به کارگیری توجه در شبکه های عصبی
ترجمه ساراناز عبداللهی از مقاله effective approaches to attention-based neural machine translation

چکیده
از مکانیزم توجه با تمرکز بر بخشهایی از جمله مبدأ، در بهبود ترجمه ماشینی با استفاده از شبکههای عصبی (NMT) استفاده شدهاست. در این پست میخواهیم با کمک این مقاله دو کلاس ساده و مؤثر از مکانیزم توجه یعنی رویکرد سراسری و محلی را توضیح دهیم. در رویکرد توجه سراسری، به همه کلمات مبدأ توجه میشود اما در رویکرد محلی، مدل در هر زمان تنها به زیرمجموعهای از کلمات مبدأ توجه میکند. در این مقاله یک مدل ترکیبی با استفاده از معماریهای مختلف مکانیزم توجه ارائه شده، که در ادامه با جزئیات بیشتری به آن میپردازیم.
مقدمه
ترجمه ماشینی با استفاده از شبکههای عصبی( NMT) یک روش ترجمه ماشینی است که با استفاده از شبکههای عصبی متون را بین زبانهای مختلف ترجمه میکند. از آنجاییکه NMT، نسبت به سایر وظایف پردازش زبان طبیعی(NLP) از نظر مفهومی سادهتر است، برای ارزیابی مدلهای مختلف مورد استقبال پژوهشگران قرار میگیرد. از این رو، NMT در وظایف ترجمه در مقیاس بزرگ مانند ترجمه از انگلیسی به فرانسوی و انگلیسی به آلمانی به پیشرفتهای خوبی دست یافته است. مدل NMT، در هر زمان یک کلمه از دنبالهی مبدأ را خوانده و کلمهی هدف متناظر با آن را تولید میکند؛ و این کار را تا زمانی که به نماد پایان جمله برسد، ادامه میدهد.
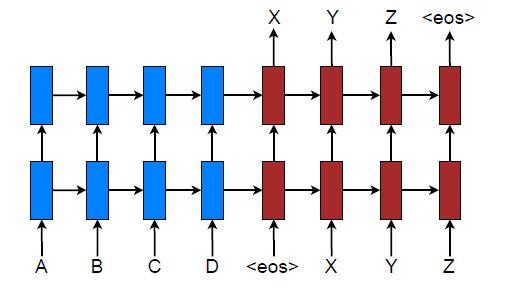
NMT یک شبکه عصبی بزرگ است که اغلب بهصورت سرتاسر آموزش داده شده و در ترجمهی دنبالههای طولانی نتایج خوبی بهدست آورده است. از آنجاییکه در NMT، مدل لازم نیست جداول عظیم عبارات و مدلهای زبانی را ذخیره کند، به فضای حافظه کوچکی نیاز دارد. از طرف دیگر، برخلاف کدگذارهای بسیار پیچیده در ترجمه ماشینی استاندارد، پیادهسازی کدگشاهای NMT بهراحتی قابل انجام است.
به موازات NMT، مفهوم «توجه» در آموزش شبکههای عصبی محبوبیت پیدا کرد؛ زیرا مکانیزم توجه به مدلها اجازه میدهد تا همترازی بین انواع مختلف دادهها را بیاموزند. بهعنوان مثال، بین فریمهای گفتار و متن در وظیفه تشخیص گفتار یا بین ویژگیهای تصویر و توضیح متنی آن در وظیفه تولید عنوان تصویر. در زمینه NMT، باهدانا با موفقیت از مکانیزم توجه، به صورت مشترک، در ترجمه و همتراز کردن کلمات استفاده کرده است.
این مقاله، دو مدل جدید برای مکانیزم توجه را معرفی میکند؛ اولین مدل، رویکرد سراسری است که در آن به همه کلمات مبدأ توجه میشود و دیگری رویکرد محلی است که تنها زیرمجموعهای از کلمات مبدأ را در نظر میگیرد. بهطور تجربی، هر دو رویکرد این مقاله در وظایف ترجمه WMTبین انگلیسی و آلمانی، در هر دوجهت نتایج مؤثری بدست آوردهاند. در ادامه با این دو رویکرد با جزئیات بیشتر آشنا میشویم.
ترجمه ماشینی با استفاده از شبکه عصبی (NMT)
NMT یک شبکهی عصبی است که احتمال شرطی p(y|x) را، که در آن ![]() ترجمه جمله مبدأ و
ترجمه جمله مبدأ و ![]() جمله هدف میباشد، مستقیما مدل میکند. معماری اصلی NMT از دو جزء تشکیل شدهاست:
جمله هدف میباشد، مستقیما مدل میکند. معماری اصلی NMT از دو جزء تشکیل شدهاست:
(الف) یک کدگذار که هر جمله مبدأ را با یک بردار s بازنمایی میکند.
(ب) یک کدگشا که یک کلمه هدف را در هر مرحله زمانی تولید میکند.
بنابراین احتمال شرطی در کدگشا به صورت زیر تجزیه میشود:
(1) ![]()
یک انتخاب طبیعی برای مدلسازی چنین تجزیهای در کدگشا، استفاده از شبکه عصبی بازگشتی (RNN) است. بیشتر مطالعات NMT در انتخاب RNN در معماری کدگشا مشترک هستند اما در انتخاب نوع معماری آن، و نیز شیوه بازنمایی جمله مبدأ در کدگذار با یکدیگر تفاوت دارند.
