"بازنمایی عبارتها با شبکه عصبی کدگذار-کدگشا" (استفاده شده در ترجمه ی ماشینی آماری)
ترجمه ساراناز عبداللهی از مقاله learning phrase representations using rnn encoder–decoder for statistical machine translation

چکیده
با مطرح شدن ایدهی استفاده از شبکههای عصبی در حوزهی ترجمهی ماشینی، محققان رویکردهای مختلفی را ارائه و مورد بررسی قرار دادند. یکی از اولین مدل های ارائه شده، مدل شبکه عصبی بازگشتی کدگذار-کدگشا (RNNencdec) میباشد. در این رویکرد، کدگذار دنبالهی ورودی با طول دلخواه را به شکل برداری با طول ثابت بازنمایی کرده و کدگشا، بردارهای بازنمایی را به دنبالههای خروجی نگاشت میکند. در این حالت، مدل میتواند توزیع احتمالاتی هر دنبالهی ورودی به شرط دنبالهی خروجی را بیاموزد. پس از تکمیل فرآیند آموزش، از احتمالات شرطی محاسبه شده برای هر جفت عبارت، بهعنوان یک ویژگی جدید در جدول عبارات ترجمهی ماشینی آماری(SMT) استفاده میشود. با اضافه کردن این ویژگی دقت و عملکرد ترجمه بهبود مییابد. علاوه بر این، از نظر کیفی مدل پیشنهادی میتواند بازنماییهای معنایی و نحوی را از عبارات زبانی یاد بگیرد. در این پست به معرفی مشروح مدل RNNencdec میپردازیم.
مقدمه
شبکههای عصبی عمیق پیشرفتهای زیادی در کاربردهای مختلف مانند شناسایی اشیاء و تشخیص گفتار داشتهاند. از شبکههای عصبی همچنین میتوان در وظایف مختلف پردازش زبان طبیعی (NLP) مانند مدلسازی زبان، بازنویسی عبارتها و استخراج تعبیه کلمات استفاده کرد. در حوزهی ترجمه ماشینی آماری (SMT) نیز، شبکههای عصبی عمیق نتایج امیدوارکنندهای بهدست آوردهاند. مطالعهی شونک خلاصهای از نمونههای موفق بهکارگیری شبکههای عصبی روبهجلو در ساختار سیستمهای SMT مبتنیبر عبارت ارائه داده است.
SMT ، یکی از رویکردهای ترجمه ماشینی است که از مدلهای احتمالاتی برای تولید ترجمه بین زبانها استفاده میکند. این مدل با تجزیهوتحلیل روابط آماری در حجم زیادی از دادههای دوزبانه، به دنبال محتملترین ترجمه میگردد. در مدل SMT جملات همتراز در قالب یک جدول ذخیره میشوند. ترجمه ماشینی آماری به دو روش مبتنی بر کلمه و مبتنی بر عبارت انجام میشود.
همراستا با استفاده از شبکههای عصبی در ترجمهی ماشینی آماری، میتوان از معماری شبکهعصبی به عنوان بخشی از سیستم SMT استفاده کرد. این مدل شبکه عصبی بازگشتی کدگذار-کدگشا(RNNencdec) نامیده میشود ومتشکل از دو شبکهی RNN است که بهعنوان کدگذار و کدگشا عمل میکنند.
مدل RNNencdec به همراه واحد پنهان، بر روی ترجمه انگلیسی به فرانسوی ارزیابی شدهاست. این مدل، بهعنوان بخشی از سیستم مبتنیبر عبارت SMT، هر جفت عبارت در جدول عبارات را امتیازدهی میکند.
رویکردهای مرتبط: شبکههای عصبی در ترجمه ماشینی
قبل از معرفی مدل RNNencdec، به بررسی پیشینهی تحقیقاتی استفاده از شبکههای عصبی در مدلهای ترجمه ماشینی میپردازیم. در سال 2011، یک مدل مشابه با معماری کدگذار-کدگشا، مبتنی بر دو شبکهی RNNپیشنهاد شد. اما این مدل به تنظیمات تک زبانه محدود بود، یعنی مدل جمله ورودی را به همان زبان بازنویسی میکرد.
در سال 2012، رویکردی مشابه برای امتیازدهی به جفت عبارتها پیشنهاد شد. در این مدل به جای استفاده از RNN، از یک شبکه عصبی روبهجلو با دادههای ورودی با طول ثابت (به طول 7 کلمه، در صورتی که عبارت کوتاهتر باشد، این کلمات با صفرها پر میشوند) و خروجیهایی با طول ثابت (7 کلمه در زبان هدف) استفاده شد. در هنگام استفاده از این شبکه برای امتیازدهی به عبارات در سیستم SMT، حداکثر طول عبارات در حد عبارات کوچک انتخاب شد. این رویکرد در پردازش دنبالههای طولانیتر یا دنبالههایی با طول متغیر به مشکل برخورد میکرد. روش RNNencdec این مشکلات را حل کرده است.
در پژوهشی در سال 2013 پیشنهاد شد که مدل یک تعبیه دو زبانه از کلمات/عبارات را یاد بگیرد. در این رویکرد، با نگاشت کلمات یا عبارات به فضای برداری، امکان محاسبه فاصله بین این عبارات فراهم میشود. این فاصله بهعنوان امتیاز اضافی برای جفت عبارات در سیستم SMT مورد استفاده قرار گرفت.
بهصورت مشابه، پژوهشگر دیگری در سال 2014، از یک شبکه عصبی روبهجلو برای مدلسازی مدل ترجمه استفاده شد، با این تفاوت که مدل هر بار یک کلمه در عبارت هدف را پیشبینی میکرد. در نتایج این پژوهش بهبود قابل توجهی گزارش شد، اما این رویکرد نیازمند آن است که حداکثر طول عبارت ورودی (یا کلمات متنی) از پیش تعیین شود.
