retnet (شبکه نگهدارنده): جانشین ترنسفورمر برای مدلهای زبانی بزرگ
ترجمه مریم سادات هاشمی از مقاله Retentive Network: A Successor to Transformer for Large Language Models

-
مقدمه
ظهور معماری ترنسفورمرها نقطۀ عطف مهمی در توسعۀ مدلهای زبانی بزرگ بود که برای غلبه بر محدودیتهای شبکههای عصبی بازگشتی (RNN) معرفی شد. همانطور که از نام RNNها پیداست، دنبالۀ ورودی در این مدلها بهصورت بازگشتی، یعنی یکی پس از دیگری، پردازش میشود. به عبارت دیگر، پردازش یک ورودی در یک زمان معین به حالت پنهان در مرحلۀ زمانی قبلی بستگی دارد و تا زمانی که تمام مراحل قبلی پردازش نشده باشند، نمیتوان آن را بهصورت موازی محاسبه کرد. این امر باعث کاهش چشمگیر سرعت آموزش مدلهای RNN میشود.
در مقابل، ترنسفورمرها از مکانیزم توجهبهخود استفاده میکنند تا امکان محاسبۀ خروجیها در هر مرحله زمانی با استفاده از ماتریسهای Q، K و V بهصورت موازی فراهم شود. با این حال، مکانیزم توجهبهخود، که در مرحله آموزش به موازیسازی عملیات بر روی GPUها کمک میکند، در زمان استنتاج به یک چالش بزرگ تبدیل میشود. در این مرحله، برای هر توکن باید امتیاز توجه به سایر توکنها در دنبالۀ ورودی محاسبه شود. این فرایند به این معناست که برای دنبالهای به طول N، باید N محاسبه انجام شود که به هزینۀ محاسباتی خطی O(N) منجر میگردد. علاوه بر این، برای نگهداری امتیاز توجه بین توکنها به یک ماتریس NxN نیاز است که باعث پیچیدگی حافظه از مرتبه دو O(N2) میشود. در نتیجه، با افزایش طول دنباله ورودی، ترنسفورمرها نیاز به حافظه GPU بیشتری دارند، تأخیر بالاتری ایجاد میکنند و سرعت استنتاج را بهشدت کاهش میدهند. این مسائل ترکیبی از چالشها را ایجاد میکنند که نمیتوان آنها را نادیده گرفت.
از این رو، پژوهشهای زیادی برای پیدا کردن یک معماری جدید انجام شدهاست که همزمان سه ویژگی آموزش موازی، استنتاج کمهزینه و عملکرد قوی را داشته باشد. اما دستیابی به این سه ویژگی در یک مدل بهطور همزمان بسیار چالشبرانگیز است. این موضوع در شکل 1 بهعنوان «مثلث غیرممکن» نشان داده شدهاست که روشهای موجود بر روی اضلاع این مثلث قرار گرفتهاند و نشان میدهد که هر روش تنها دو ویژگی رأس مجاور خود را شامل میشود و ویژگی رأس سوم را ندارد.
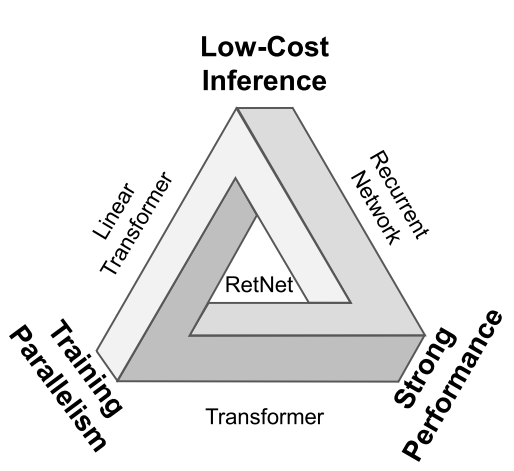
شکل 1: نمایی از مثلث غیرممکن.
اما در سال 2023 محققان مایکروسافت مدل RetNet را پیشنهاد دادند و مدعی هستند که مدل RetNet بر مثلث غیرممکن غلبه میکند. مدل RetNet توانست بهطور همزمان به هر سه قابلیت آموزش موازی، استنتاج کمهزینه و عملکرد قوی دست یابد. سنگ بنای موفقیت مدل RetNet مکانیزم نگهداری چندمقیاسی (MSR) است که جایگزین مکانیزم توجه چندسر در ترنسفورمر میشود و از سه پارادایم محاسباتی بازنمایی موازی، بازنمایی بازگشتی و بازنمایی بازگشتی تکهای تشکیل شدهاست.
بازنمایی موازی امکان آموزش موازی مدل را فراهم میکند و بازنمایی بازگشتی، استنتاج کارآمد (O(1)) از نظر حافظه و محاسبات را ارائه میدهد. در نهایت بازنمایی بازگشتی تکهای، مدلسازی دنبالههای طولانی را بهصورت مؤثر انجام میدهد. در بخشهای بعدی این مقاله، بهطور عمیقتر و جزئیتر به معماری RetNet، مکانیزم نگهداری چندمقیاسی (MSR) و نتایج آزمایشهای انجامشده بر روی RetNet خواهیم پرداخت.
-
شبکۀ نگهدارنده چیست؟
معماری مدل RetNet مشابه معماری ترنسفورمر است. این مدل از L لایه مشابه به هم ساخته شده که در هر لایه دو ماژول نگهداری چندمقیاسی (MSR) و شبکۀ روبهجلو (FFN) وجود دارد. علاوه بر این، هر لایه دارای اتصال باقیمانده و لایۀ پیشنرمالسازی است. ماژول MSR، مدل RetNet را از ترنسفورمر متمایز میکند یعنی با جایگزینی این ماژول با توجه چندسر، همان مدل ترنسفورمر ایجاد میشود.
در مدل RetNet هر توکن در دنباله ورودی ![]() با استفاده از لایه تعبیه کلمات به یک بردار تبدیل
میشود. از قرار گرفتن این بردارها در کنار هم ماتریس
با استفاده از لایه تعبیه کلمات به یک بردار تبدیل
میشود. از قرار گرفتن این بردارها در کنار هم ماتریس ![]() به دست میآید و بهعنوان وروی به مدل RetNet داده میشود. بنابراین، در هر لایه از
مدل RetNet، ماتریس
به دست میآید و بهعنوان وروی به مدل RetNet داده میشود. بنابراین، در هر لایه از
مدل RetNet، ماتریس ![]() با عبور از ماژول MSR و FFN ماتریس خروجی
با عبور از ماژول MSR و FFN ماتریس خروجی![]() را تولید میکند که ورودی لایه بعدی خواهد بود:
را تولید میکند که ورودی لایه بعدی خواهد بود:
![]()
در عبارت ، LN نشاندهنده لایۀ نرمالسازی است که بر روی ورودی هر دو ماژول اعمال میشود. علاوه بر این، برای پیادهسازی اتصال باقیمانده در هر ماژول، ورودی آن با خروجی ماژولها جمع میشود. ماژول FFN بهصورت زیر محاسبه میشود که مشابه ترنسفورمر است:
![]()
در عبارت ، ![]() و
و ![]() ماتریسهایی هستند که باید پارامترهای آن در طول آموزش یاد گرفته شود. جزئیات
محاسبات در ماژول MSR را در بخش بعد بررسی خواهیم کرد.
ماتریسهایی هستند که باید پارامترهای آن در طول آموزش یاد گرفته شود. جزئیات
محاسبات در ماژول MSR را در بخش بعد بررسی خواهیم کرد.
-
مکانیزم نگهداری
در این بخش جزئیات مکانیزم نگهداری در ماژول MSR را معرفی میکنیم که میتوان محاسبات مربوط به آن را هم بهصورت بازگشتی و هم بهصورت موازی بیان کرد. به دلیل همین قابلیت است که میتوانیم مدل RetNet را مانند ترنسفورمر بهصورت موازی آموزش دهیم و در زمان استنتاج از حالت بازگشتی آن مانند RNNها استفاده کنیم.