برای بررسی جزئیات بیشتر عملکرد کدگشا، میتوان احتمال کدگشایی هر کلمه yi را بهصورت زیر پارامتربندی کرد:
(2) ![]()
در اینجا g بهعنوان تابع تبدیل، یک بردار خروجی با اندازه مجموعهی واژگان میسازد. hj واحد پنهان RNN است که بهصورت زیر محاسبه میشود:
(3) ![]()
در معادله بالا، f حالت پنهان فعلی را با توجه به حالت پنهان قبلی محاسبه میکند. تفاوت دیگر در معماری NTMها، در روش استفاده شبکه از بردار بازنمایی s میباشد. در بعضی NMTها، بازنمایی جمله مبدأ s تنها یکبار برای مقداردهی اولیه حالت پنهان در کدگشا استفاده میشود. اما در بعضی دیگر، بردار s مجموعهای از حالتهای پنهان مبدأ است که در کل فرآیند ترجمه استفاده میشود. از چنین رویکردی بهعنوان مکانیزم توجه یاد میشود که در ادامه به آن میپردازیم.
در این پژوهش از معماری LSTM انباشته برای سیستمهای NMT استفاده شدهاست (مطابق شکل 1). هدف آموزشی مدل انباشته به شکل زیر تعریف میشود:
(4) ![]()
در این فرمول همان پیکره آموزش موازی مورداستفاده در پژوهش میباشد.
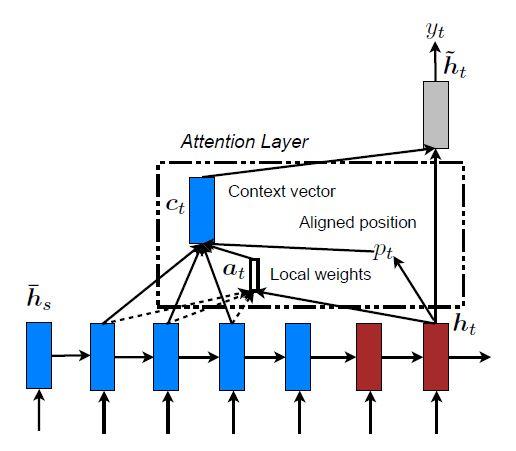
مدلهای مبتنیبر توجه
مدلهای مبتنیبر توجه به دو دسته سراسری و محلی طبقهبندی میشوند. این دوکلاس از نظر اینکه «توجه» روی همه موقعیتهای مکانی جمله مبدأ قرار بگیرد یا فقط روی چند موقعیت مبدأ، متفاوت هستند که جزئیات آنها بهترتیب در شکلهای 2 و 3 نشان داده شده است. نقطه اشتراک این دو نوع مدل این است که در هر مرحله زمانیt، در مرحلهی کدگشایی، از حالت پنهان ht بهعنوان یکی از ورودیهای لایه بالایی LSTM استفاده میشود. هدف این مدلها استخراج یک بردار متنی ct است که اطلاعات موجود در مبدأ را برای کمک به پیشبینی کلمه هدف yt جمعآوری کند. در حالیکه این مدلها در نحوه استخراج بردار متن ct متفاوت هستند، اما مراحل بعدی مشابهی دارند. در مرحلهی بعد حالت پنهان هدف ht و بردار متنی سمت-مبدأ ct ، با استفاده از یک لایه الحاقی ساده با یکدیگر ترکیب شده و حالت پنهان توجه ![]() را میسازند:
را میسازند:
(5) ![]()
سپس بردار توجه ![]() به یک لایه softmax داده شده و توزیع پیشبینی طبق فرمول 6 ایجاد میشود:
به یک لایه softmax داده شده و توزیع پیشبینی طبق فرمول 6 ایجاد میشود:
(6) ![]()
در ادامه با جزئیات به نحوه محاسبه بردار متنی سمت-مبدأ ct برای هر مدل میپردازیم.
توجه سراسری
ایده اصلی مدل توجه سراسری این است که بردار متن ct را از تمام حالتهای پنهان کدگذار استخراج کند. در این نوع مدل، بردار همترازی at با طول متغیر، که اندازه آن برابر با تعداد مراحل زمانی در سمت مبدأ است، با مقایسه حالت پنهان هدف ht با همهی حالت پنهان مبدأ ![]() بهدست می آید:
بهدست می آید:
(7) ![]()
![]()
در معادله 7، ![]() یک تابع مبتنیبرمحتوا نامیده میشود که به سه روش جایگزین محاسبه می شود:
یک تابع مبتنیبرمحتوا نامیده میشود که به سه روش جایگزین محاسبه می شود:
(8) 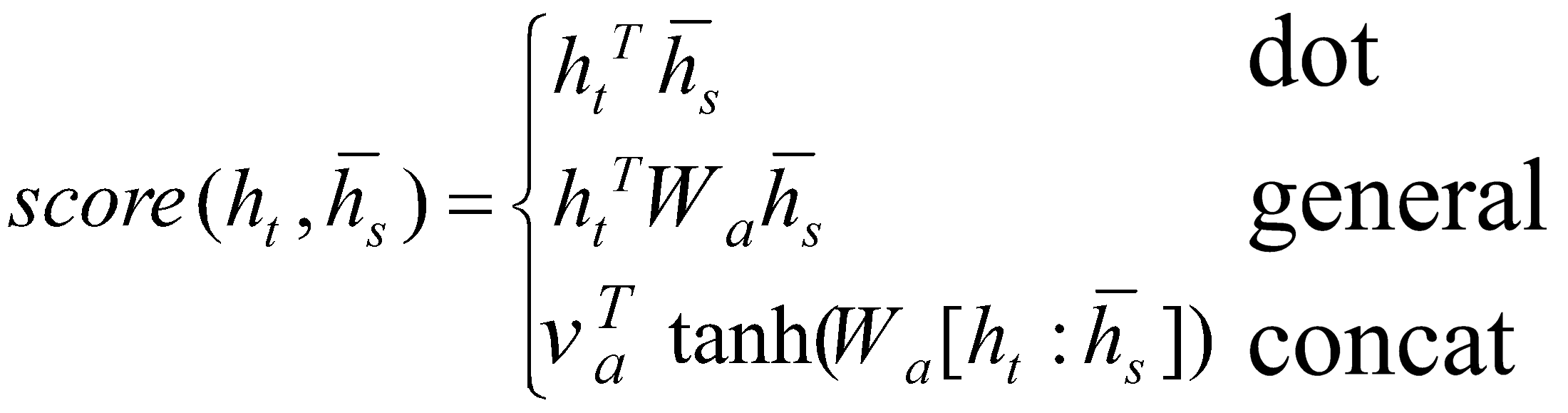
(9) ![]()
بردار متن ct با استفاده از بردار همترازی at بهعنوان وزنها، به صورت یک میانگین وزندار بر روی تمام حالتهای پنهان مبدأ محاسبه میشود.