در مدل دیگری در سال 2014، دنبالهی ورودی به شکل کیسهای از کلمات بازنمایی شد. در این رویکرد ترتیب کلمات نادیده گرفته شده و فقط فراوانی کلمات در نظر گرفته میشدند. سپس یک شبکه عصبی روبهجلو برای نگاشت دنبالهی ورودی به خروجی آموزش داده شد. این مدل به مدل RNNencdec نزدیک است، اما روش بازنمایی ورودی در این دو رویکرد با یکدیگر متفاوت است. در مدل RNNencdec، ورودی به شکل دنبالهای از کلمات مرتب بازنمایی میشود ولی در این مدل، ورودی به شکل کیسهای از کلمات که ترتیب مشخصی ندارند، بازنمایی میشد.
بهطور کلی، یک تفاوت مهم بین مدل RNNencdec و روشهای پیشنهادی دیگر در نظر گرفتن ترتیب کلمات در عبارات مبدأ و هدف است. مدل RNNencdec بهطور طبیعی تفاوت بین دنبالههایی که کلمات یکسان دارند اما ترتیب آنها متفاوت است را تشخیص میدهد، در حالیکه رویکردهای گفتهشده ترتیب اطلاعات را نادیده میگیرند.
شبکه عصبی بازگشتی کدگذار-کدگشا (RNNencdec)
در این بخش با جزئیات به معرفی مدل ارائه شده RNNencdec میپردازیم.
پیشینه شبکه عصبی بازگشتی (RNN)
شبکه عصبی بازگشتی نوعی شبکه عصبی عمیق است که برای پردازش دادههای دنبالهای طراحی شدهاست. برای آشنایی بیشتر با جزئیات شبکهی RNN به پست مربوطه مراجعه کنید. در هر گام زمانی t، در شبکه RNN، حالت پنهان h(t) به شکل زیر بهروزرسانی میشود:
(1) ![]()
RNN با آموختن پیشبینی نماد بعدی در یک دنباله، توزیع احتمال دنباله ورودی را یاد میگیرد. در این حالت، در هر گام زمانی t خروجی توزیع شرطی ![]() خواهد بود. با ترکیب احتمالات پیشبینی هر نماد در دنباله با یکدیگر، احتمال دنباله بهصورت توزیع مشترک محاسبه میشود:
خواهد بود. با ترکیب احتمالات پیشبینی هر نماد در دنباله با یکدیگر، احتمال دنباله بهصورت توزیع مشترک محاسبه میشود:
(2) 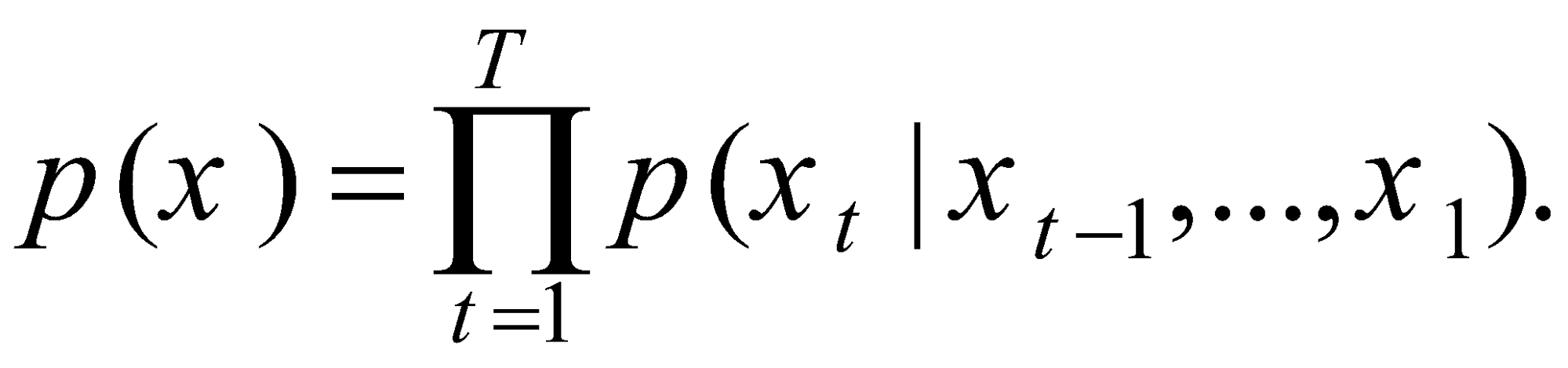
با یادگرفتن این توزیع، میتوان بهراحتی یک دنبالهی جدید را نمونهبرداری کرد. به این روش که مدل بهصورت مکرر در هر گام زمانی، یک نماد را نمونهبرداری کرده و بهعنوان نماد بعدی در دنباله قرار میدهد برای اطلاعات بیشتر به پست شبکههای RNN مراجعه کنید.
شبکهی RNNencdec
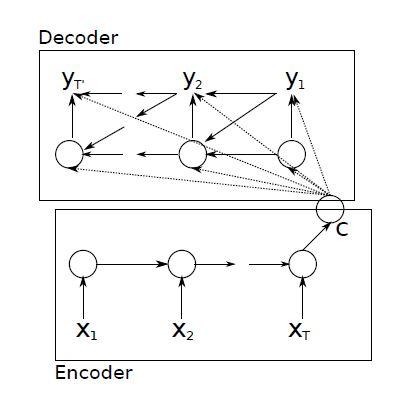
مدل شبکه عصبی بازگشتی کدگذار-کدگشا(RNNencdec) ، متشکل از دو شبکهی RNN است که بهعنوان کدگذار و کدگشا عمل میکنند. این شبکه در مرحلهی کدگذاری یاد میگیرد که چگونه یک دنباله با طول متغیر را به شکل یک بردار با طول ثابت بازنمایی کند؛ و در مرحلهی کدگشایی میآموزد که چگونه این بردار بازنمایی را به یک دنباله جدید با طول متغیر نگاشت کند. از نظر احتمالاتی، این مدل روشی عمومی برای یادگیری توزیع شرطی یک دنباله با طول متغیر به شرط یک دنباله دیگر با طول متغیر ![]() را ارائه میدهد که در آن طول دنباله ورودی و خروجی یعنی T و T` ، میتوانند متفاوت باشند.