همانطور که اشاره کردیم، دنباله ورودی بعد از کدگذاری به ماتریس ![]() تبدیل میشود. سپس هر سطر از این ماتریس، که بردار تعبیۀ هر توکن از دنبالۀ ورودی است، به
یک بردار تکبعدی تبدیل میشود:
تبدیل میشود. سپس هر سطر از این ماتریس، که بردار تعبیۀ هر توکن از دنبالۀ ورودی است، به
یک بردار تکبعدی تبدیل میشود:
![]()
که در آن n نشاندهنده موقعیت در دنباله است. در ادامه میخواهیم با در
نظر گرفتن مدلسازی دنبالهای، که هدف آن تولید خروجی بعدی با استفاده از حالتهای
قبلی است، خروجی ![]() را از ورودی
را از ورودی ![]() و حالت
و حالت ![]() تولید کنیم:
تولید کنیم:
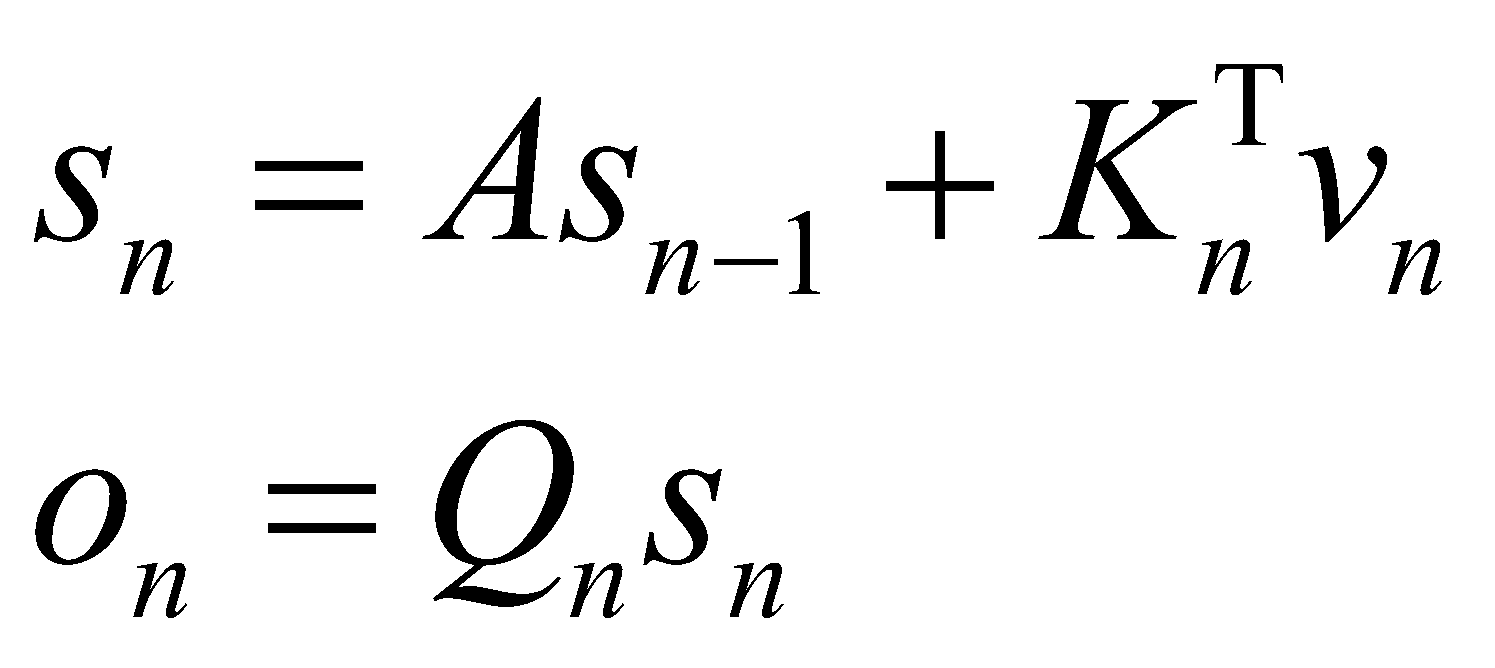
که در آن ![]() است. در عبارت
خاصیت اتورگرسیو را مشاهده میکنیم که
حالت
است. در عبارت
خاصیت اتورگرسیو را مشاهده میکنیم که
حالت ![]() به حالت قبلی
به حالت قبلی ![]() وابسته است. هر حالت جدید ترکیب خطی از ضریبی از حالت قبلی
(
وابسته است. هر حالت جدید ترکیب خطی از ضریبی از حالت قبلی
(![]() ) و ضرب نقطهای ورودی و کلید (
) و ضرب نقطهای ورودی و کلید (![]() ) است. عبارت
) است. عبارت ![]() یک عبارت بازگشتی است که میتوانیم آن را باز کنیم و بهصورت جمع بنویسیم:
یک عبارت بازگشتی است که میتوانیم آن را باز کنیم و بهصورت جمع بنویسیم:
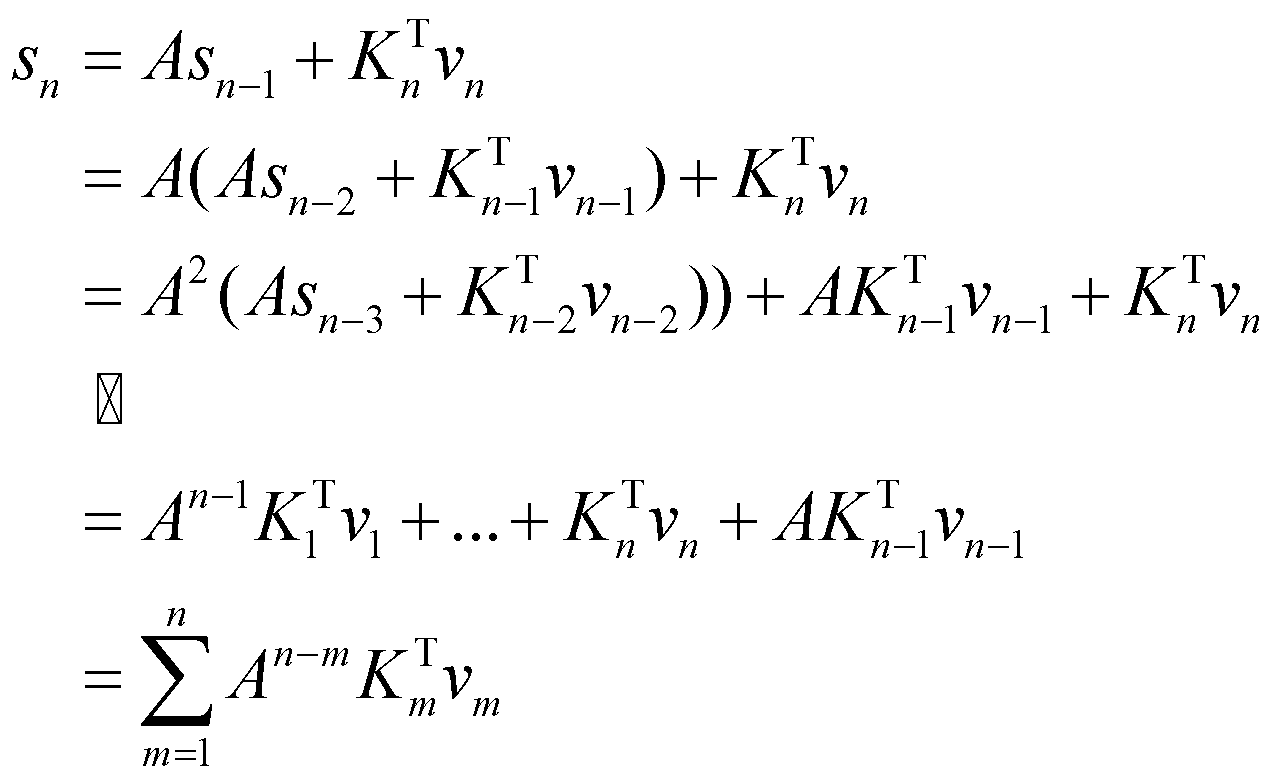
حال اگر عبارت را در جمله دوم عبارت جایگزین کنیم، خواهیم داشت:
![]()
نکتۀ حائز اهمیت در عبارت این است که ماتریس وزن A به توان n-m رسیدهاست و نشاندهنده فاصله بین توکن فعلی و تمام توکنهای قبلی است. در ادامه نشان خواهیم داد که ماتریس A یک ماتریس تعبیه موقعیتی است.
تا به اینجا، از فرمول مدلسازی دنبالهای شروع کردیم و به عبارت رسیدیم که برای محاسبه آن به سه ماتریس Q، K و A نیاز است. در ادامه، این سه ماتریس را به گونهای تعریف میکنیم که فرمول مدلسازی دنبالهای را بتوان بهصورت موازی محاسبه کرد.