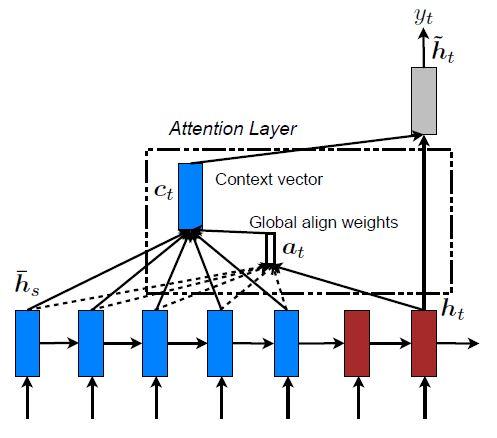
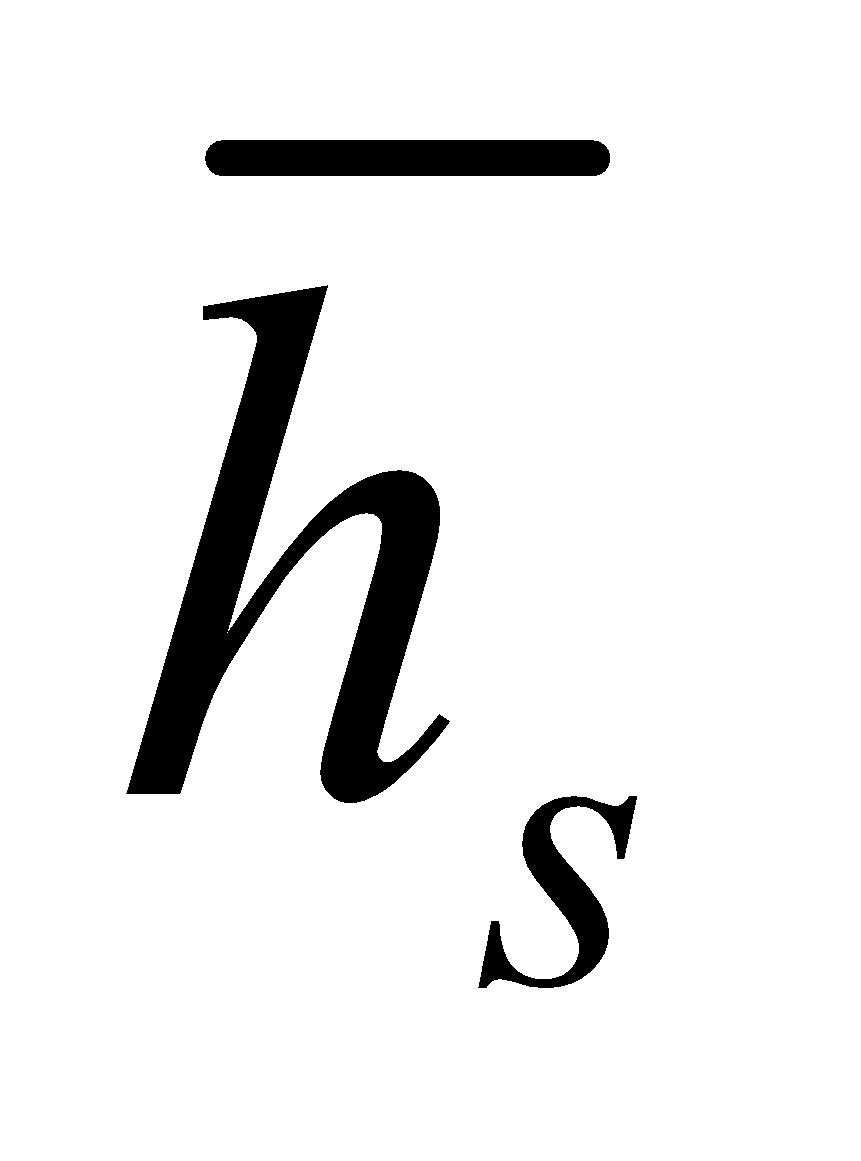 و حالت هدف فعلی ht، استنباط میشود. سپس یک بردار متن کلی ct به شکل یک میانگین وزندار براساس همه حالتهای مبدأ و بردار همترازی at، محاسبه میشود.