را ارائه میدهد که در آن طول دنباله ورودی و خروجی یعنی T و T` ، میتوانند متفاوت باشند.
کدگذار یک RNN است که هر نماد در دنباله ورودی X را بهترتیب میخواند. در هر بار خواندن، حالت پنهان RNN مطابق با فرمول (1) بهروزرسانی میشود. پس از خواندن نماد پایان دنباله، حالت پنهان RNN، خلاصهای از کل دنباله ورودی را به شکل بردار C ایجاد میکند.
کدگشا نیز یک RNN است که با پیشبینی نماد بعدی yt براساس حالت پنهان h(t)، دنباله خروجی را تولید میکند. با این حال، هر دو خروجی yt و حالت پنهان ht به خروجی مرحلهی قبل (yt-1) و خلاصه دنباله ورودی C نیز وابستهاند. بنابراین، فرمولهای RNN در بخش 1 . 2 کمی تغییر یافته و حالت پنهان کدگشا در زمان t به فرم زیر در میآید:
(3) ![]()
بهطور مشابه، فرمول توزیع شرطی نیز به فرم زیر تغییر میکند:
(4) ![]()
شکل 1 ساختار مدل RNNencdec را نشان میدهد. در این مدل دو بخش کدگذار و کدگشا بهصورت مشترک آموزش داده میشوند، تا احتمال شرطی لگاریتمی زیر را بیشینه کنند:
(5) 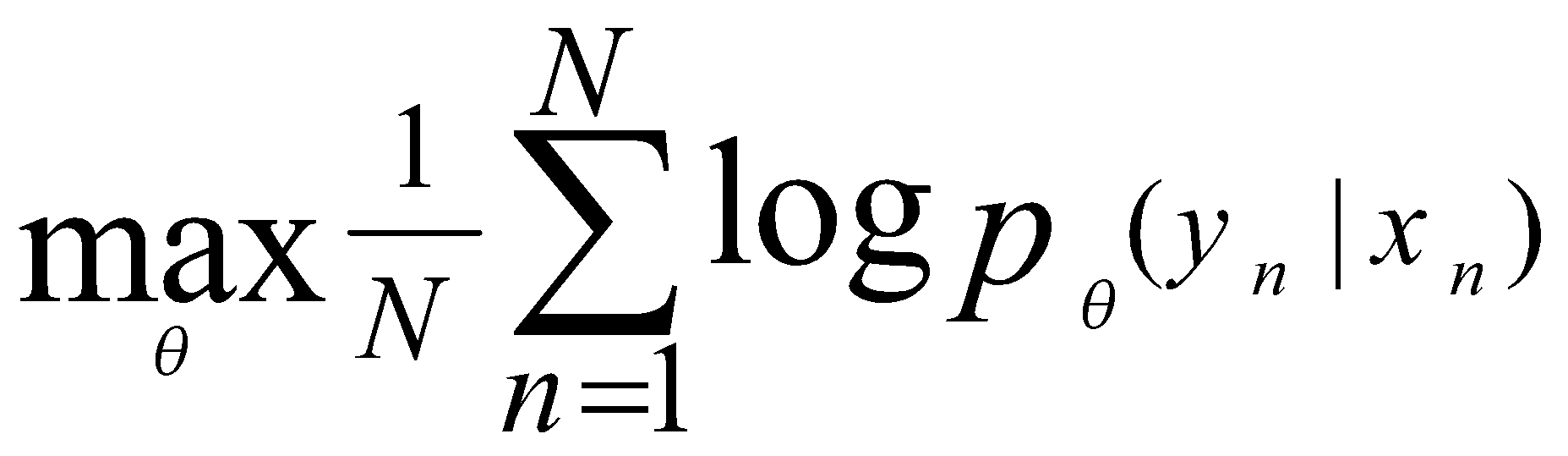
θ مجموعه پارامترهای مدل را مشخص میکند و هر جفت (xn,yn) یک دنباله ورودی و خروجی از مجموعه آموزش را نشان میدهد. از آنجاییکه خروجی کدگشا مشتقپذیر است، میتوان از یک الگوریتم مبتنیبر گرادیان برای تخمین پارامترهای مدل استفاده کرد.
با آموزش کامل RNNencdec، میتوان از مدل به دو روش استفاده کرد. روش اول، استفاده از مدل برای تولید یک دنباله هدف با توجه به یک دنباله ورودی است. روش دیگر، استفاده از مدل برای امتیازدهی به یک جفت دنباله ورودی و خروجی است، که در این حالت، امتیاز همان احتمال ![]() است که از روابط (2) و (5) بهدست میآید.
است که از روابط (2) و (5) بهدست میآید.
واحد پنهانی که بهطور تطبیقی به یاد میآورد و فراموش میکند
RNNencdec علاوه براین که در سال 2014 ساختار جدیدی برای مدلهای کدگزار-کدگشا در حوزهی ترجمه ماشینی عصبی ارائه داد، یک نوع واحد پنهان جدید (f در فرمول 1) را نیز معرفی کرد که امروزه آن را با نام GRU میشناسیم. GRU از واحد LSTM الهام گرفته شده، اما محاسبات و پیادهسازی سادهتری دارد. شکل 2 نمایش گرافیکی GRU را نشان میدهد در پست RNN ، مدل GRU مفصل توضیح داده شدهاست.
