از کلمات تا بردارها (3): تاثیر مدل elmo بر nlp
ترجمه مریم سادات هاشمی از مقاله the effect of elmo model on nlp

از کلمات تا بردارها (3): تاثیر مدل ELMo بر NLP
-
مقدمه
در پستهای قبلی دو مدل تعبیۀ کلمات[1] Word2Vec و GloVe را بهطور کامل بررسی کردیم. در این پست میخواهیم مدل ELMo را معرفی کنیم که یکی دیگر از مدلهای تعبیۀ کلمات در پردازش زبان طبیعی[2] (NLP) است.
سال ۲۰۱۸ یک نقطه عطف بزرگ برای مدلهای زبانی[3] در زمینه پردازش زبان طبیعی[4] بود. در این سال، جامعۀ پردازش زبان طبیعی مدلهای زبانی بسیار قدرتمندی را معرفی کردند که در مدلها و وظایف مختلف کارایی داشتند. از سال 2018 در پردازش زبان طبیعی بهعنوان سال ImageNet NLP یاد میشود. زیرا اهمیت تحولاتی که در این سال رخ داد، مشابه تغییراتی است که توسعه ImageNet در حوزه بینایی کامپیوتر ایجاد کرد. یکی از مهمترین اتفاقات در سال 2018، ارائه مدل ELMo[5] توسط محققان مؤسسۀ آلن[6] بود. مدل ELMo بر اساس بازنمایی عمیق کلمات متنی[7] است و نوآوری کلیدی آن، توانایی در به تصویر کشیدن معنای کلمات با در نظر گرفتن کلمات اطراف آن در متن است. این امر، مدل ELMo را برای کارهای مختلف پردازش زبان طبیعی، مانند تجزیه و تحلیل احساسات[8]، تشخیص موجودیتهای نامدار[9] و ترجمه ماشینی[10] مفید میکند.
ELMo از یک شبکه LSTM دوطرفه[11] برای ایجاد تعبیۀ کلمات استفاده میکند. بر خلاف تعبیههای سنتی مانند Word2Vec یا GloVe، که یک بازنمایی ایستا[12] و ثابت از کلمات را ارائه میکنند، تعبیههای ELMo پویا[13] و وابسته به متن ورودی هستند. این موضوع به این معنی است که یک کلمه میتواند در متنهای مختلف معانی و تعبیههای متفاوتی داشته باشد. برای مثال کلمه «شیر» در جملات «من هر روز سه لیوان شیر میخورم»، «شیر آب چکه میکند» و «شیر سلطان جنگل است» معانی مختلفی دارد و مدل ELMo بردارهای تعبیۀ متفاوتی را برای کلمه «شیر» در هر یک از این جملهها تولید میکند. در این حالت اصطلاحاً میگوییم که تعبیههای مدل ELMo حساس به متن[14] هستند. علاوه بر این، مدل ELMo بر روی تقریباً یک میلیارد کلمه آموزش داده شده؛ در نتیجه دانش زبانی خوبی را به دست آوردهاست. مدل ELMo بهطور گسترده در بسیاری از مسئلههای پردازش زبان طبیعی مورداستفاده قرار گرفت و راه را برای توسعه مدلهای پیشرفتهتر مانند BERT و GPT هموار کرد. در ادامه این مطلب جزئیات مدل ELMo را شرح میدهیم.
-
مدل ELMo
مدل ELMo یک مدل زبانی است که احتمال کلمه بعدی را با توجه به کلمات قبلی در ورودی پیشبینی میکند. اساس معماری مدل ELMo دو لایه LSTM دوطرفه است که پشت سر هم قرار گرفتهاند. این موضوع در شکل 1 نشان داده شدهاست. LSTM دوطرفه از دو بخش LSTM روبهجلو[15] و LSTM روبهعقب[16] تشکیل شده. LSTM روبهجلو کلمات را از چپ به راست پردازش میکند، یا بهعبارتدیگر، کلمه هدف را با توجه به کلمات قبل از آن پیشبینی میکند. در مقابل، LSTM روبهعقب کلمات را از راست به چپ میخواند و کلمه هدف را با توجه به کلمات پس از آن در خروجی تولید میکند.