و حالت هدف فعلی ht، استنباط میشود. سپس یک بردار متن کلی ct به شکل یک میانگین وزندار براساس همه حالتهای مبدأ و بردار همترازی at، محاسبه میشود.در اینجا به چند تفاوت کلیدی که پژوهشگران این مقاله برای سادهسازی و عمومیسازی مدل اصلی ایجاد کردهاند، میپردازیم:
- اول، در این مدل بهسادگی از حالتهای پنهان در بالای لایههای LSTM هم در کدگذار و هم در کدگشا استفاده شده که در شکل 2 قابل مشاهدهاست.
- دوم، مسیر محاسباتی سادهتر است. در این مقاله مسیر
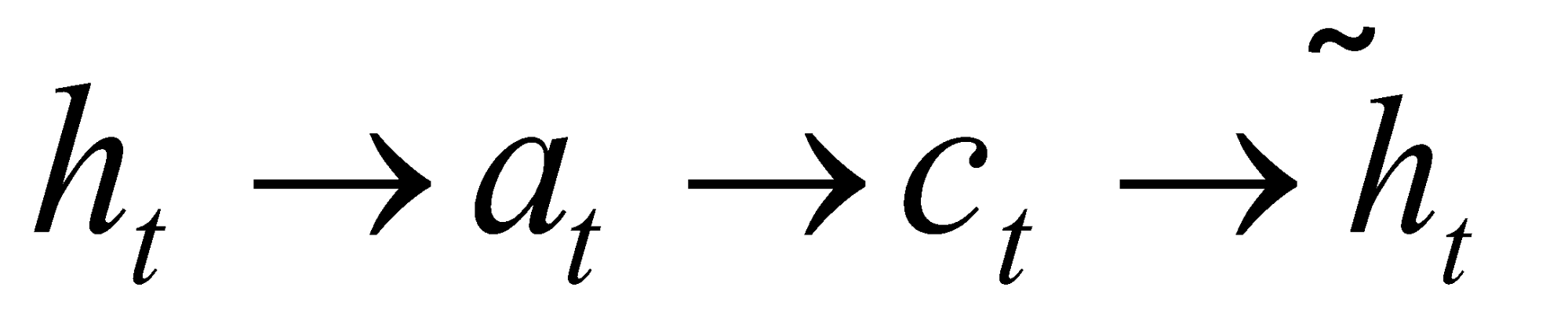 طی شده و پیشبینی براساس معادله 5 و 6 صورت میگیرد.
طی شده و پیشبینی براساس معادله 5 و 6 صورت میگیرد. - سوم، در این مقاله از سه تابع مختلف دیگر علاوه بر تابع الحاق برای محاسبهی امتیاز همترازی استفاده شده است.
توجه محلی
یک مشکل اساسی در مدل توجه سراسری این است که برای ایجاد هر کلمه هدف، به تمام کلماتِ سمت مبدأ توجه میشود. این روند بسیار گران است و ترجمه دنبالههای طولانیتر، مانند پاراگرافها یا اسناد را غیرممکن میسازد. برای حل این چالش، یک مکانیزم توجه محلی پیشنهاد شد که در ایجاد هر کلمه هدف، تنها بر روی یک زیرمجموعه کوچک از موقعیتهای مکانی مبدأ تمرکز کند.
مکانیزم توجه محلی این مقاله بهطور انتخابی روی یک پنجره کوچک از متن تمرکز میکند و رویکردی مشتقپذیر دارد. به صورت دقیقتر، مدل ابتدا یک موقعیت مکانی همترازی Pt، برای هر کلمه هدف، در زمان t ایجاد میکند. سپس، بردار متنی ct با محاسبهی میانگین وزندار، بر روی حالتهای پنهان مبدأ، در یک پنجره مشخص ![]() مشتق میشود. پارامتر D بهصورت تجربی انتخاب شده است. بر خلاف رویکرد توجه سراسری، بردار همترازی محلی at دارای ابعاد ثابت R2D+1 است.
مشتق میشود. پارامتر D بهصورت تجربی انتخاب شده است. بر خلاف رویکرد توجه سراسری، بردار همترازی محلی at دارای ابعاد ثابت R2D+1 است.
 استنتاج میشوند.
استنتاج میشوند.- همترازی یکنواخت: (local-m) در این روش Pt=t قرار داده شده و فرض میشود که دنبالههای مبدأ و هدف بهصورت یکنواخت همپوشانی دارند. در این روش، بردار همترازی at با استفاده از معادله 7 محاسبه میشود.
- همترازی پیشگویانه (local-p): بهجای فرض همترازی یکنواخت، موقعیت همترازی به شکل زیر محاسبه میشود:
(9) ![]()
در این معادله WP و VP پارامترهای مدل هستند که در طول آموزش یاد گرفته میشوند تا بتوانند موقعیتها را پیشبینی کنند. S طول جمله مبدأ را نشان میدهد. استفاده از تابع سیگموئید ، مقدار پیشبینی شده Pt را در محدوده (در محدودهی جمله) قرار خواهد داد. به نفع نقاط همتراز نزدیک Pt، از یک توزیع گاوسی حول محور Pt استفاده شده است. به صورت جزئیتر، وزنهای همترازی بهصورت زیر تعریف میشوند:
(10) ![]()
در این معادله ازتابع همترازی معادله 7 استفاده شده و انحراف استاندارد بهصورت تجربی ![]() تنظیم میشود. باید توجه داشت که Pt یک عدد واقعی است اما s یک عدد صحیح در پنجرهای با مرکزیت Pt است. رویکرد local-p مشابه رویکرد local-m است با این تفاوت که در رویکرد local-p مقدار Pt به صورت پیوسته محاسبه میشود. با استفاده از Pt برای استخراج بردار همترازی، میتوان گرادیان پسانتشار را برای WP و VP محاسبه کرد. این مدل تقریبا در همه ی نقاط مشتقپذیر است.
