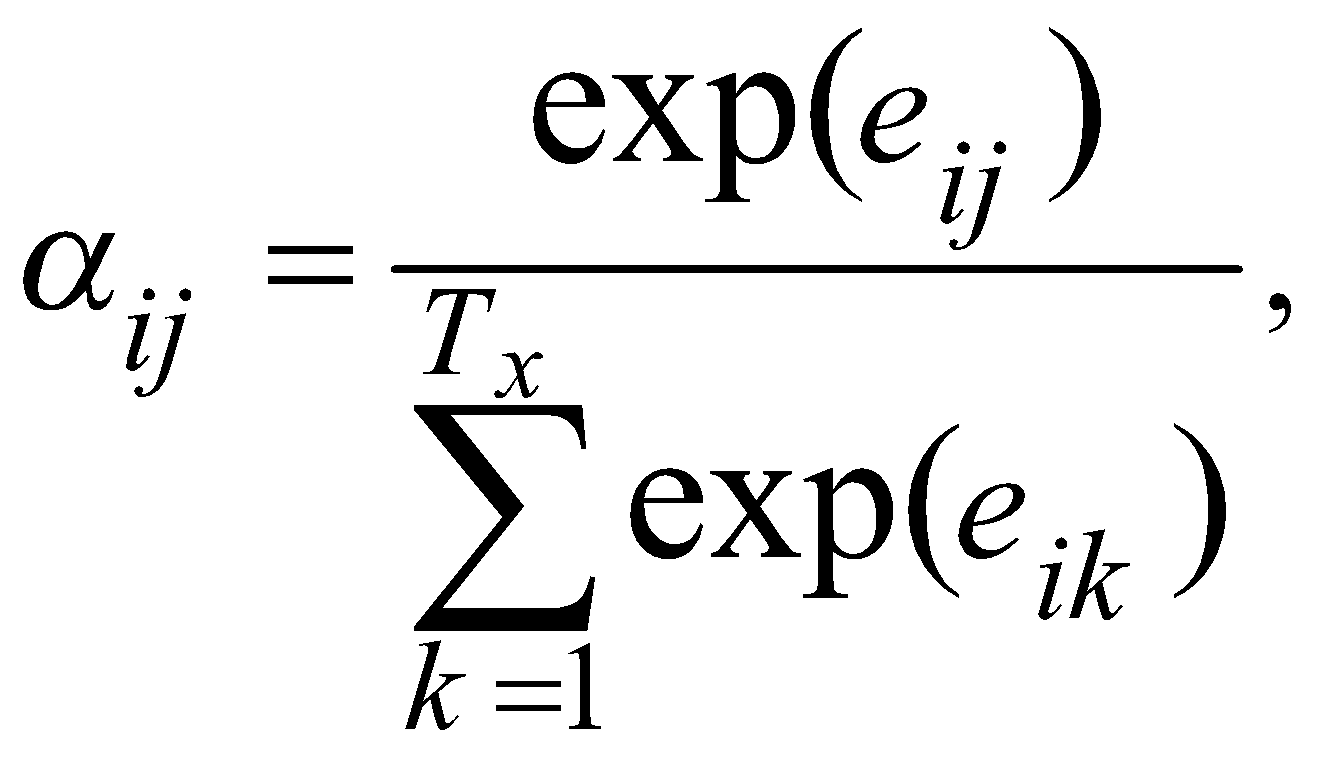
جایی که:
a بهعنوان مدل همترازی، به میزان مطابقت ورودیها در اطراف موقعیت مکانی j و خروجیها در موقعیت مکانی i امتیاز میدهد. این امتیاز براساس حالت پنهانRNN، یعنی Si-1 (درست قبل از انتشار yi در معادله 2) وj -امین حاشیهنویسی hj از جمله ورودی است.