ماتریس Q و K بهصورت زیر تعریف میشوند که محتوای ورودی در این ماتریسها گنجانده میشود و اصطلاحاً به آنها آگاه به محتوا میگویند:
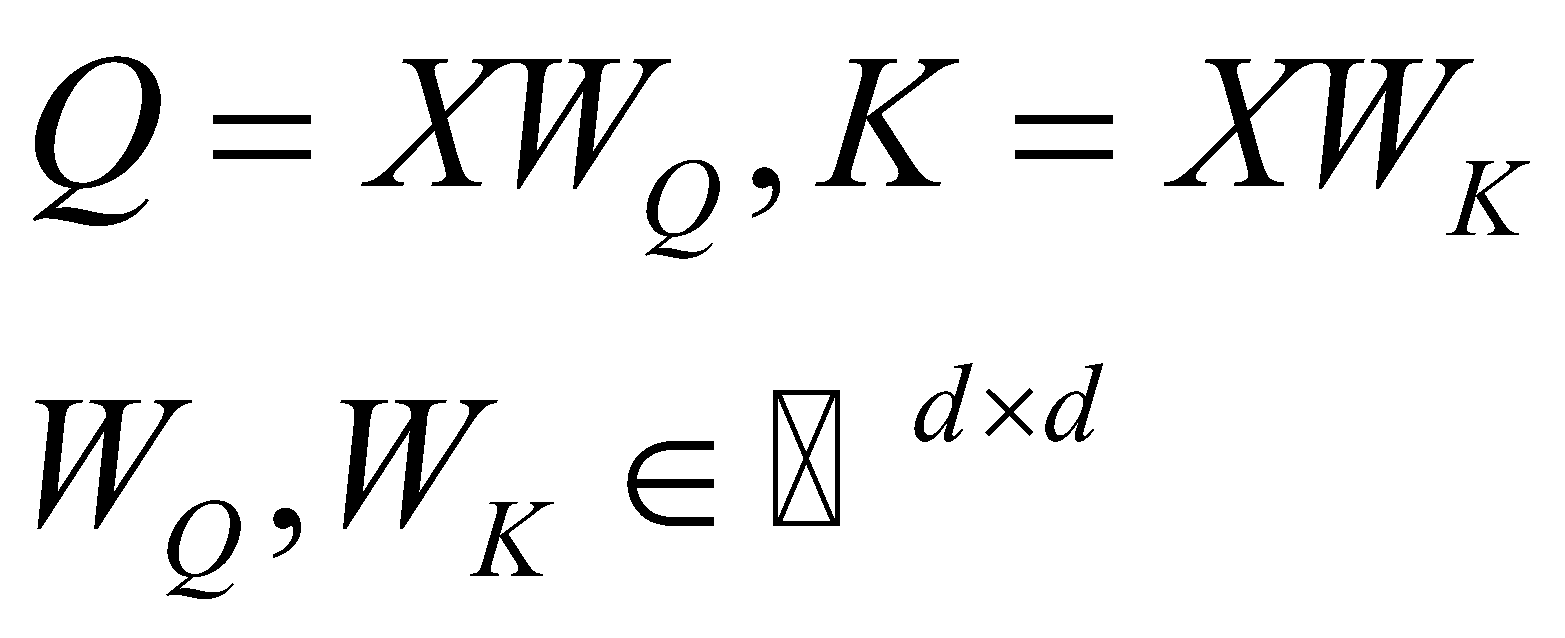
قبل از اینکه ماتریس A را معرفی کنیم باید به این نکته توجه کنیم که ماتریس A در عبارت به توان n-m میرسد. از طرفی میدانیم که برای به توان رساندن ماتریسهای قطری، کافی است تکتک درایههای قطر اصلی را به توان برسانیم. بنابراین برای سادگی در انجام محاسبات، لازم است که ماتریس A را قطری کنیم:
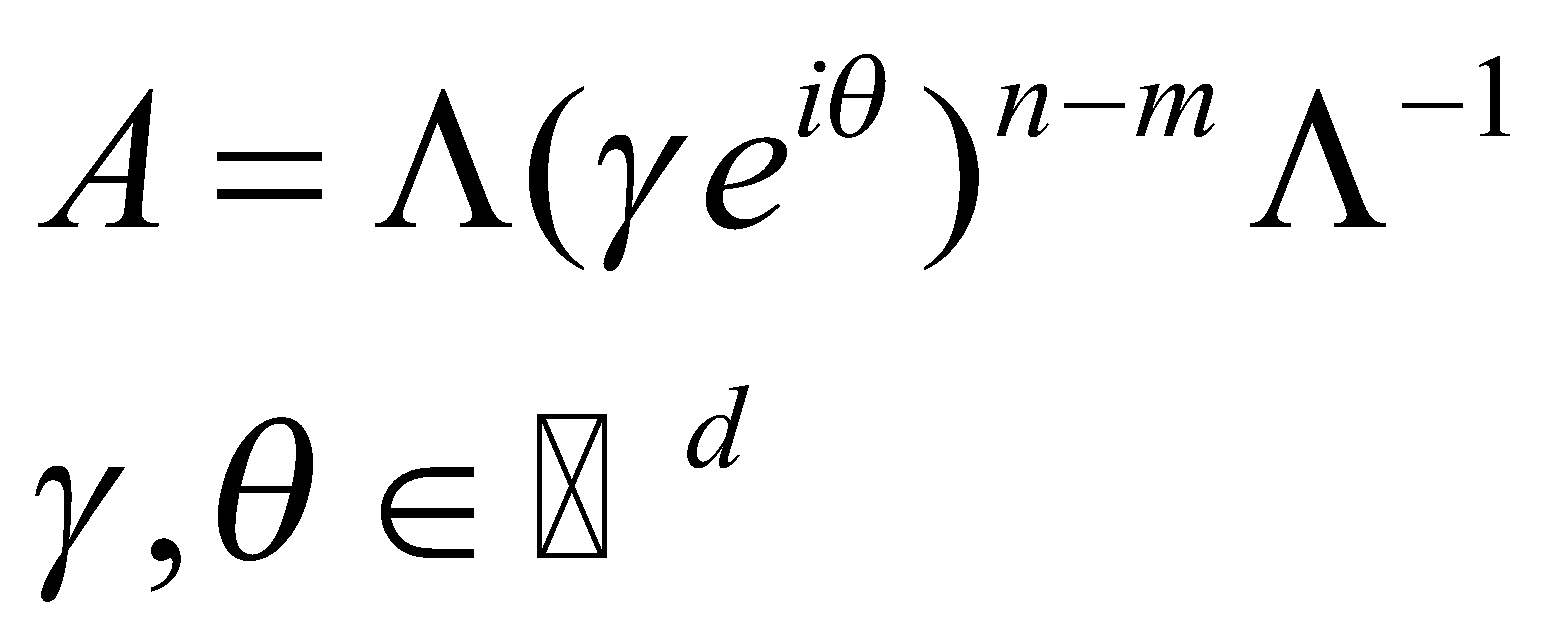
سپس، عبارت را در عبارت جایگزین میکنیم و برای سادگی محاسبات، ماتریس ![]() را در دل ماتریسهای قابلیادگیری
را در دل ماتریسهای قابلیادگیری ![]() و
و ![]() قرار میدهیم:
قرار میدهیم:
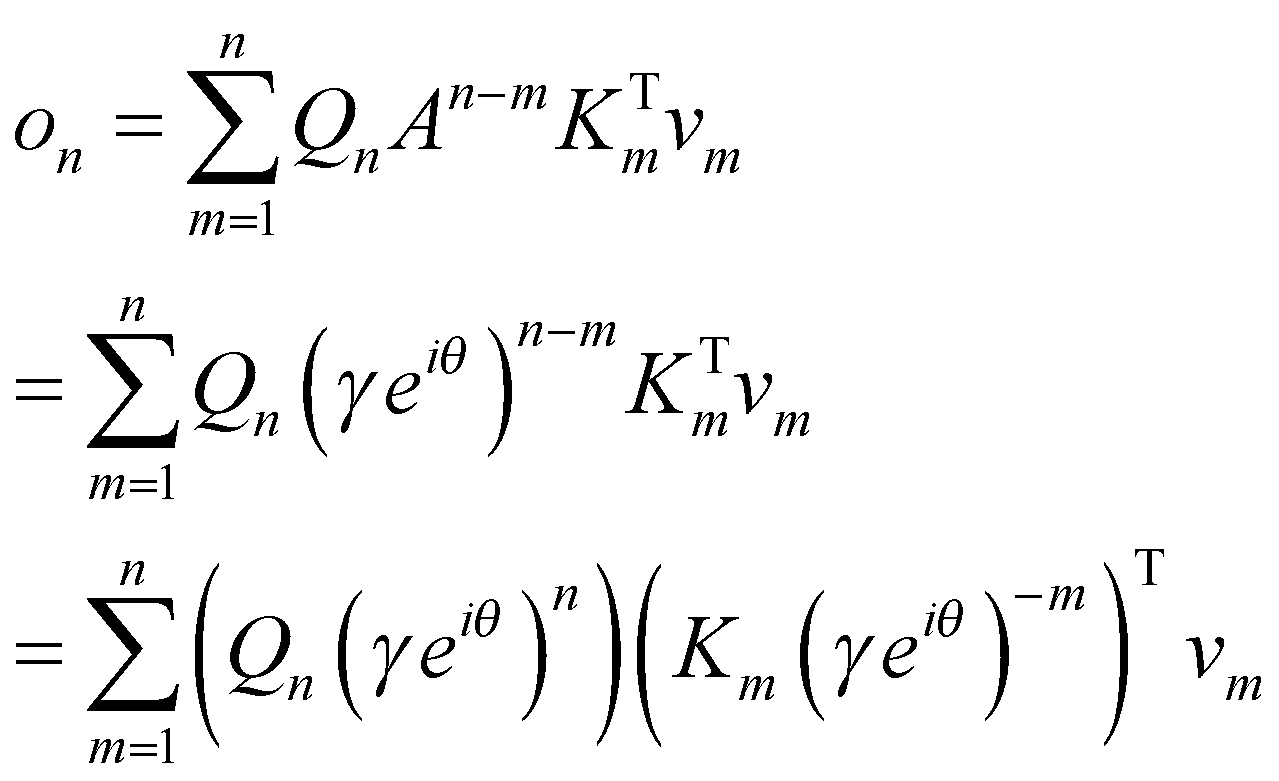
در عبارت ، ![]() و
و ![]() بهعنوان xPos شناخته میشوند که نوعی
تعبیه موقعیت نسبی پیشنهادشده برای ترنسفورمر است. از آنجایی که
بهعنوان xPos شناخته میشوند که نوعی
تعبیه موقعیت نسبی پیشنهادشده برای ترنسفورمر است. از آنجایی که ![]() یک عدد است، عبارت را میتوانیم سادهتر بنویسیم:
یک عدد است، عبارت را میتوانیم سادهتر بنویسیم:
![]()
که در آن ![]() ترانهادۀ مزدوج است. عبارت بهراحتی قابل
موازیسازی است که در بخش بعد آن را کامل توضیح خواهیم داد. اما قبل از پرداختن به این موضوع، میخواهیم مکانیزم