تنظیم میشود. باید توجه داشت که Pt یک عدد واقعی است اما s یک عدد صحیح در پنجرهای با مرکزیت Pt است. رویکرد local-p مشابه رویکرد local-m است با این تفاوت که در رویکرد local-p مقدار Pt به صورت پیوسته محاسبه میشود. با استفاده از Pt برای استخراج بردار همترازی، میتوان گرادیان پسانتشار را برای WP و VP محاسبه کرد. این مدل تقریبا در همه ی نقاط مشتقپذیر است.
رویکرد تغذیه ورودی
در توجه سراسری و محلی، تصمیمات توجه بهطور مستقل از هم اتخاذ میشوند که رویکردی غیربهینه میباشد. در حالیکه در MT استاندارد، یک مجموعه پوششی در طول فرآیند ترجمه نگهداری میشود تا به کمک آن بتوان مشخص کرد کدام کلمات مبدأ ترجمه شدهاند. در مدلهای NMT مبتنی بر توجه نیز لازم است تصمیمات همترازی، با در نظر گرفتن اطلاعات قبلی همترازی اتخاذ شود. برای حل این مشکل، از یک روش تغذیه ورودی استفاده میشود. در این روش مطابق شکل 10، بردارهای توجه ![]() با ورودیهای مرحلهبعدی ادغام میشوند. تأثیر چنین اتصالاتی بر روی مدل دوجهته است: (1) با ترکیب بردارهای توجه با ورودیها، انتظار میرود مدل بهطور کامل از تصمیمات همترازی گذشته آگاه شود؛ (2) شبکه بهصورت عمودی و افقی عمیق شده و گسترش پیدا میکند. در واقع، روش پیشنهادی این مقاله شبکهای عمیقتر و پیچیدهتر از روشهای قبلی ارائه کرده است.
با ورودیهای مرحلهبعدی ادغام میشوند. تأثیر چنین اتصالاتی بر روی مدل دوجهته است: (1) با ترکیب بردارهای توجه با ورودیها، انتظار میرود مدل بهطور کامل از تصمیمات همترازی گذشته آگاه شود؛ (2) شبکه بهصورت عمودی و افقی عمیق شده و گسترش پیدا میکند. در واقع، روش پیشنهادی این مقاله شبکهای عمیقتر و پیچیدهتر از روشهای قبلی ارائه کرده است.
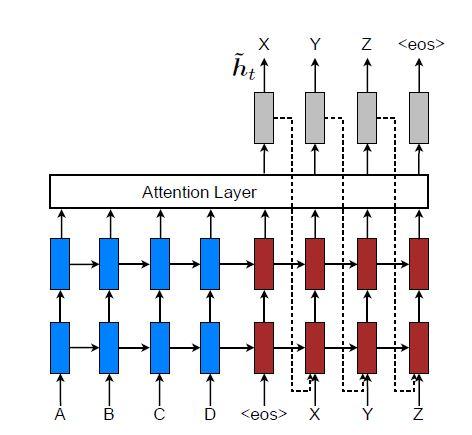
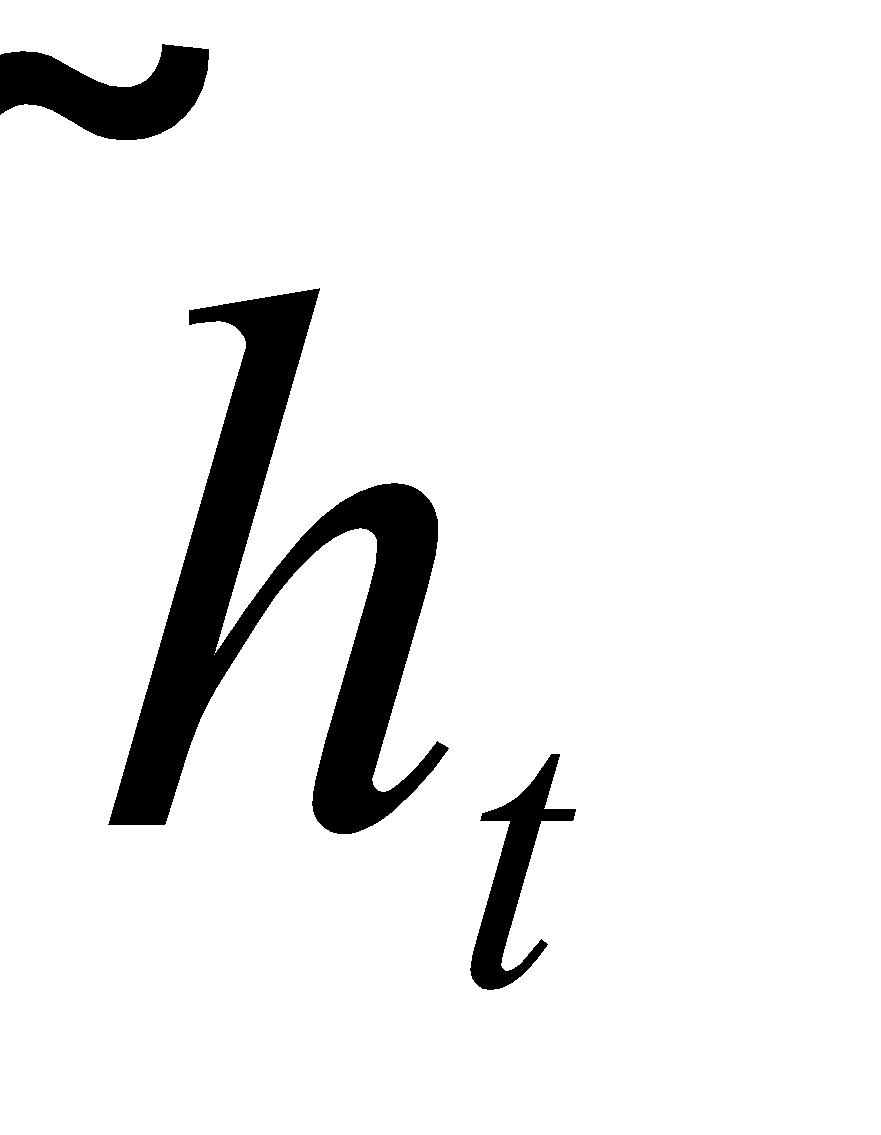 بهعنوان ورودی به مراحل بعدی تغذیه میشوند تا مدل را در مورد تصمیمات همترازی گذشته آگاه کنند.