مدل همترازی a بهعنوان یک شبکه عصبی روبهجلو، بهطور مشترک با سایر اجزای مدل، آموزش داده میشود. در ترجمه ماشینی سنتی، همترازی بهعنوان یک متغیر پنهان در نظر گرفته میشود. اما در این روش مدل همتراز، مستقیماً یک همترازی-نرم را محاسبه میکند. مزیت کلیدی استفاده از یک مدل همتراز نرم این است که میتوان از پسانتشار گرادیان برای آموزش همزمان مدل همتراز و مدل ترجمه استفاده کرد. با محاسبه مستقیم هم ترازی نرم و گنجاندن آن در فرآیند آموزش، مدل به شکل موثرتری همترازی کلمات را یاد گرفته و ترجمههای دقیقتری تولید میکند.
محاسبه جمع وزندار تمام حاشیهنویسیها را میتوان بهعنوان یک امید ریاضی برای حاشیهنویسی تفسیر کرد، که در آن امید ریاضی بر روی تمام همترازیهای ممکن محاسبه میشود. امید ریاضی حاشیهنویسی، محتملترین همترازی بین دنبالههای ورودی و خروجی را با توجه به توزیع احتمالات یادگیریشده نشان میدهد. فرض کنید احتمال اینکه کلمه هدف yi همتراز یا ترجمهشده کلمه مبدأ xj باشد، برابر با aij است. آنگاه، i-امین بردار متنی ci برابر است با امید ریاضی همه حاشیهنویسیها با احتمال aij.
احتمال aij یا انرژی مرتبط با آن eij، اهمیت حاشیهنویسی hi را نسبت به حالت پنهان قبلی Si-1 در تصمیمگیری برای حالت بعدی Si و تولید yi نشان میدهد. بهطور شهودی این پیادهسازی، مکانیزم توجه را در کدگشا اجرا میکند و کدگشا تصمیم میگیرد که به کدام یک از قسمتهای جمله مبدأ توجه کند. با دادن مکانیزم توجه به کدگشا، کدگذار از فشار فشردهسازی تمام اطلاعات جمله مبدأ در یک بردار بهطول ثابت رها میشود. در نتیجه، با این رویکرد جدید، اطلاعات میتوانند در دنبالهی بردارهای حاشیهنویسی پخش شده و توسط کدگشا بهطور انتخابی بازیابی شوند.
تنظیمات آزمایش
رویکرد پیشنهادی در ترجمه انگلیسی به فرانسوی ارزیابی شده است. به این منظور پژوهشگران از پیکرههای موازی دوزبانه ارائه شده توسط ACL WMT ’14.3 استفاده کردند. بهعنوان معیار مقایسه، آنها عملکرد مدل RNNencdec را نیز گزارش دادند. در این پژوهش برای هر دو مدل، از روشهای آموزشی یکسان و مجموعه دادههای مشابه استفاده شدهاست.
مجموعه داده
مجموعه داده WMT 14 شامل پیکرههای متن موازی انگلیسی-فرانسوی:
- یوروپال
- تفسیر اخبار
- اطلاعات مربوط به سازمان ملل
- دو مجموعه خزشدر وب
در مجموع 850 میلیون کلمه میباشد.
پژوهشگران با استفاده از روش انتخاب داده به کارگرفته شده در مقالهی چو، اندازه پیکره را به 348 میلیون کلمه کاهش دادند. برای این کار از هیچ داده تکزبانهای به جز پیکرههای موازی بالا، استفاده نشدهاست.
برای ایجاد مجموعه توسعه (اعتبارسنجی)، مجموعه news-test-2012 و news-test-2013 را با هم ادغام و مدلها را در مجموعه تست (news-test-2014) از WMT 14 ارزیابی کردند. این مجموعه تست شامل 3003 جمله است که در مجموعه آموزش وجود ندارد.