توجهبهخود را با مکانیزم نگهداری مقایسه کنیم. بهعنوان یادآوری، محاسبات در مکانیزم توجهبهخود بهصورت زیر
است:
ترانهادۀ مزدوج است. عبارت بهراحتی قابل
موازیسازی است که در بخش بعد آن را کامل توضیح خواهیم داد. اما قبل از پرداختن به این موضوع، میخواهیم مکانیزم
توجهبهخود را با مکانیزم نگهداری مقایسه کنیم. بهعنوان یادآوری، محاسبات در مکانیزم توجهبهخود بهصورت زیر
است:
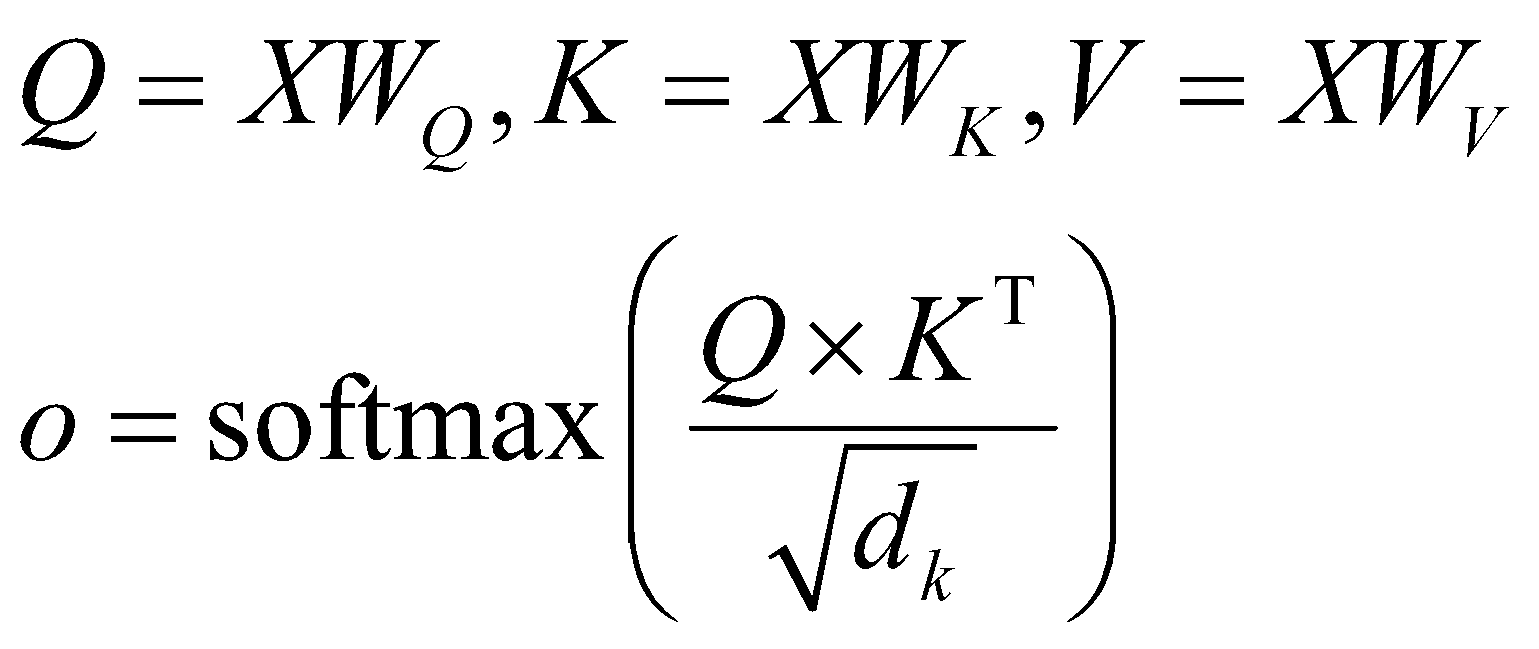
از طرفی دیگر در حین محاسبه مکانیزم نگهداری عبارت زیر به دست آمد:
![]()
به وضوح میبینیم که عبارت با کمی تغییر بسیار شبیه به عبارت است. از آنجایی که ماتریس A را میتوان تعبیه موقعیتی تلقی کرد میتوانیم بگوییم که مدل RetNet ، تابع Softmax در مکانیزم توجهبهخود را با ماتریس تعبیه موقعیتی جایگزین میکند. این نکته با سادهسازی عبارت در بخش بعد بیشتر مشخص میگردد.
-
بازنمایی موازی مکانیزم نگهداری
همانطور که قبلاً اشاره کردیم، میتوانیم عبارت را به شکل سادهتری بیان کنیم تا مکانیزم نگهداری به شکل موازی بر روی GPU آموزش داده شود:
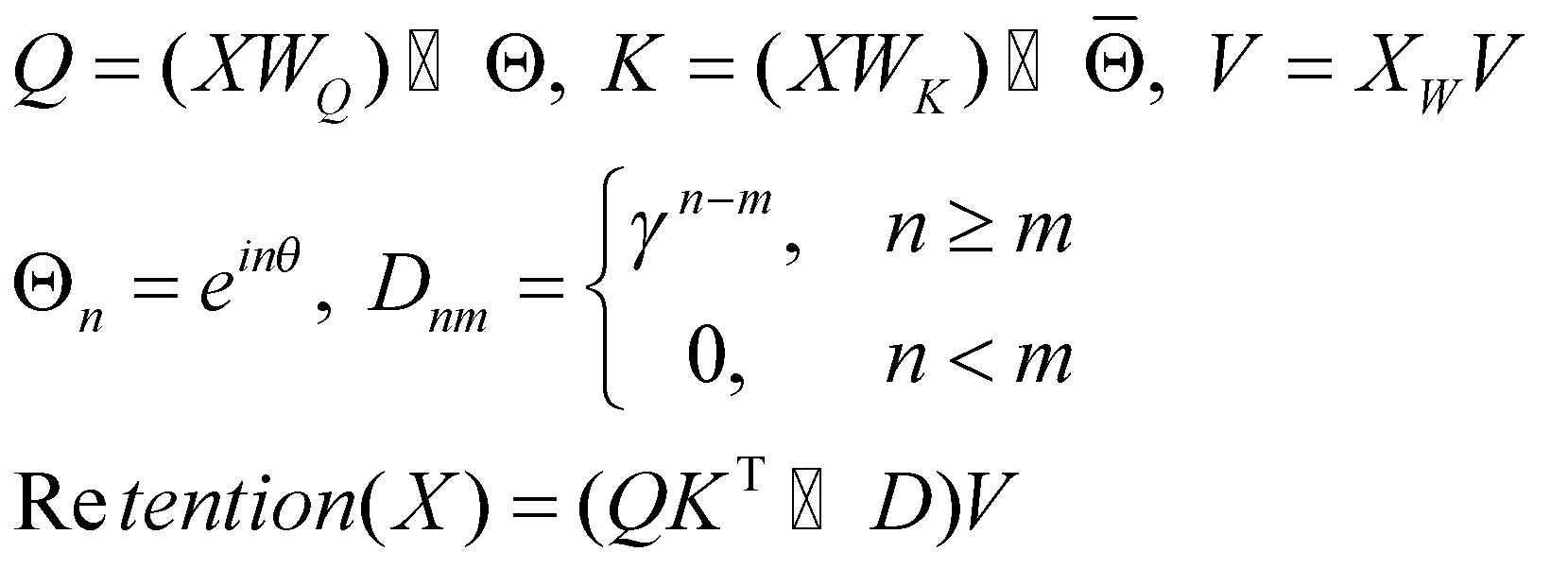
در عبارت ![]() مزدوج مختلط Θ است و
مزدوج مختلط Θ است و ![]() نشاندهندۀ ضرب هادامار یا ضرب درایهای ماتریس است.
ماتریس
نشاندهندۀ ضرب هادامار یا ضرب درایهای ماتریس است.