بهعنوان ورودی به مراحل بعدی تغذیه میشوند تا مدل را در مورد تصمیمات همترازی گذشته آگاه کنند.آزمایشات
اثربخشی مدلهای این مقاله بر وظایف ترجمه WMT بین انگلیسی و آلمانی در هر دو جهت ارزیابی شدهاست. مجموعه داده newstest2013 (3000 جمله) بهعنوان مجموعه توسعه برای انتخاب هایپرپارامترها استفاده شدهاست. مجموعه توسعه، مجموعهای از دادهها است که برای تنظیم و انتخاب پارامترهای مدل استفاده میشود. این مجموعه داده در فرآیند آموزش مدل استفاده نمیشوند، اما برای تنظیم بهینه پارامترهای مدل، انجام تست و آزمونهای مختلف مورد استفاده قرار میگیرند. عملکرد ترجمه حساس به حروف بزرگ با معیار ارزیابی BLEU در newstest2014 (2737 جمله) و newstest2015 (2169 جمله) گزارش شد. این مقاله برای ارزیابی کیفیت ترجمه از دو مدل BLEU، (1) tokenized BLEU برای مقایسه با وظیفه NMT موجود و (2) NIST13 BLEU برای مقایسه با نتایج WMT استفاده کردهاست که در ادامه با جزئیات ارائه میشود.
جزئیات آموزش مدلها
همه مدلهای این مقاله بر روی دادههای آموزشی WMT14 متشکل از 4.5 میلیون جفت جمله (116 میلیون کلمه انگلیسی، 110 میلیون کلمه آلمانی) آموزش دیدهاند. این مقاله مشابه پژوهشهای دیگر واژگان خود را محدود کرده تا مجموعه واژگان شامل 50 هزار کلمه پرتکرار برای هر دو زبان باشد. کلماتی که در این مجموعه واژگان نهایی قرار نمیگیرند، به یک توکن جهانی تبدیل میشوند.
هنگام آموزش سیستم NMT جفتهایی که طول آنها فراتر از 50 کلمه است، فیلتر شده و زیردستهها بُر میخورند. از 4 لایه مدل LSTM انباشته استفاده شده که هر کدام از آنها دارای 1000 سلول و بردارهایتعبیه 1000 بُعدی هستند. پارامترها بهطور یکنواخت در بازه [-0.1، 0.1] مقداردهی اولیه میشوند. مدل را برای 10 دوره با استفاده از SGD ساده آموزش داده میشود.
از حذف تصادفی با احتمال 0.2 برای LSTMها استفاده شدهاست.
نتایج ترجمه انگلیسی به آلمانی
نتایج این مدل با مدلهای قبلی در جدول 11 آمده است.
جدول 11. نتایج WMT14 انگلیسی-آلمانی.
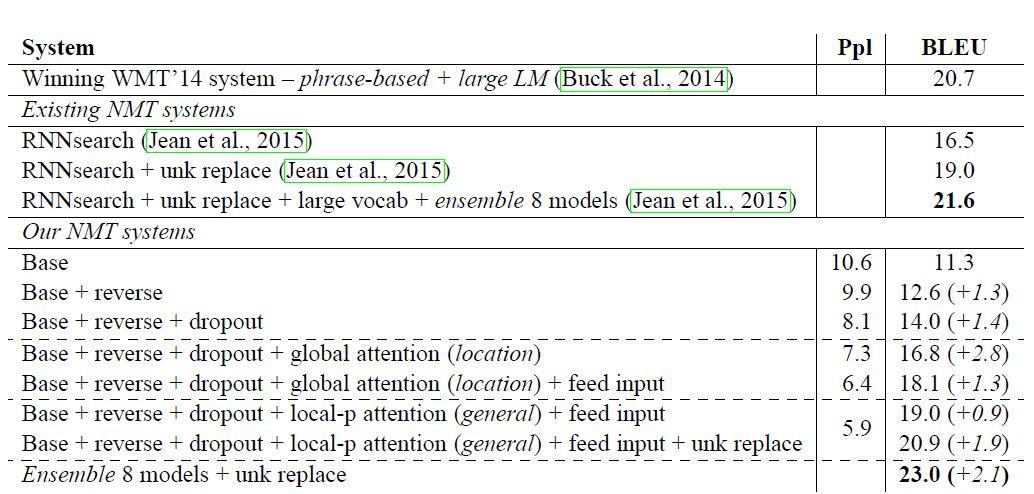
- معکوس کردن جمله مبدأ و استفاده از حذف تصادفی، کمی بیشتر از یک امتیاز نتایج را بهبود دادند.