پس از یک توکنگذاری معمولی، پژوهشگران از لیست کوتاهِ 30هزار کلمه پرتکرار در هر زبان برای آموزش مدلهای خود استفاده کردند. کلمهای که در این لیست وجود نداشته باشد به یک توکن خاص ([UNK]) نگاشت میشود. علاوه بر این، در این مقاله هیچ پیشپردازش ویژه دیگری، مانند کوچک کردن حروف یا ریشهیابی کلمات بر روی دادهها اعمال نشدهاست.
مدلها
در این پژوهش عملکرد دو مدل پایهRNNencdec و مدل توسعه یافته RNNsearch بررسی شدهاست. پژوهشگران هر مدل را دو بار؛ ابتدا با جملات طولانی تا 30 کلمه (RNNencdec-30، RNNsearch-30) و سپس با جملات طولانیتر تا 50 کلمه (RNNencdec-50، RNNsearch-50) آموزش دادند.
کدگذار و کدگشا در مدل RNNencdec هر کدام دارای 1000 واحد پنهان هستند. کدگذار مدل RNNsearch شامل RNN پیشرو و عقبرو است که هر کدام 1000 واحد پنهان دارند. کدگشای مدل RNNsearch نیز دارای 1000 واحد پنهان است. در هر دو مدل، پژوهشگران از یک شبکه چندلایه با یک لایه پنهانmaxout برای محاسبه احتمال شرطی هر کلمه هدف استفاده کردند
این مقاله از یک الگوریتم نزولی گرادیان تصادفی (SGD) با استفاده از زیردسته همراه با نمونهبرداری تصادفی از دادهها با آدادلتا، برای آموزش هر مدل استفاده کردهاست. بهروزرسانی هر SGD با استفاده از زیردستهای با 80 جمله محاسبه شده و هر مدل تقریباً برای 5 روز آموزش دیده است.
پس از آموزش مدل، از جستوجوی بیم (اگر این موضوع برای شما جدید است یا آن را فراموش کردید، لطفا به انتهای پست "بررسی ویژگیهای ترجمه ماشینی مبتنیبر شبکههای عصبی با استفاده از روشهای کدگذار-کدگشا" مراجعه کنید) برای یافتن ترجمهای که احتمال شرطی را بیشینه میکند، استفاده شدهاست.
نتایج
در این بخش نتایج کمی و کیفی حاصل از این پژوهش را تجزیهوتحلیل میکنیم.
نتایج کمی
شکل 3، به مقایسه عملکرد ترجمه براساس امتیاز BLEU پرداخته است. مطابق جدول، در همه موارد، RNNsearch پیشنهادی از RNNencdec بهتر عمل میکند. مهمتر از آن، زمانیکه تنها جملات دارای کلمات شناختهشده در نظر گرفته شد، RNNsearch بهخوبی سیستم ترجمه مبتنیبر عبارت (Moses) عمل کرد. این یک دستاورد قابلتوجه برای این مدل است، زیرا Moses علاوه بر پیکرههای موازی که برای آموزش RNNsearch و RNNencdec استفاده شده، با یک پیکره تک زبانه جداگانه (418 میلیون کلمه) نیز آموزش دیده است.
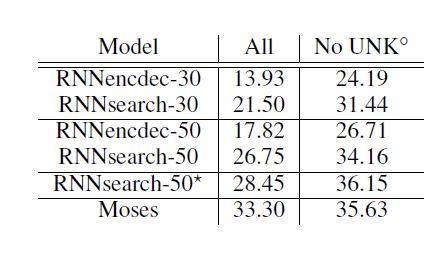
در شکل3، ستونهای دوم و سوم بهترتیب امتیازهای مربوط به تمام جملات و جملات بدون کلمه ناشناخته در ترجمههای هدف را نشان میدهند. بهتر است بدانیم که زمان آموزش مدل ![]() بسیار طولانیتر از سایر مدلها بوده است. در ستون آخر، زمانیکه فقط جملات بدون کلمات مجهول ارزیابی شدند، پژوهشگران به مدلها اجازه تولید توکنهای [UNK] را ندادند.