ماتریس![]() دو کار را همزمان انجام میدهد: مانع از توجه به عناصر آینده در مدل میشود
(پوشاندن علّی) و اهمیت عناصر نزدیک به موقعیت فعلی را افزایش داده و اثر
عناصر دورتر را کاهش میدهد (کاهش نمایی).
دو کار را همزمان انجام میدهد: مانع از توجه به عناصر آینده در مدل میشود
(پوشاندن علّی) و اهمیت عناصر نزدیک به موقعیت فعلی را افزایش داده و اثر
عناصر دورتر را کاهش میدهد (کاهش نمایی).
ماسک کردن علّی تکنیکی است که برای جلوگیری از توجه مدل به عناصر آینده در طول محاسبات استفاده میشود؛ زیرا در مدلسازی دنبالهای، اغلب میخواهیم عنصر بعدی را، براساس عناصری که قبل از آن آمدهاست، پیشبینی کنیم و نمیخواهیم مدل از اطلاعات عناصر آینده استفاده کند؛ چون آنها در طول پیشبینی و استنتاج در دسترس نیستند. دقیقاً به همین دلیل است که وقتی n کمتر از m است، مقدار D صفر است.
کاهش نمایی هم تکنیکی است که برای کاهش تأثیر عناصری که از موقعیت فعلی در دنباله دورتر هستند استفاده
میشود. این روش تضمین میکند که عناصر نزدیک به موقعیت فعلی اهمیت بیشتری دارند و تأثیر آنها با افزایش فاصله کاهش
مییابد. در مکانیزم توجهبهخود این مفهوم به وسیله تابع Softmax پیادهسازی
میشود؛ اما در مکانیزم نگهداری این عمل با استفاده از ضریب ![]() انجام میشود. برای درک بهتر، مثالی از ماتریس D در زیر آورده شدهاست:
انجام میشود. برای درک بهتر، مثالی از ماتریس D در زیر آورده شدهاست:
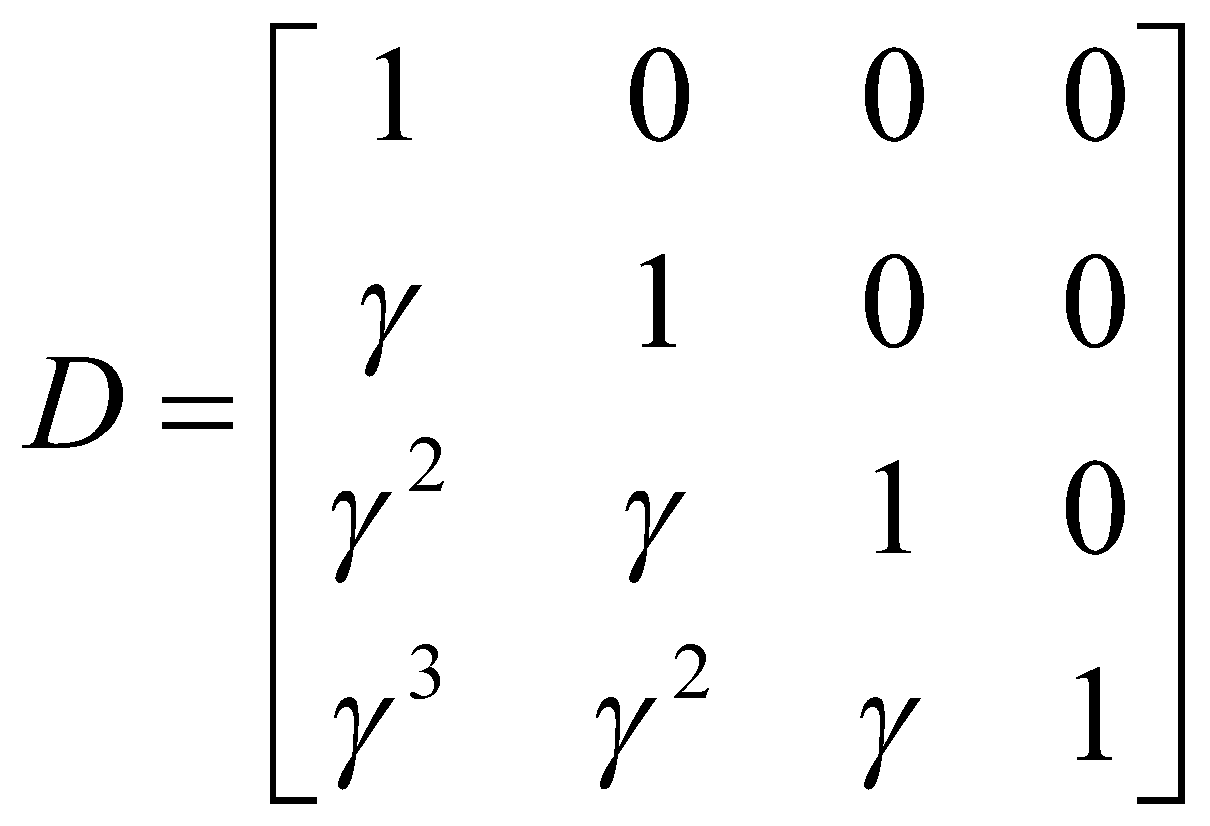
محاسبات موازی مکانیزم نگهداریدر شکل 2 نشان داده شدهاست. بهطور خلاصه، میتوانیم نتیجه بگیریم که دو عمل ماسک کردن توجه و استفاده از تابع Softmax که در مکانیزم توجهبهخود وجود دارد، به شکل دیگری در ماتریس D در مکانیزم نگهداری گنجانده شدهاست.
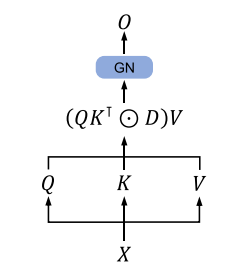
شکل 2: نمایی کلی از محاسبات موازی مکانیزم نگهداری.(GN: مخففِ GroupNorm)
-
بازنمایی بازگشتی مکانیزم نگهداری
همانطور که در شکل 3 نشان داده شدهاست، مکانیزم نگهداری را میتوان بهصورت RNN استفاده کرد. برای گام زمانی n، بهطور بازگشتی خروجی بهصورت زیر به دست میآید:
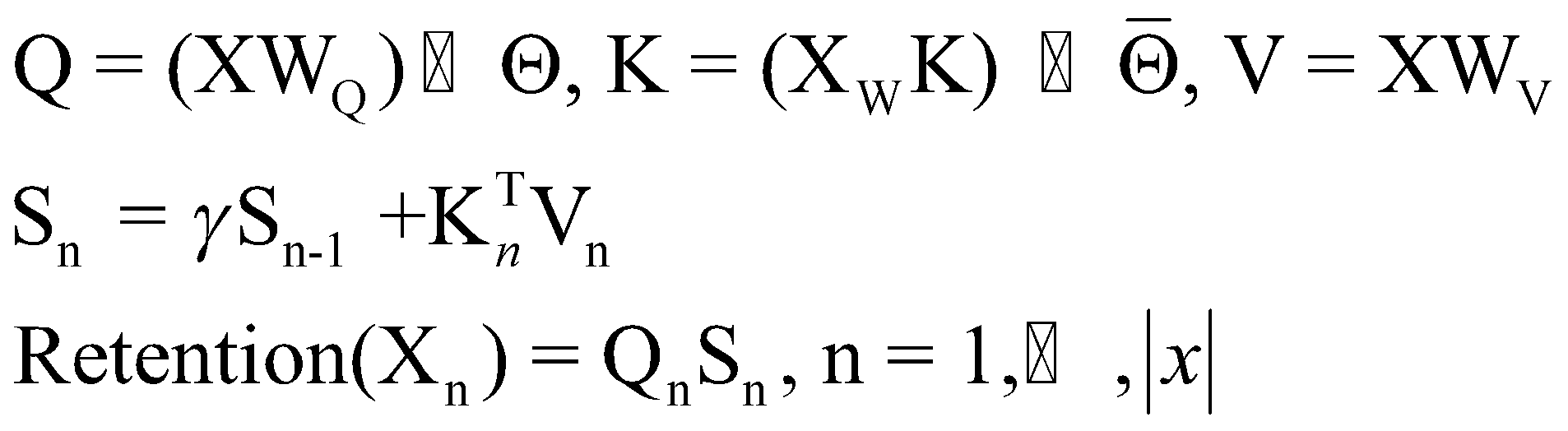
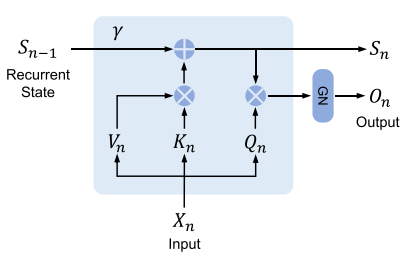
شکل 3: نمایی از محاسبات بازگشتی مکانیزم نگهداری.