- استفاده از رویکردهای توجه سراسری، تغذیهی ورودی و توجه محلی امتیاز BLEU را به ترتیب 2.8، 1.3، و 0.9 افزایش دادند.
- در مجموع، این مقاله به افزایش قابل توجه 5.0 امتیاز BLEU نسبت به مدل پایه بدون توجه که شامل تکنیکهای شناخته شدهای مانند معکوس کردن جملات مبدأ و حذف تصادفی بوده، دست یافته است.
- تکنیک جایگزینی کلمه ناشناخته امتیاز BLEU را به بیش از 1.9 بهبود داده، که نشان میدهد مدلهای توجه این مقاله همترازیهای مفیدی را برای کارهای ناشناخته یاد میگیرند.
- در نهایت، با ترکیب 8 مدل مختلف، بهعنوان مثال، استفاده از رویکردهای مختلف توجه، با و بدون حذف تصادفی، این مقاله به یک نتیجه پیشرفته (SOTA) جدید با امتیاز 23.0 BLEU دست یافت که از آخرین نتایج موجود در WMT15 بهتر بودهاست.
مطابق جدول 12، بهترین سیستم این مقاله یک عملکرد پیشرفته جدید با امتیاز BLEU 25.9 ایجاد کرده، که از بهترین سیستم موجود با پشتیبانی NMT و یک رتبهبندی مجدد 5-تایی LM با اختلاف 1.0 یا بیشتر در امتیاز BLEU بهتر عمل کرده است.
جدول 12. نتایج WMT'15 انگلیسی-آلمانی – NIST BLEU امتیازات برنده در WMT'15 و بهترین امتیاز این مقاله در newstest2015

بررسی عملکرد رویکردهای توجه در بازدهی مدل
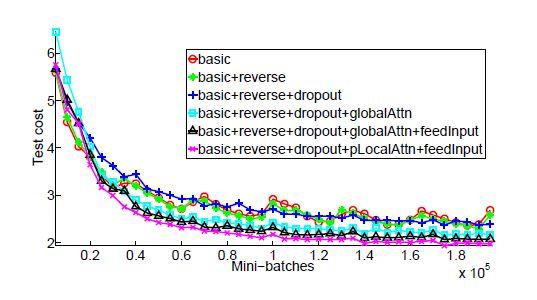
منحنیهای یادگیری
مشاهده فاصله واضح بین مدلهای بدون مکانیزم توجه و مدلهای مبتنیبر مکانیزم توجه در شکل 14، نشاندهنده نقش مکانیزم توجه است. رویکرد تغذیه ورودی و مدل توجه محلی نیز تواناییهای خود را در کاهش هزینههای تست نشان میدهند. یادگیری مدل بدون استفاده از مکانیزم توجه و با حذف تصادفی (منحنی آبی+) کندتر از سایر مدلهای بدون حذف تصادفی است، اما با گذشت زمان، از منظر بهحداقل رساندن خطاهای تست قویتر میشود.
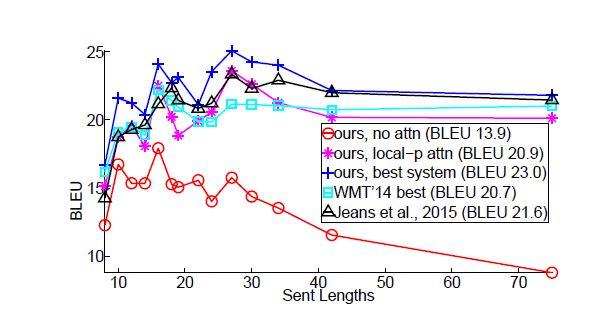
اثرات ترجمه جملات طولانی
همراستا با پژوهش باهدانا، پژوهشگران جملاتی با طولهای مشابه را با هم گروهبندی کرده و امتیاز BLEU را برای هر گروه محاسبه کردند. شکل 15 نشان میدهد که مدلهای توجه این مقاله در دستوپنجه نرم کردن با جملات طولانی، تواناتر از مدلهای بدون توجه هستند، یعنی کیفیت ترجمه آنها با طولانی شدن جملات کاهش نمییابد. بهترین مدل این مقاله (منحنی آبی +) از همه سیستمهای دیگر در طولهای مختلف عملکرد بهتری دارد.
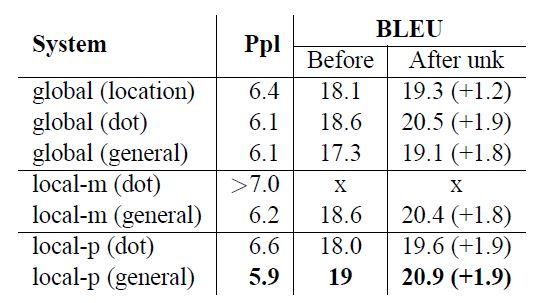
انتخاب معماریهای توجه
در این مقاله پژوهشگران ترکیب مدلهای توجه (global, local-m, local-p ) با توابع همترازی (location, dot, general, concat) را بررسی کردند. با توجه به نتایج شکل 16:
- تابعهای مبتنیبر مکان همترازهای خوبی یاد نمیگیرند: مدل global(location) موفقیت کمتری نسبت به سایر توابع همترازی در جایگزینی کلمات ناشناخته بهدست آورده است.