بسیار طولانیتر از سایر مدلها بوده است. در ستون آخر، زمانیکه فقط جملات بدون کلمات مجهول ارزیابی شدند، پژوهشگران به مدلها اجازه تولید توکنهای [UNK] را ندادند.
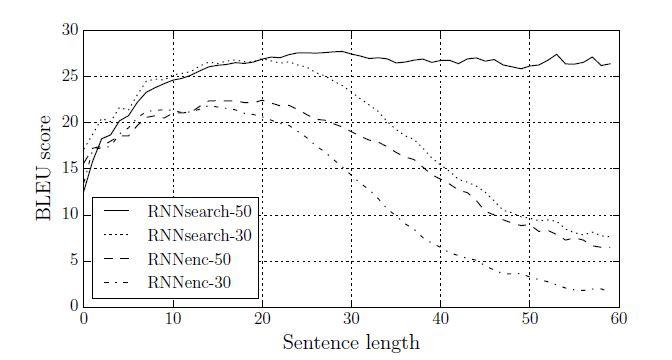
یکی از انگیزههای ارائه رویکرد جدید، ثابت بودن اندازهی بردار متنی در رویکرد کدگذار-کدگشای پایه بود. براساس حدسیات پژوهشگران، این محدودیت میتوانست عامل عملکرد ضعیف رویکرد کدگذار-کدگشای پایه بر روی جملات طولانی باشد. مطابق شکل 2، با افزایش طول جملات، عملکرد RNNencdec بهطور چشمگیری کاهش مییابد. از سوی دیگر، هر دو مدل RNNsearch-30 و RNNsearch-50 نسبت به طول جملات، مقاومت بیشتری دارند. بهویژه، مدل RNNsearch-50 حتی با جملاتی به طول 50 یا بیشتر نیز هیچ افت عملکردی نشان نمیدهد. با توجه به