توجه داشته باشید که اگر رابطه بازگشتی ![]() در عبارت را باز کنیم، به همان بازنمایی موازی مکانیزم نگهداری در عبارت
میرسیم؛ بنابراین خروجی هر دو بازنمایی یکسان خواهد بود. برای نشان دادن این موضوع از یک مثال استفاده
میکنیم. فرض کنید یک دنباله با دو توکن داریم (N=2) و سایز تعبیه برابر سه است (D=3). اگر ماتریسهای K، Q و V
بهصورت زیر باشند و
در عبارت را باز کنیم، به همان بازنمایی موازی مکانیزم نگهداری در عبارت
میرسیم؛ بنابراین خروجی هر دو بازنمایی یکسان خواهد بود. برای نشان دادن این موضوع از یک مثال استفاده
میکنیم. فرض کنید یک دنباله با دو توکن داریم (N=2) و سایز تعبیه برابر سه است (D=3). اگر ماتریسهای K، Q و V
بهصورت زیر باشند و ![]() آنگاه بازنمایی موازی مکانیزم نگهداری بهصورت زیر محاسبه میشود:
آنگاه بازنمایی موازی مکانیزم نگهداری بهصورت زیر محاسبه میشود:
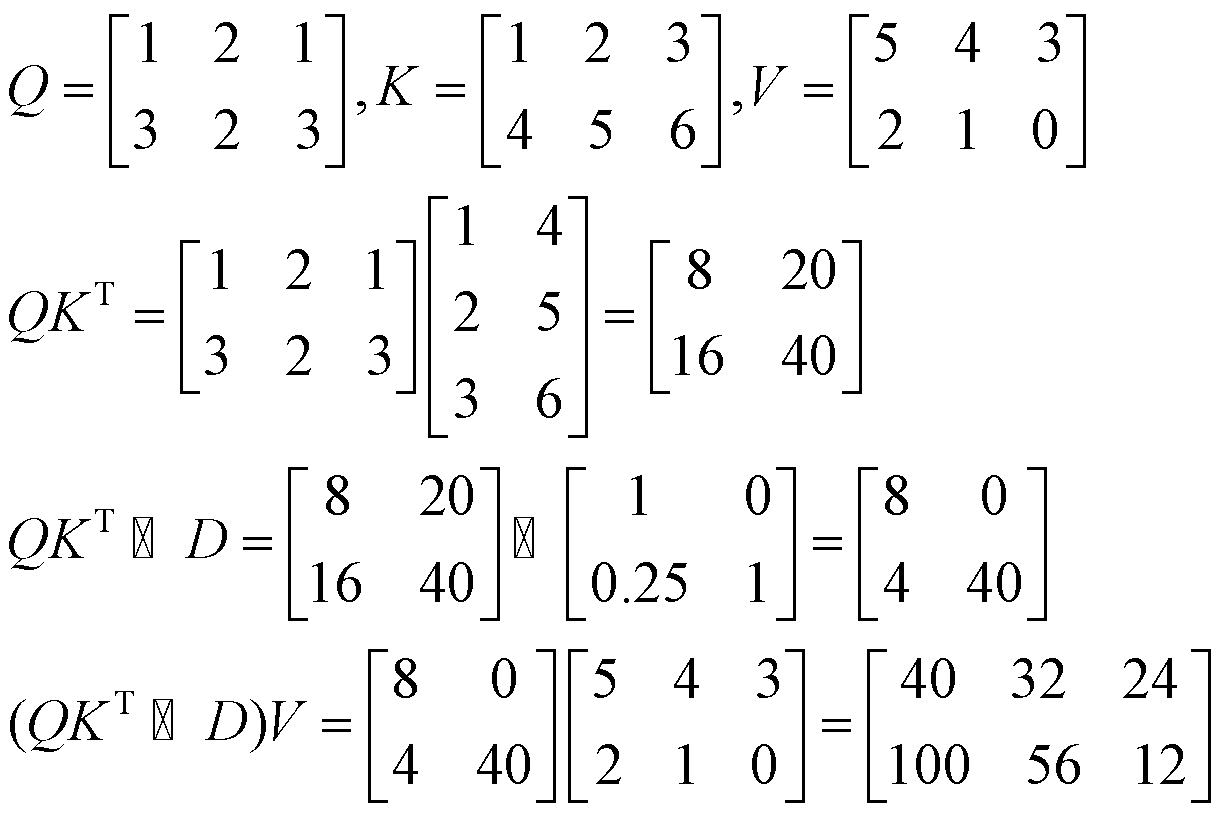
همچنین بازنمایی بازگشتی آن بهصورت زیر است:
![]()
همانطور که مشخص است خروجی بهدستآمده از هر دو روش یکسان است.
-
بازنمایی بازگشتی تکهای مکانیزم نگهداری
در این بخش ترکیبی از بازنمایی موازی و بازنمایی بازگشتی مکانیزم نگهداری برای سرعت بخشیدن به روند آموزش، به ویژه برای دنبالههای طولانی ارائه میشود. ابتدا دنبالههای ورودی به بخشهای کوچکتر تقسیم میشود. سپس در داخل هر تکه، از بازنمایی موازی برای انجام محاسبات استفاده میشود (عبارت ). با این حال، وقتی صحبت از تبادل اطلاعات بین تکههای مختلف میشود، از بازنمایی بازگشتی استفاده میشود (عبارت ). اگر طول هر تکه را B در نظر بگیریم؛ خروجی نگهداری برای تکه i بهصورت زیر محاسبه میشود:
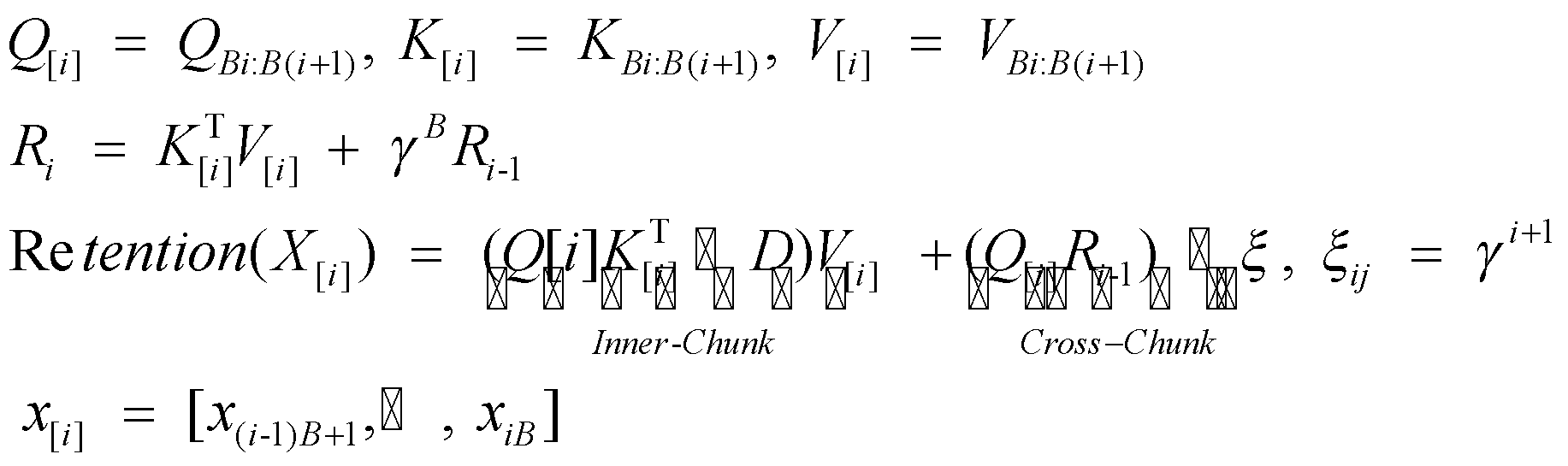
شبهکد سه پارادایم محاسبه مکانیزم نگهداری در شکل 4 آورده شدهاست:

شکل 4: شبهکد سه پارادایم محاسباتی مکانیزم نگهداری.