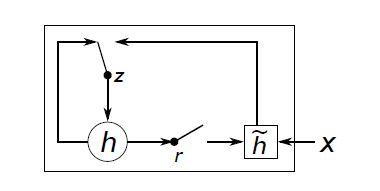
 بهروز شود یا خیر. دروازه تنظیم مجدد r تصمیم میگیرد که آیا حالت پنهان قبلی نادیده گرفته شود یا خیر. (برای جزئیات بیشتر به فرمولهای (6)و(7) مراجعه کنید.)
بهروز شود یا خیر. دروازه تنظیم مجدد r تصمیم میگیرد که آیا حالت پنهان قبلی نادیده گرفته شود یا خیر. (برای جزئیات بیشتر به فرمولهای (6)و(7) مراجعه کنید.)GRU دارای دو دروازه بهروزرسانی z و دروازه تنظیم مجدد r میباشد. ( با مراجعه به پست RNNها، با جزئیات GRU آشنا شوید.) در GRU، تابع فعالسازی واحد پنهان hj به شکل زیر محاسبه میشود:
(6) ![]()
(7) ![]()
براساس فرمولهای 6 و 7، زمانیکه دروازه تنظیم مجدد به صفر میل کند، وضعیت پنهان فعلی مجبور به نادیده گرفتن وضعیت پنهان قبلی شده و با داده ورودی جدید تنظیم مجدد میشود. این رویکرد به وضعیت پنهان اجازه میدهد تا هر گونه اطلاعاتی را که در آینده نامرتبط تشخیص داده میشود، حذف کند و یک بازنمایی کوچکتر از اطلاعات داشته باشد.
از سوی دیگر، دروازه بهروزرسانی جریان انتقال اطلاعات از وضعیت پنهان قبلی به وضعیت پنهان فعلی را کنترل میکند. عملکرد این واحد مشابه با سلول حافظه در شبکه LSTM است و به RNN کمک میکند تا اطلاعات بلندمدت را بهخاطر بسپارد.
از آنجاییکه هر واحد پنهان، دروازه تنظیم مجدد و بهروزرسانی جداگانه دارد، در مقیاسهای زمانی متفاوتی نیز وابستگیها را یاد میگیرد. در واحدهای پنهانی که وابستگیهای کوتاهمدت را شناسایی میکنند، دروازههای تنظیم مجدد و در واحدهای پنهانی که وابستگیهای بلندمدت را شناسایی میکنند، دروازههای بهروزرسانی بهطور مکرر فعال هستند. در آزمایشات اولیه این مقاله، پژوهشگران دریافتند که استفاده از واحدهای GRU بسیار حیاتی است و بدون استفاده از آنها دستیابی به نتایج معنادار غیرممکن است.
ترجمه ماشینی آماری (SMT)
در سیستم SMT (بهخصوص جزء کدگشا) هدف پیدا کردن ترجمه f برای جمله مبدأ e است، بهطوریکه فرمول زیر را بیشینه کند:
(8) ![]()
اگر چه در عمل، بیشتر سیستمهای SMT لگاریتم احتمال را بهجای خود آن، بهصورت یک مدل لگاریتم-خطی، با ویژگیها و وزنهای اضافهتر فرمول میکنند:
(9) 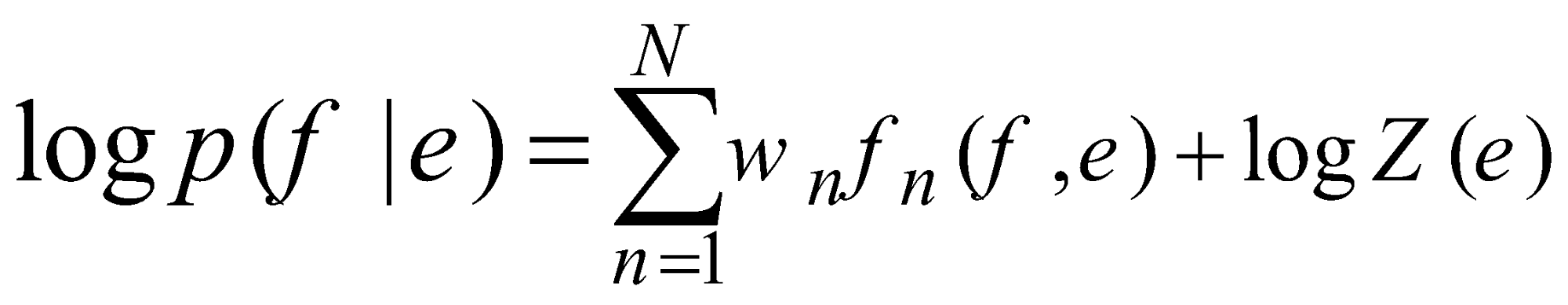
در فرمول 9، fn و wn بهترتیب نشاندهنده n-امین ویژگی و وزن مربوط به آن ویژگی هستند و Z(e) یک ضریب نرمالسازی مستقل از وزنها است. وزنها معمولاً با توجه به حداکثر کردن امتیاز BLEU روی مجموعه دادهی توسعه بهینهسازی میشوند.
در مدل SMT مبتنیبر عبارت، مدل ترجمه ![]() به احتمالِ ترجمه عبارتهایی که در ورودی و خروجی با هم جفت میشوند، تجزیه میشود. این احتمالاتِ ترجمه بهعنوان ویژگیهای اضافی در مدل لگاریتم-خطی مورد استفاده قرار گرفته (مطابق با فرمول 9) و با توجه به حداکثر کردن امتیاز BLEU ، وزندهی میشوند.