این واقعیت که RNNsearch-30 حتی از RNNencdec-50 عملکرد بهتری دارد، برتری مدل پیشنهادی نسبت به رویکرد کدگذار-کدگشا پایه تأیید میشود (جدول 1 را ببینید).
نتایج کیفی
در این بخش نتایج کیفی مدل را مورد بررسی قرار میدهیم.
همترازی
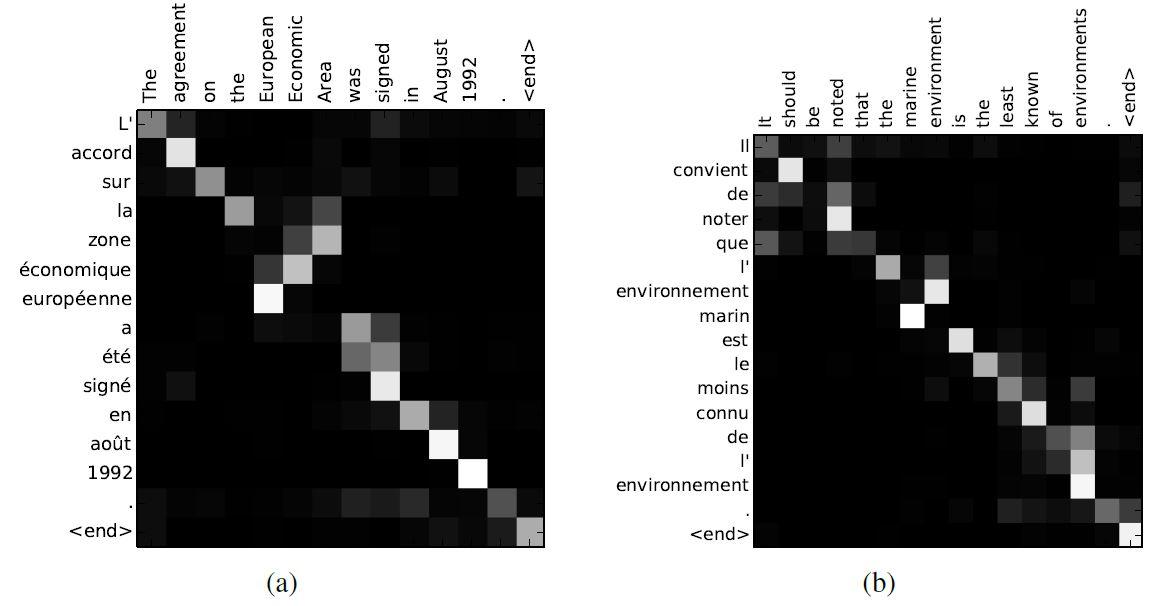
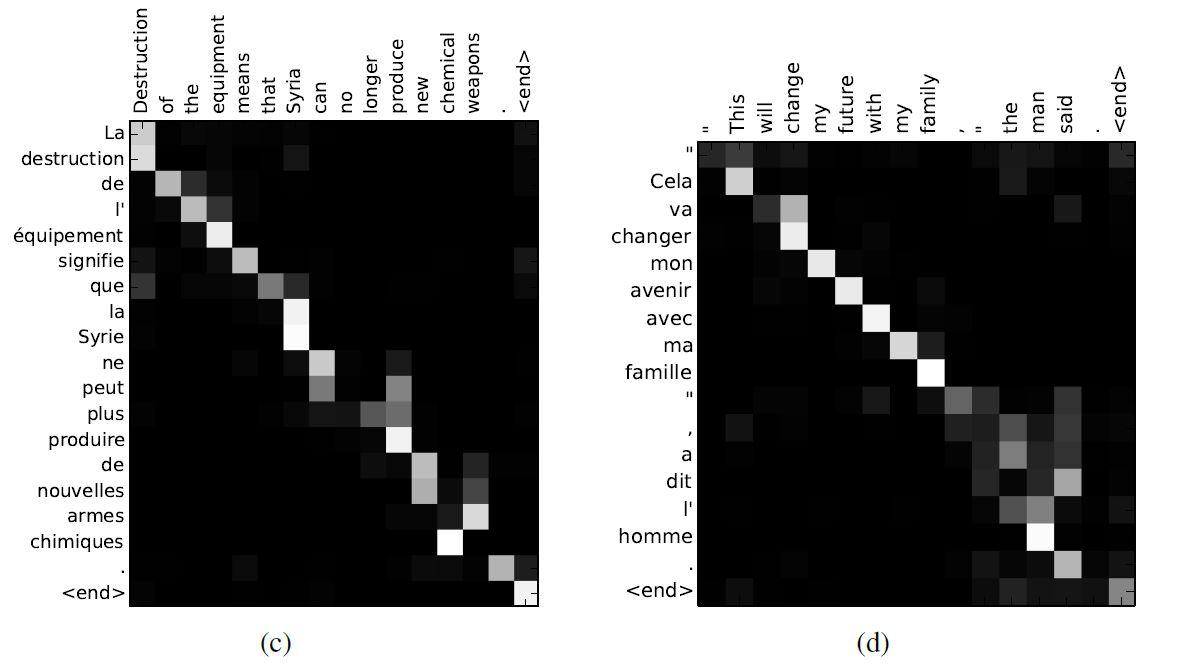
برای بررسی همترازی-نرم بین کلمات ترجمه شده و جمله مبدأ یک روش بصری ارائه شده است. این کار از طریق تجسمسازی وزنهای حاشیهنویسی aij در معادله 4 انجام شده و در شکل 4 قابل مشاهده است. در هر نمودار، هر ردیف از هر ماتریس، وزن حاشیهنویسی متناظر را نشان میدهد. براساس شکل 4، بهصورت شهودی میتوان بررسی کرد که مدل به کدام موقعیتهای مکانیِ جمله مبدأ در هنگام تولید کلمه هدف بیشتر توجه کرده است.