-
فرایند نگهداری چندمقیاسی دارای دروازه
همانند مکانیزم توجهبهخود که بهصورت چندسر در هر لایه انجام میشود؛ مکانیزم نگهداری نیز در هر لایه
در چندمقیاس یا چندسر محاسبه میشود. در هر سر، از ماتریسهای پارامتر ![]() متفاوتی استفاده میشود. علاوه بر این، در هر سر مقدار متفاوتی به پارامتر γ اختصاص
داده میشود؛ اما برای سادگی، مقدار پارامتر γ در بین لایههای مختلف یکسان و ثابت در نظر گرفته میشود. همچنین از
تابع Swish برای غیرخطی کردن مکانیزم نگهداری استفاده میشود؛ بنابراین ماژول MSR برای ماتریس ورودی X بهصورت زیر
تعریف میشود:
متفاوتی استفاده میشود. علاوه بر این، در هر سر مقدار متفاوتی به پارامتر γ اختصاص
داده میشود؛ اما برای سادگی، مقدار پارامتر γ در بین لایههای مختلف یکسان و ثابت در نظر گرفته میشود. همچنین از
تابع Swish برای غیرخطی کردن مکانیزم نگهداری استفاده میشود؛ بنابراین ماژول MSR برای ماتریس ورودی X بهصورت زیر
تعریف میشود:
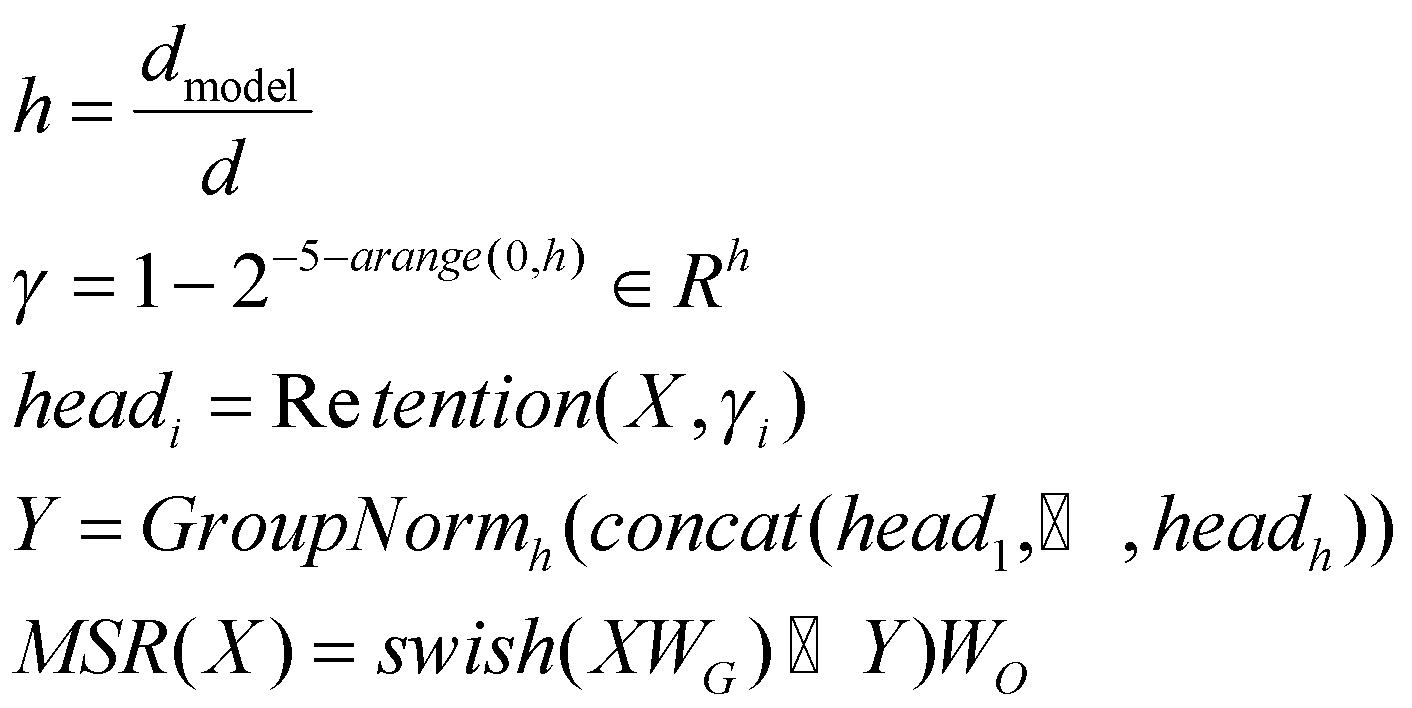
که در آن h تعداد سرها و ![]() پارامترهای قابلیادگیری است. GroupNorm یک تابع نرمالسازی است که خروجی هر سر را
با تابع SubLN نرمالسازی میکند.
پارامترهای قابلیادگیری است. GroupNorm یک تابع نرمالسازی است که خروجی هر سر را
با تابع SubLN نرمالسازی میکند.
-
ارزیابی مدل RetNet
آزمایشهایی برای ارزیابی مدل RetNet انجام شدهاست که نتایج آنها را در این بخش بررسی میکنیم. برای انجام این آزمایشها مدل RetNet با سایزها و ابرپارامترهای مختلف آموزش داده شدهاست که در شکل 5 جزئیات آن آورده شدهاست.

شکل 5: سایزها و ابرپارامترهای مختلف برای آموزش مدل RetNet برای مدلسازی زبان.
در شکل 6 معیار سرگشتگی برای مدلهای زبانی مبتنی بر ترنسفورمر و RetNet در سایزهای مختلف گزارش شدهاست. مطابق شکل 6 مدل RetNet به نتایج قابلمقایسهای نسبت به مدل ترنسفورمر دست مییابد. علاوه بر عملکرد، آموزش مدل RetNet در آزمایشها کاملاً پایدار است. نتایج نشان میدهد که RetNet یک رقیب قوی برای ترنسفورمرها در مدلهای زبانی بزرگ است. همچنین متوجه میشویم که عملکرد مدل RetNet زمانی بهتر از عملکرد مدل ترنسفورمر میشود که اندازه مدل بزرگتر از 2 میلیارد پارامتر باشد.
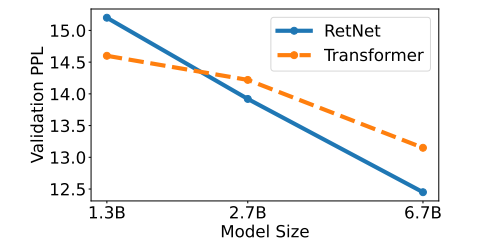
شکل 6: مقایسه عملکرد RetNet و ترنسفورمر با سایزهای مختلف برای مدلسازی زبان براساس معیار سرگشتگی.
در آزمایشی دیگر، مدلهای ترنسفورمر و RetNet در طیف گستردهای از وظایف پاییندستی با هم مقایسه شدهاند. در شکل 7، نتایج دو مدل ترنسفورمر و RetNet با 6.7 میلیارد پارامتر بهصورت یادگیری بدون نمونه و یادگیری با 4 نمونه بر روی مجموعهدادههای HellaSwag، BoolQ، COPA، PIQA، Winograd، Winogrande و StoryCloze آورده شدهاست. همانطور که مشخص است؛ مدل RetNet نتایج بهتری را نسبت به ترنسفورمر به دست آوردهاست.
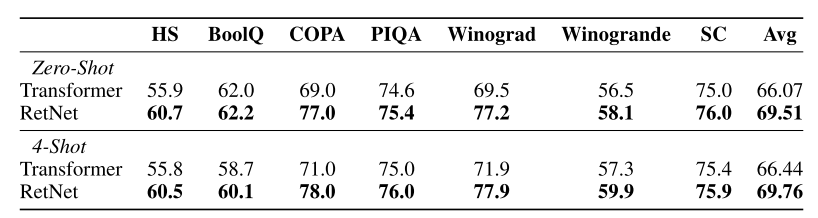
شکل 7: مقایسۀ عملکرد مدل RetNet و ترنسفورمر بر روی مجموعهدادههای مختلف بهصورت یادگیری بدون نمونه و 4 نمونه براساس معیار دقت.
یافتهها در شکل 8 بهصراحت نشان میدهد که مدل RetNet از مدل ترنسفورمر در کارایی حافظه و توان عملیاتی در طول آموزش پیشی میگیرد. علاوه بر این، حتی در مقایسه با FlashAttention که یک نسخۀ بهینهشده است، مدل RetNet برتری خود را از نظر سرعت و استفاده از حافظه نشان میدهد.
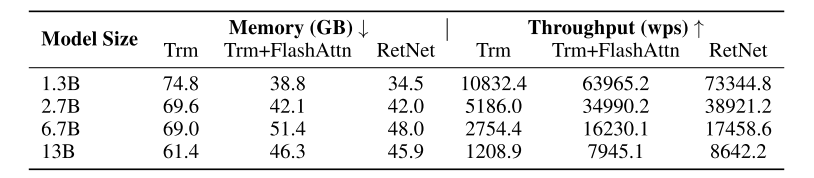
شکل 8: مقایسۀ هزینۀ آموزش Transformer (Trm)، Transformer with FlashAttention (Trm+FlashAttn) و RetNet.
در طول استنتاج، RetNet از چندین جنبه بهتر از ترنسفورمر عمل میکند. RetNet نیاز به حافظۀ کمتری دارد (شکل 9)، حتی در دنبالههای طولانیتر توان عملیاتی ثابتی را حفظ میکند (شکل 10) و تأخیر کمتری را در اندازههای دستهای مختلف و طولهای ورودی نشان میدهد (شکل 11). در مقابل، استفاده از حافظه در ترنسفورمر با افزایش طول ورودی افزایش مییابد (شکل 9)، توان عملیاتی آن با رمزگشایی طولانیتر کاهش مییابد (شکل 10)، و تأخیر آن با اندازههای دستهای و طول ورودی بزرگتر افزایش مییابد (شکل 11). این محدودیتهای ترنسفورمر منجر به کاهش کلی در سرعت استنتاج میشود.