به احتمالِ ترجمه عبارتهایی که در ورودی و خروجی با هم جفت میشوند، تجزیه میشود. این احتمالاتِ ترجمه بهعنوان ویژگیهای اضافی در مدل لگاریتم-خطی مورد استفاده قرار گرفته (مطابق با فرمول 9) و با توجه به حداکثر کردن امتیاز BLEU ، وزندهی میشوند.
از زمان معرفی مدل زبانی شبکه عصبی در سال 2003، شبکههای عصبی بهطور گستردهای در سیستمهای SMT و برای ارزیابی مجدد فرضیههای ترجمه استفاده شدهاند. با این حال از سال 2012، علاقهای به آموزش شبکههای عصبی برای امتیازدهی به جمله ترجمهشده (یا جفت عبارات) با استفاده از بازنمایی جمله مبدأ بهعنوان یک ورودی اضافی در سیستم، در میان محققان بهوجود آمد.
امتیازدهی جفت عبارتها
پژوهشگران RNNencdec را با استفاده از جفت عبارتهای متناظر، آموزش دادند. آنها امتیازهای حاصل از مدل را، بهعنوان یک ویژگی به مدل لگاریتم-خطی (معادله 9) اضافه کردند و از آن برای تنظیم کردن کدگشای SMT استفاده کردند. در هنگام آموزش RNNencdec، پژوهشگران فراوانیهای (نرمالشده) هر جفت عبارت را در پیکره متن اصلی به دو دلیل زیر نادیده گرفتند:
- هزینه محاسباتیِ انتخاب تصادفی جفت عبارتها از یک جدول عبارت بزرگ با توجه به فراوانیهای نرمالشده کاهش مییابد.
- برای اطمینان از اینکه شبکهی عصبی بازگشتی کدگذار-کدگشا رتبهبندی جفت عبارتها را صرفاً براساس تعداد رخداد آنها یاد نمیگیرد.
با انجام این کار مدل به جای رتبهبندی جفت عبارات براساس فراوانی، بیشتر بر روی الگوهای یادگیری زبان تمرکز میکند؛ تا بتواند بین ترجمههای قابل قبول و غیر قابل قبول تمایز قائل شود و محدودهای که در آن، احتمال ترجمههای قابل قبول بیشتر است یعنی "منطقه تمرکز احتمال" را بیاموزد. با توجه به اینکه ترجمههای مختلفی برای هر جمله وجود دارد، این محدوده نشان میدهد کدام ترجمهها احتمال درستی بیشتری دارند. با یادگیری این محدوده و تمرکز بر ترجمههای قابل قبول، مدل قادر خواهد بود ترجمههای بهتری را تولید کند.
پس از آموزش مدل RNNencdec، یک امتیاز جدید برای هر جفت عبارت به جدول عبارات اضافه میشود. با این روش، اضافه کردن امتیاز جدید به الگوریتم تنظیم موجود با کمترین هزینهی محاسباتی انجام خواهد شد. براساس پژوهش شونک در سال 2012، امکان جایگزینی کامل جدول عبارات با RNNencdec وجود دارد. در این صورت، لازم است RNNencdec برای یک عبارت مبدأ دادهشده، لیستی از عبارات هدف را تولید کند که این کار به اجرای مکرر یک رویکرد گران نمونهبرداری نیاز دارد. به همین دلیل در این مقاله، فقط امتیازدهی مجدد به جفت عبارتها در جدول عبارات در نظر گرفته شده است.
آزمایشات
RNNencdec در ترجمه WMT’14 انگلیسی/فرانسوی ارزیابی شد. نتایج آزمایش مدل در ادامه بررسی شده اند.
دادهها و سیستم پایه
منابع زیادی برای ایجاد یک سیستم SMT انگلیسی/فرانسوی در دسترس است. از جمله مجموعه دادههای دوزبانه موارد زیر میباشند:
- یوروپال
- تفسیر اخبار
- دادههای سازمان ملل
- خزش در وب
با استفاده از منابع فوق، مجموعه دادههای مختلفی ساخته شدهاست که در این مدل از مجموعههای newstest2012 و newstest2013 برای آموزش مدل و از مجموعه newstest2014 بهعنوان مجموعه تست استفاده شدهاست.
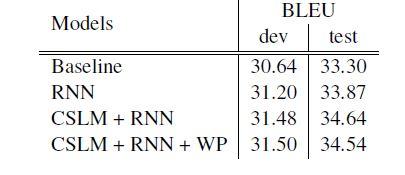
برای آموزشRNNencdec ، پژوهشگران مجموعه واژگان مبدأ و هدف را به متداولترین 15هزار کلمه در هر دو زبان انگلیسی و فرانسوی محدود کردند، که تقریباً 93٪ از مجموعه داده را پوشش میدهد. تمام کلمات خارج از مجموعه واژگان به یک توکن خاص ([UNK]) نگاشت شدند. سیستم SMT مبتنی بر عبارات بهعنوان سیستم پایه انتخاب شده و برای ساخت این سیستم از موزس با تنظیمات پیشفرض استفاده شدهاست. مطابق شکل 3، امتیاز BLEU برای این سیستم در مجموعه دادههای توسعه و تست به ترتیب 30.64 و 33.3 (نشان دهنده دقت قابل توجه) است.
تنظیم پارامترهای مدل
RNNencdec در این آزمایش 1000 واحد GRU در کدگذار و کدگشا دارد. ماتریس ورودی بین هر نماد ورودی x(t) و واحد پنهان با دو ماتریس با رتبه پایینتر تقریب شده است. به این معنی که مدل بهجای استفاده از یک ماتریس بزرگ برای بازنمایی ورودی، از دو ماتریس کوچکتر با رتبه پایینتر استفاده کرده است. این تقریب برای کاهش تعداد پارامترهای مدل و کمک به مقیاس بهتر آن در مجموعه دادههای بزرگتر استفاده میشود تا هم دقت آن حفظ شود و هم حافظه مورد نیاز مدل نیز کاهش یابد. همچنین، ماتریس خروجی نیز بهطریق مشابه محاسبه میگردد.