از همترازیهای شکل 4 میتوان فهمید که همترازی کلمات بین زبان انگلیسی و فرانسوی تا حد زیادی یکنواخت است. با این حال، تعدادی از همترازیهای غیرمعمول و غیریکنواخت نیز دیده میشود. ترتیب صفتها و اسمها در فرانسوی و انگلیسی معمولاً با هم متفاوت است(شکل 4 (آ)). با توجه به این مثال، مدل پیشنهادی عبارت [European Economic Area] را بهدرستی به [zone´economique europ´een] ترجمه کردهاست. در این نمونه، RNNsearch توانست به درستی [zone] را با [Area] همتراز کرده، از روی دو کلمه ([European] و [Economic]) بگذرد، سپس با نگاه به یک کلمه عقبتر، کل عبارت [zone ´economique europ´eenne] را کامل کند.
قدرت همترازی-نرم، در مقابل همترازی-سخت، در شکل 4 (د) مشهود است. در واقع تفاوت اصلی بین همترازی-نرم و همترازی-سخت در ترجمه، روش تطبیق لغات ورودی با لغات خروجی است. همترازی-سخت تنها از یک تطبیق منحصربهفرد برای هر کلمه استفاده میکند، اما همترازی-نرم برای توجه منعطفتر به کلمات، از بردارهای وزنی استفاده میکند. عبارت مبدأ [the man] را در نظر بگیرید که به [l’homme] ترجمه شدهاست. هر همترازی-سخت [the] را به [l'] و [man] را به [homme] نگاشت میکند. این برای ترجمه مفید نیست، زیرا باید کلمه بعد از [the] را در نیز نظر گرفت تا مشخص شود که این کلمه باید به کدام یک از [le] ، [la] ، [les] یا [l’] ترجمه شود. همترازی-نرم پیشنهادی در این مقاله با اجازه دادن به مدل برای درنظر گرفتن هر دو کلمه [the] و [man] این مسئله را بهطور طبیعی حل کردهاست. در این مثال، میبینیم که مدل به درستی [the] را به [l’] ترجمه کرد. رفتارهای مشابه در تمام موارد ارائهشده در شکل 4 قابل مشاهده است.
'در روش همترازی-سخت، هر کلمه هدف به یک کلمه مشخص در جمله مبدأ نگاشت میشود. اما اگر عبارات مبدأ و هدف طول متفاوتی داشته باشند، روش همترازی-سخت به مشکل برمیخورد. در این حالت، برخی از کلمات خروجی به کلمات ورودی متناظر نشده و به ([NULL]) نگاشت میشوند. این نگاشت به ([NULL]) نقاط ضعفی را در ترجمه ایجاد میکند و ممکن است ترجمه ناصحیحی را به وجود آورد. در مقابل، روش همترازی-نرم از بردارهای وزنی استفاده میکند که نشان میدهد هرکلمه در هرمرحله، چقدر باید موردتوجه قرار گیرد. این رویکرد به مدل کمک میکند تا با طولهای متفاوت عبارات مبدأ و هدف مقابله کند. برای عبارات مبدأ که طولشان از عبارات هدف کمتر است، وزنهای بیشتری به لغات مربوط به عبارات هدف داده میشود و برعکس. این روش بهعنوان یک مزیت اضافی برای همترازی-نرم، باعث ایجاد همترازی متغیرتر و مناسبتر بین لغات ورودی و خروجی بدون نگاشت لغات به ([NULL]) میشود.
جملات طولانی
همانطور که در شکل 2 بهوضوح قابل مشاهده است، مدل پیشنهادی RNNsearch در ترجمه جملات طولانی بسیار بهتر از مدل RNNencdec است. این مساله احتمالاً به این دلیل است که RNNsearch نیازی به کدگذاری یک جمله طولانی به یک بردار با طول ثابت ندارد، بلکه فقط به کدگذاری دقیق بخشهایی از جمله ورودی که یک کلمه خاص را احاطه کردهاست، نیاز دارد.