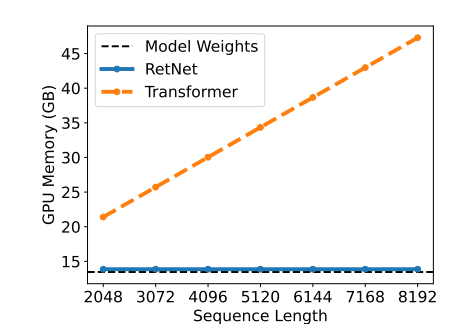
شکل 9: مقایسۀ هزینۀ حافظه GPU در ترنسفورمر و RetNet.
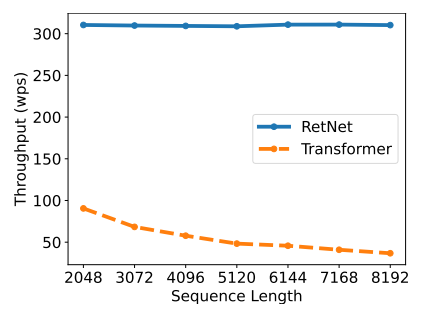
شکل 10: مقایسۀ توان عملیاتی ترنسفورمر و RetNet.
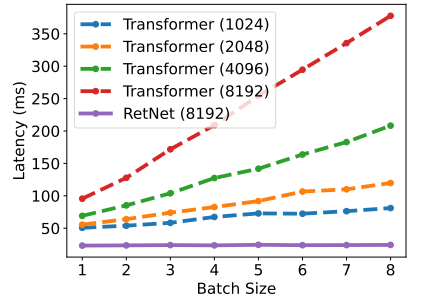
شکل 11:مقایسه تأخیر استنتاج با اندازههای دستهای مختلف در ترنسفورمر و RetNet.
عملکرد مدل RetNet با انواع مختلف ترنسفورمرهای کارآمد از جمله Linear Transformer، RWKV، H3 و Hyena مقایسه گردید. همۀ این مدلها از حیث اندازه با حدود 200 میلیون پارامتر و 16 لایه با مدل RetNet مشابه هستند. با توجه به شکل 12، مدل RetNet از دیگر معماریها، هم در مجموعه ارزیابی دروندامنه و هم در مجموعههای مختلف خارج از دامنه عملکرد بهتری دارد. این عملکرد فوقالعاده مدل RetNet را بهعنوان یک جانشین قوی برای مدل ترنسفورمر معرفی میکند.
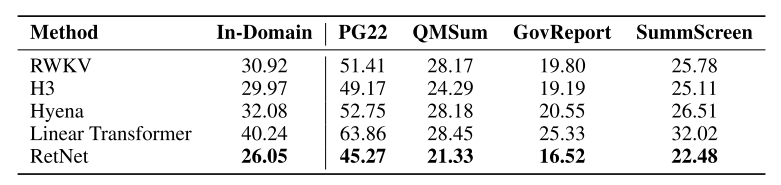
شکل 12: مقایسۀ مدل RetNet با ترنسفورمرهای مختلف در مدلسازی زبان براساس معیار سرگشتگی.
در نهایت، آزمایشهایی بر روی مدل RetNet انجام شد که تأثیر انتخابهای مختلف طراحی بر قابلیتهای مدلسازی زبانی مدل RetNet را بررسی میکند؛ بنابراین در تجزیه و تحلیل RetNet، تغییرات متعددی در طراحی آن ایجاد شد و تأثیر آنها بر مدلسازی زبان ارزیابی شد. این تغییرات در معماری مدل RetNet به شرح زیر است:
- معماری: در این آزمایش اثر حذف دروازه Swish و GroupNorm مورد بررسی قرار گرفت. نتایج در شکل 13 نشان میدهد که هر دو جزء مفید هستند. دروازه swish غیرخطیبودن و قابلیت مدل را افزایش میدهد، در حالی که GroupNorm ثبات آموزشی و نتایج مدلسازی زبانی را بهبود میبخشد.
- کاهش چندمقیاسی: قبلاً اشاره کردیم که در ماژول MSR، مقدار پارامتر γ در سرهای مختلف متفاوت است. در این آزمایش، دو سناریو مورد آزمایش قرار گرفت: در سناریو اول پارامتر γ حذف شد و در سناریو دوم پارامتر γ برای همۀ سرها یکسان در نظر گرفته شد. شکل 13 نشان میدهد که هم مکانیزم کاهش و هم مقدارهای متفاوت پارامتر γ ، عملکرد مدلسازی زبان را افزایش میدهند.
- Head Dimension: از دیدگاه بازگشتی، Head Dimension به ظرفیت حافظه حالتهای پنهان مربوط میشود. در این آزمایش، Head Dimension از 256 به 64 کاهش یافت (64 برای کوئریها و کلیدها و 128 برای مقادیر). نتایج شکل 13 نشان میدهد که Head Dimension بزرگتر منجر به بهبود عملکرد میشود.
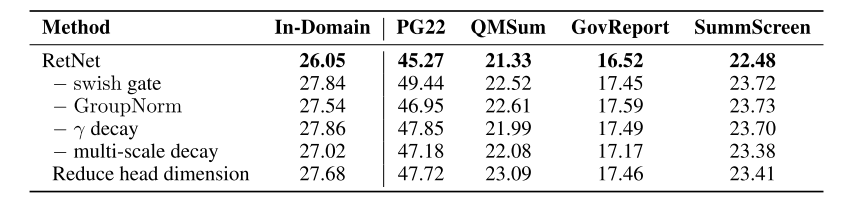
شکل 13: بررسی تأثیر عوامل مختلف بر روی عملکرد مدل RetNet.
بهطور خلاصه، در این بخش تجزیه و تحلیل دقیقی از عملکرد مدل RetNet ارائه کردیم. این نتایج نشان میدهد که RetNet علاوه بر عملکرد قابلمقایسه با مدلهای ترنسفورمر، پایداری آموزش بالایی دارد. همچنین، مدل RetNet از نظر کارایی حافظه و توان عملیاتی در طول آموزش از مدلهای ترنسفورمر پیشی میگیرد. در نهایت، آزمایشات حاکی از این موضوع هستند که میتوان از مدل RetNet بهعنوان یک جانشین قوی و کارآمد برای مدلهای ترنسفورمر در مدلسازی زبانی استفاده کرد.
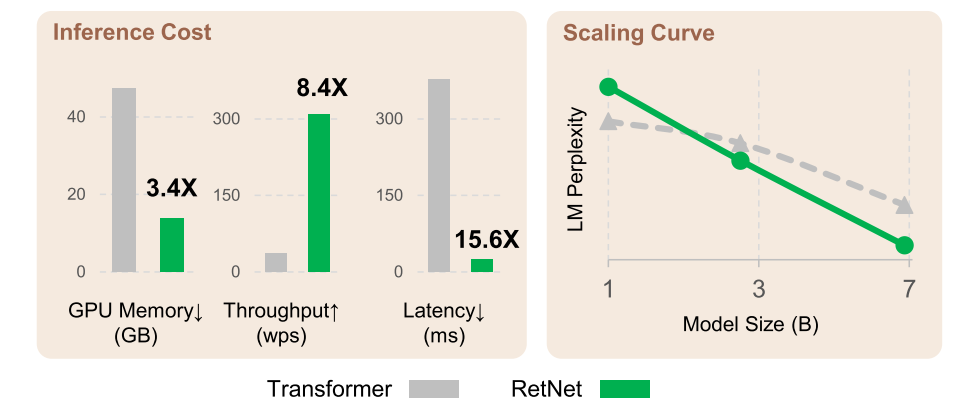
شکل 14: مقایسۀ مدل ترنسفورمر و RetNet.
-
نتیجهگیری
در این مقاله، مدل RetNet را برای مدلسازی دنبالهای معرفی کردیم که ساختاری شبیه به مدلهای ترنسفورمر دارد که به جای استفاده از مکانیزم توجهبهخود از مکانیزم نگهداری استفاده میکند. این مکانیزم دارای سه بازنمایی مختلف موازی، بازگشتی و بازگشتی تکهای است که مدل RetNet را قادر میسازد مانند مدلهای ترنسفورمر بهصورت موازی بر روی GPU آموزش داده شود و در زمان استنتاج همانند مدلهای RNN از حالت بازگشتی استفاده کند. RetNet در مقایسه با مدلهای ترنسفومر نه تنها از نظر حافظه، سرعت و تأخیر در زمان استنتاج عملکرد بهتری دارد، بلکه در موازیسازی آموزش نیز برتری مییابد. مزایای فوق RetNet را به جانشین ایدهآل برای ترنسفورمرها، به ویژه برای مدلهای زبانی بزرگ، تبدیل میکند. RetNet نشاندهندۀ یک تغییر پارادایم در این زمینه است که نویدبخش افزایش بهرهوری و اثربخشی در وظایف مدلسازی زبان است و گام مهمی را در دنیای یادگیری عمیق برداشتهاست.
-
منابع
https://medium.com/@choisehyun98/the-rise-of-rnn-review-of-retentive-network-a080a9a1ad1d
https://pub.aimind.so/retentive-networks-a-deep-dive-e8c5c3853d4c

نظرات