دراین مدل ماتریسهای رتبه 100 استفاده شدهاست که معادل یادگیری بردار تعبیه با ابعاد 100 برای هر کلمه است. تابع فعالسازی مورد استفاده برای ![]() که در معادله (7) آورده شده، یک تابع تانژانت هیپربولیک است. مطابق با مقاله پاسکانا در سال 2014، این شبکه دارای یک لایه میانی است که شامل 500 واحد Maxout است و هر واحد در آن دو ورودی را با استفاده از تکنیک پولینگ در یکدیگر ادغام میکند.
که در معادله (7) آورده شده، یک تابع تانژانت هیپربولیک است. مطابق با مقاله پاسکانا در سال 2014، این شبکه دارای یک لایه میانی است که شامل 500 واحد Maxout است و هر واحد در آن دو ورودی را با استفاده از تکنیک پولینگ در یکدیگر ادغام میکند.
تمام پارامترهای وزن درRNNencdec به جز پارامترهای وزن بازگشتی، با نمونهبرداری از توزیع گوسی با میانگین صفر و انحراف استاندارد 0.01 مقداردهی اولیه شدهاند. برای آموزش RNNencdec در این مقاله از الگوریتم آدادلتا و گرادیان نزولی تصادفی استفاده شدهاست. در هر بروزرسانی، 64 جفت عبارت تصادفی از یک جدول عبارات (که از 348 میلیون کلمه تشکیل شده) استفاده شد و مدل تقریباً برای سه روز آموزش دیده است.
مدل زبانی عصبی
RNNencdec ، با مدل CSLM مقایسه شدند. CSLM یک مدل زبانی مبتنی بر شبکههای عصبی است که با یادگیری زبان در سطوح مختلف به مدلسازی مفاهیم زبانی در دو زبان مبدأ و هدف میپردازد. آنها مقایسهای بین سیستم SMT با استفاده از CSLM و با استفاده از رویکردRNNencdec انجام دادند، تا بررسی کنند که آیا استفاده از چندین شبکه عصبی در قسمتهای مختلف سیستم ترجمه ماشینی، منجر به بهبود کارایی سیستم میشود یا خیر؟
تحلیل کمی
برای تحلیل کمی پژوهشگران پیکربندیهای مختلفی را آزمایش کردهاند که نتایج آن در شکل 3 قابل مشاهده است. با توجه به نتایج بهدست آمده، اضافه کردن ویژگیهای یاد گرفته شده توسط شبکههای عصبی به SMT، عملکرد مدل را نسبت به حالت پایه بهبود میدهد. بهترین عملکرد مربوط به پیکربندیای است که از هر دو CSLM و امتیازهای عبارت RNNencdec در SMT استفاده کردهاست. این نشان میدهد که مشارکت CSLM وRNNencdec زیاد با هم همبستگی ندارند و با بهبود هر روش بهصورت مستقل، نتایج بهبود خواهند یافت.
علاوه بر این، پژوهشگران سعی کردند کلمات ناشناخته (کلماتی که در لیست نیستند) استفاده شده در عبارتهای ترجمه شده توسط مدل را جریمه کنند. آنها این کار را با اضافه کردن تعدادی کلمات ناشناخته بهعنوان یک ویژگی اضافی در مدل لگاریتم-خطی در معادله 9 پیادهسازی کردند. با این وجود، مدل عملکرد بهتری در مجموعه تست بهدست نیاورد.
تحلیل کیفی
به منظور درک بهتر چگونگی بهبود عملکرد در مدل، پژوهشگران امتیازات جفت عبارات محاسبهشده توسطRNNencdec را در برابر p(f|e) متناظر آن از مدل ترجمه قرار دادند. مدل ترجمه، جفت عبارات را براساس تعداد رخداد آنها در پیکره متن اصلی امتیازدهی میکند. در نتیجه انتظار میرود که برای عبارات متداول، امتیازات بالاتر و برای عبارات نادر، امتیازات پایینتری تخمین بزند. در مقابل ازRNNencdec ، که بدون اطلاع از فراوانی رخداد عبارات آموزش داده میشود، انتظار میرود که عبارات را براساس قواعد زبانی و نه براساس فراوانی رخداد آنها در متن امتیازدهی کند. به این ترتیب، پژوهشگران میخواهند مدل RNNencdec را به گونهای آموزش دهند که بهجای توجه به فراوانیهای آماری، به قواعد زبانی توجه کند و ترجمههای دقیقتری ارائه دهد.
در این مقاله پژوهشگران روی جفتهایی تمرکز کردند که عبارت مبدأ آنها طولانی (بیش از 3 کلمه) و فراوانی آنها نیز زیاد است. برای چنین عبارت مبدأیی، آنها به عبارات هدفی نگاه میکنند که احتمال ترجمه p(f|e) یا امتیاز RNNencdec بالایی را کسب کردهاند. بهطور مشابه، آنها با جفتهایی که عبارت مبدأ آنها طولانی است اما در پیکره متنی کمتر ظاهر شدهاند نیز، همین روند را تکرار کردند.