- در توابع مبتنیبر محتوا، روش concat پیادهسازی شده این مقاله عملکرد خوبی نداشته است.
- علاوه بر این، روشdot در مدل توجه سراسری و روش general در مدل توجه محلی عملکرد بهتری داشتهاند.
- در بین مدلهای مختلف، مدل توجه محلی با استفاده از همترازی پیشگویانه (local-p) بهترین نتایج را هم از نظر پیچیدگی و هم از نظر BLEU ارائه دادهاست.
نمونه ترجمهها
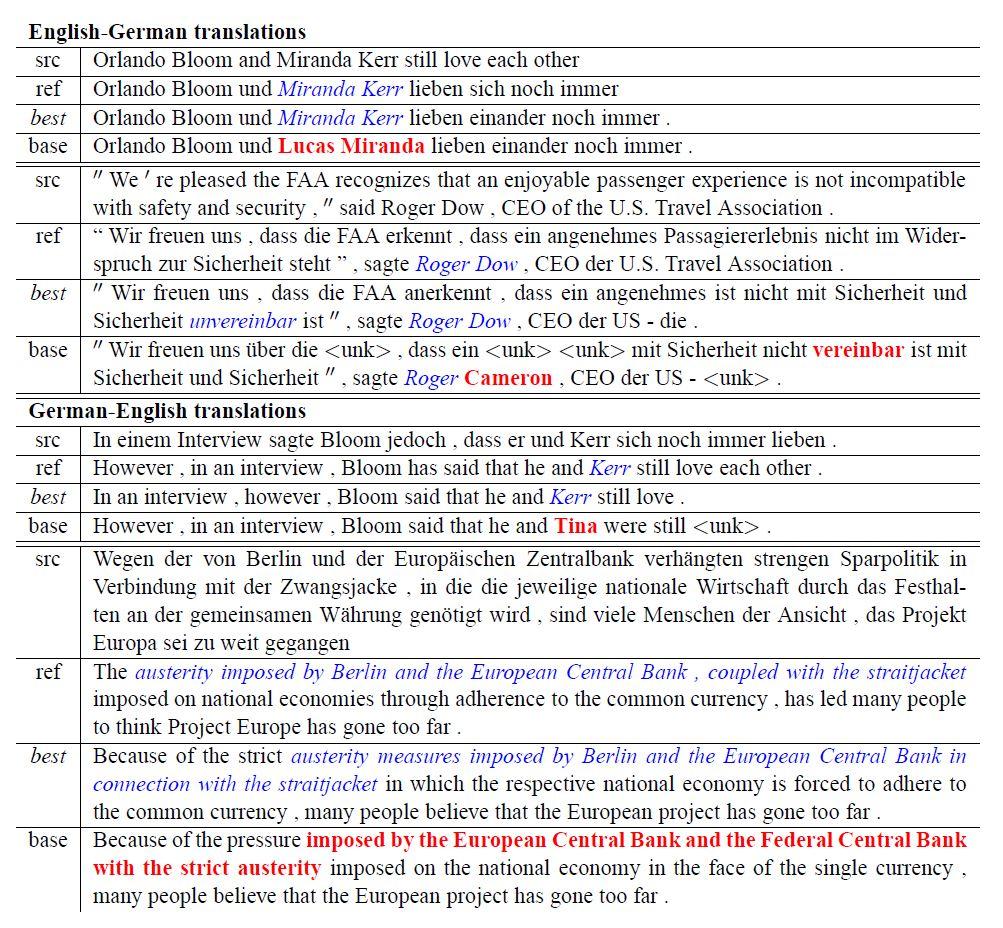
شکل 18، تعدادی از نمونه ترجمهها در هر دوجهت را نشان میدهد. مشاهده تأثیر مدلهای مبتنی بر توجه در ترجمه صحیح نامهایی مانند « Miranda Kerr» و « Roger Dow» بسیار جالب است. مدلهای بدون مکانیزم توجه، با وجود اینکه نامهای معقولی را از نظر مدل زبانی تولید میکنند، اما برای انجام ترجمههای صحیح، فاقد ارتباط مستقیم از سمت مبدأ هستند. یک مورد جالب در مثال دوم، ترجمه عبارت " not incompatible " با نفی مضاعف است. مدل مبتنی بر توجه بهدرستی "nicht . . . unvereinbar" را ارائه میدهد در حالیکه مدل بدون مکانیزم توجه nicht" vereinbar" را به معنای "Incompatible" ترجمه میکند. علاوه بر این، مدل مبتنی بر توجه برتری خود را در ترجمه جملات طولانی مانند مثال آخر نیز نشان میدهد.
نتیجهگیری
دو مکانیزم توجه ساده و مؤثر برای NMT پیشنهاد معرفی شد: رویکرد سراسری که به همه کلمات مبدأ توجه میکند و رویکرد محلی که در هر زمان، تنها به زیرمجموعهای از موقعیتهای مکانی مبدأ توجه میکند. مدل معرفی شده اثربخشی مدلهای خود را در وظایف ترجمه WMT بین انگلیسی و آلمانی در هر دوجهت آزمایش شد. براساس تجزیهوتحلیل این پژوهش، مدلهای NMT مبتنیبر توجه در بسیاری از موارد، از جمله در ترجمه نامها و مدیریت جملات طولانی، نسبت به مدلهای بدون مکانیزم توجه عملکرد بهتری دارند.
منابع
https://towardsdatascience.com/attention-based-neural-machine-translation-b5d129742e2c
https://www.youtube.com/playlist?list=PLHVv_Q5Gh-7ik2yLt56F05c7ZoLtQiXCy
نظرات