بهعنوان مثال، این جمله مبدأ را از مجموعه تست در نظر بگیرید:
An admitting privilege is the right of a doctor to admit a patient to a hospital or a medical centre to carry out a diagnosis or a procedure, based on his status as a health care worker at a hospital
RNNencdec-50 این جمله را به این صورت ترجمه کردهاست:
Un privil`ege d’admission est le droit d’un m´edecin de reconnaˆıtre un patient `a l’hˆopital ou un centre m´edical d’un diagnostic ou de prendre un diagnostic en fonction de son ´etat de sant´e.
RNNencdec-50 جمله مبدأ را تا [a medical center] بهدرستی ترجمه کردهاست. با این حال، از یک جایی به بعد (خط کشیده شده)، از معنای اصلی جمله مبدأ منحرف شده است. بهعنوان مثال، [based on his status as a health care worker at a hospital] در جمله منبع با [en fonction de son ´etat de sant´e] («براساس وضعیت سلامت او») جایگزین شدهاست. از سوی دیگر، RNNsearch-50 ترجمه صحیح زیر را تولید و بدون حذف هیچ جزئیاتی، معنای کامل جمله ورودی را حفظ کرده است:
Un privil`ege d’admission est le droit d’un m´edecin d’admettre un patient `a un hˆopital ou un centre m´edical pour effectuer un diagnostic ou une proc´edure, selon son statut de travailleur des soins de sant´e `a l’hˆopital.
با ادغام نتایج کمی و مشاهدات کیفی، فرضیه این پژوهش تأیید میشود که معماری RNNsearch نسبت به مدل پایه RNNencdec، ترجمه بسیار مطمئنتری برای جملات طولانی ایجاد میکند.
نتیجهگیری
در رویکرد مرسوم کدگذار-کدگشا در ترجمه ماشینی عصبی، جمله ورودی به یک بردار با طول ثابت کدگذاری شده و ترجمه با کدگشایی این بردار تولید میشود. این رویکرد در ترجمه جملات طولانی به مشکل برمیخورد. پژوهشگران باور داشتند که استفاده از یک بردار متنی با طول ثابت عامل مشکلساز این رویکرد است. در نتیجه، آنها با پیشنهاد یک معماری جدید، راهحلی برای این مشکل ارائه دادند.
پژوهشگران با حذف محدودیت ثابت بودن طول بردار بازنمایی، به مدل اجازه دادند که جملهی ورودی را به شکل مجموعهای از بردارها حاشیهنویسی کند. به این ترتیب مدل قادر خواهد بود که در جملهی ورودی به جستوجو-نرم بپردازد و فقط بر روی اطلاعات مرتبط با تولید کلمه هدف متمرکز شود. توسعهی بردار بازنمایی، باعث بهبود عملکرد ترجمه بهخصوص در جملات طولانی شد.
مدل پیشنهادی که RNNsearch نامیده شده است، در ترجمه انگلیسی به فرانسوی مورد آزمایش قرار گرفت. براساس نتایج آزمایش، RNNsearch بهطور قابل توجهی از مدل پایهی RNNencdec بهتر عمل کرده و نسبت به طول جمله مبدأ بسیار مقاوم بود. مطابق با نتایج تجزیهوتحلیل کیفی، با بررسی همترازیهای-نرم تولیدشده توسط RNNsearch، مدل توانست به درستی هر کلمه هدف را با کلمات یا حاشیهنویسیهای متناظر با آن در جمله مبدأ همتراز کند. بهعنوان یک نتیجه قابل توجه، رویکرد پیشنهادی توانست به عملکرد ترجمه قابل قبولی در مقایسه با مدل SMT مبتنیبر عبارت دست یابد.

نظرات