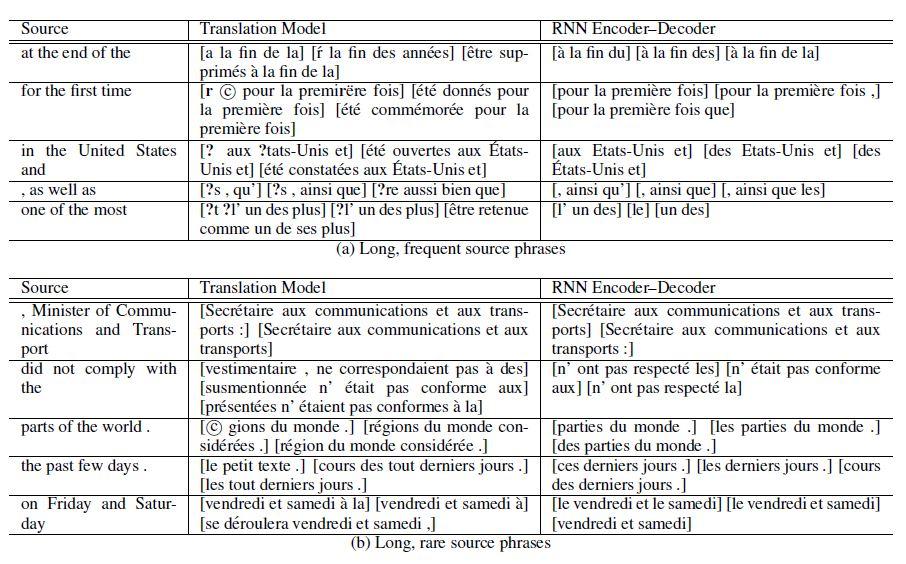
شکل 4، فهرستی از سه ترجمه برتر برای هر عبارت مبدأ با استفاده از مدل ترجمه وRNNencdec را نشان میدهد. عبارات مبدأ بهطور تصادفی از بین عبارات طولانی (بیش از 4 یا 5 کلمه)، انتخاب شدهاند. در اکثر موارد، ترجمههای انتخاب شده توسط RNNencdec به ترجمههای واقعی یا تحت اللفظی نزدیکتر هستند. مطابق با شکل 5، در مجموع RNNencdec در ترجمههای کوتاهتر عملکرد بهتری دارد.
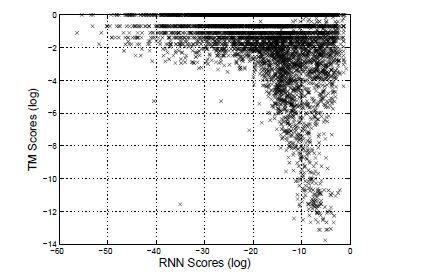
مطابق شکل 5، بسیاری از جفت عبارات به یک اندازه توسط هر دو مدل ترجمه و RNNencdec امتیاز گرفتند، اما تعدادی از جفت عبارات با نمرات کاملاً متفاوت امتیاز گرفتند. همانطور که در ابتدا توضیح داده شد، این ممکن است ناشی از رویکرد پیشنهادی آموزشRNNencdec با استفاده از مجموعهای از جفت عبارات منحصربهفرد باشد که RNNencdec را از صرفا یادگیری فراوانی جفت عبارات در پیکره باز میدارد.
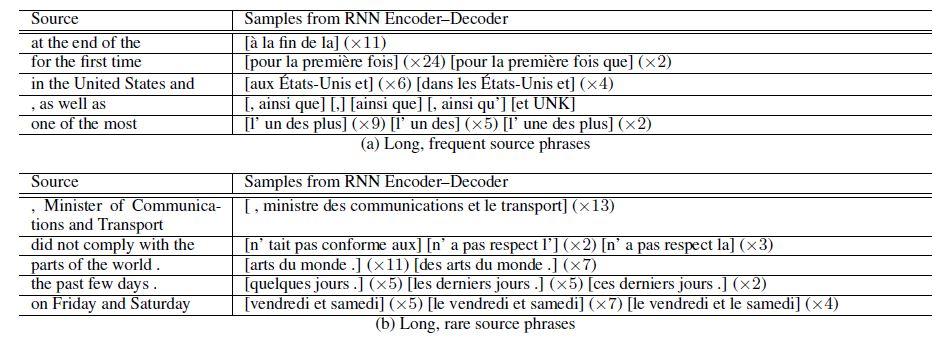
علاوه بر این شکل 6، نمونههای تولید شده توسط RNNencdec برای هر یک از عبارات مبدأ در شکل 4 را نشان میدهد. برای هر عبارت مبدأ، پژوهشگران 50 نمونه تولید کرده و پنج عبارت برتر را براساس امتیازشان نمایش دادهاند. طبق نتایج، RNNencdec عبارات هدف مناسبی را بدون توجه به جدول عبارات واقعی پیشنهاد میدهد. مهمتر اینکه، عبارات تولیدشده بهطور کامل با عبارات هدف از جدول عبارات همپوشانی ندارند. این امر پژوهشگران را تشویق کرده تا امکان جایگزینی کل جدول عبارات یا یک بخشی از آن با RNNencdec پیشنهادی را در آینده بررسی کنند.
بازنمایی کلمات و عبارات
از آنجاییکهRNNencdec پیشنهادی بهطور خاص فقط برای ترجمه ماشینی طراحی نشده است، در این بخش بهطور مختصر به ویژگیهای دیگر این مدل میپردازیم.
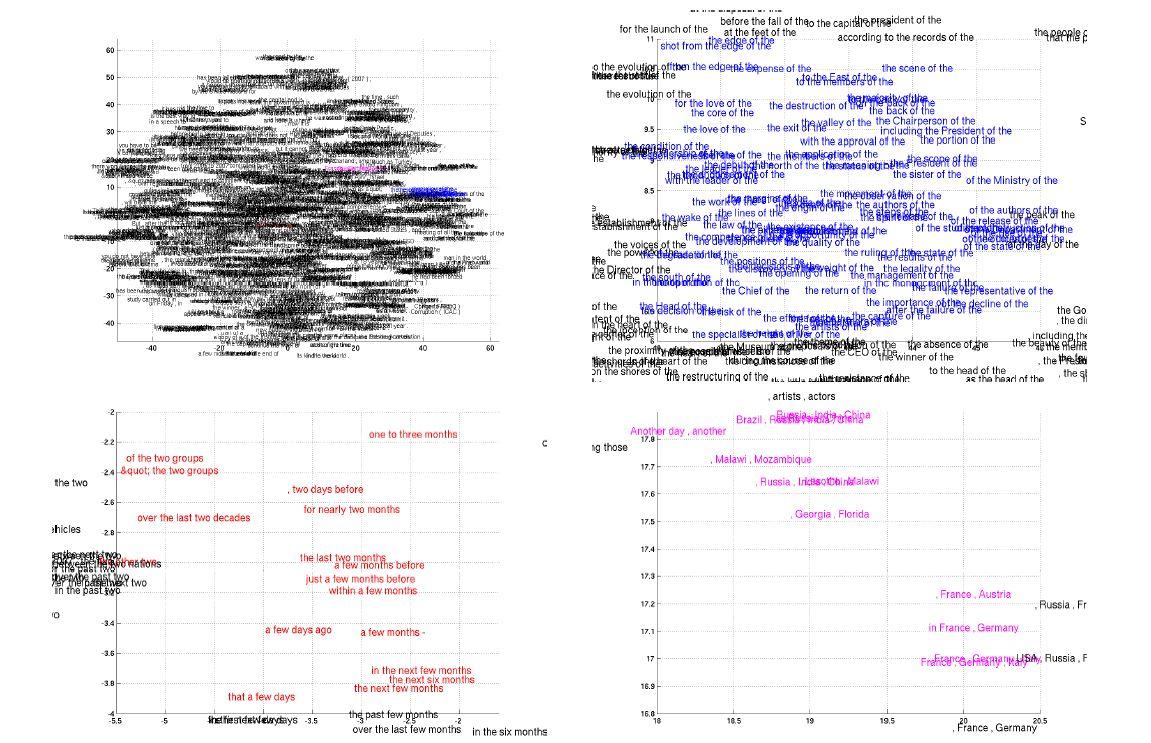
از سال 2003، مدلهای زبانی آموخته شده با شبکههای عصبی، در فضای پیوسته به یادگیری تعبیههای معنایی میپردازند. از آنجاییکهRNNencdec نیز عبارات را به یک فضای برداری پیوسته نگاشت میکند و برعکس، پژوهشگران انتظار داشتند که یک خاصیت مشابه را در مدل پیشنهادی مشاهده کنند. نمودار سمت چپ در شکل 7، توزیع دوبعدی کلمات آموخته شده درRNNencdec را نشان میدهد. بهوضوح قابل مشاهدهاست که کلمات با معنای مشابه به هم نزدیک هستند و با هم خوشهبندی شدهاند (مشاهده نمودارهای بزرگ شده در شکل 7).
بهصورت طبیعیRNNencdec یک بازنمایی از عبارت را در فضای پیوسته تولید میکند. در این مورد، بازنمایی (c در شکل 1) یک بردار 1000 بُعدی است. مشابه با بازنمایی کلمات، پژوهشگران بازنمایی از عباراتی را که شامل چهار کلمه یا بیشتر هستند، در شکل 7 تصویرسازی کردهاند.
براساس این تصویرسازی، به وضوح مشخص است کهRNNencdec ساختارهای معنایی و نحوی عبارات را درک میکند. بهعنوان مثال، در نمودار پایین سمت چپ، بیشتر عبارتها درباره مدت زمان هستند، در حالیکه عبارتهایی که از لحاظ نحوی مشابهاند، در کنار هم خوشهبندی شدهاند. نمودار پایین سمت راست، خوشهبندی عبارتهایی (کشورها یا مناطق) را نشان میدهد که معنایی مشابه دارند. علاوه بر این، نمودار بالا سمت راست عبارتهایی را نشان میدهند که از نظر نحوی مشابه هستند.
جمعبندی
ساختار RNNencdec به دلیل استفاده از GRU تحول بزرگی در حوزهی ترجمههای ماشینی عصبی در سال 2014 ایجاد کرد. RNNencdec یک ساختار جدید برای شبکههای عصبی پیشنهاد کرد که میتوانست نگاشتی از یک دنباله با طول دلخواه را به یک دنباله دیگر با طول دلخواه یاد بگیرد. علاوه بر معماری جدید شبکهی عصبی، در این مدل یک واحد پنهان جدید به نام GRU معرفی شد که شامل یک دروازه تنظیم مجدد و یک دروازه بهروزرسانی است. این دروازهها بهصورت تطبیقی کنترل میکنند که هر واحد پنهان در هنگام خواندن یا تولید یک دنباله چقدر به یاد آورد یا فراموش کند.
اولین بار از RNNencdec برای امتیازدهی به جفت عبارتها در جدول عبارات و از امتیاز بهدست آمده به عنوان یک ویژگی جدید در مدل SMT استفاده شد. از نظر کیفی، مدلRNNencdec توانست قواعد زبانی در جفت عبارتها را بهخوبی درک کند و عبارات هدف متناسبی را پیشنهاد دهد. از طرف دیگر، استفاده از امتیازهای محاسبه شده توسطRNNencdec عملکرد کلی ترجمه از نظر امتیازات BLEU را بهبود داد. همچنین از آنجایی که مدل آموزش دیده قابلیت درک الگوهای زبانی در سطوح مختلف کلمه و عبارت را داشت، پس از آن در کاربردهای مختلف زبان طبیعی به کار گرفته شد.

نظرات