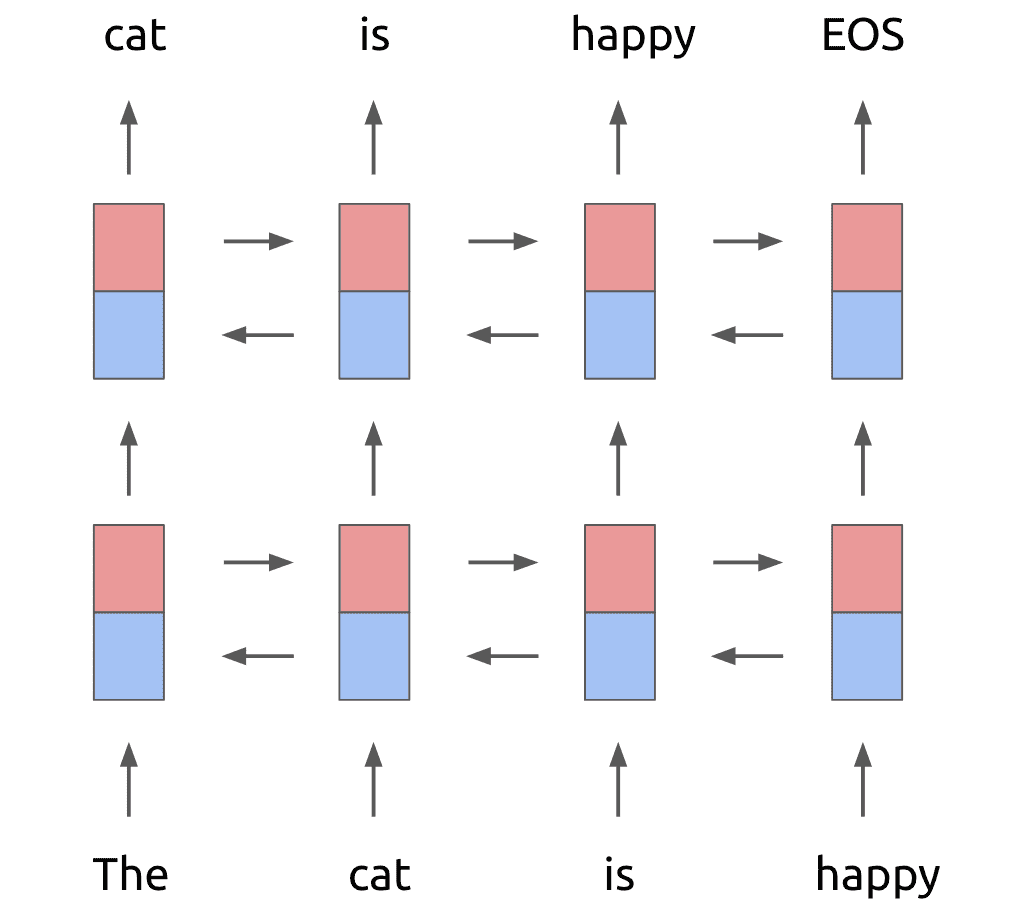
شکل 1: دو لایه LSTM دوطرفه. رنگ قرمز نشاندهنده LSTM روبهجلو و رنگ آبی نشاندهندۀ LSTM روبهعقب است.
علاوه بر این، یک اتصال باقیمانده[17] بین لایه اول و دوم اضافه میشود. همانطور که میدانید اتصال باقیمانده به مدلهای عمیق کمک میکند تا در طول آموزش دچار مشکلاتی از قبیل محوشدگی یا انفجار گرادیان[18] نشوند. این امر در شکل 2 نشان داده شدهاست.
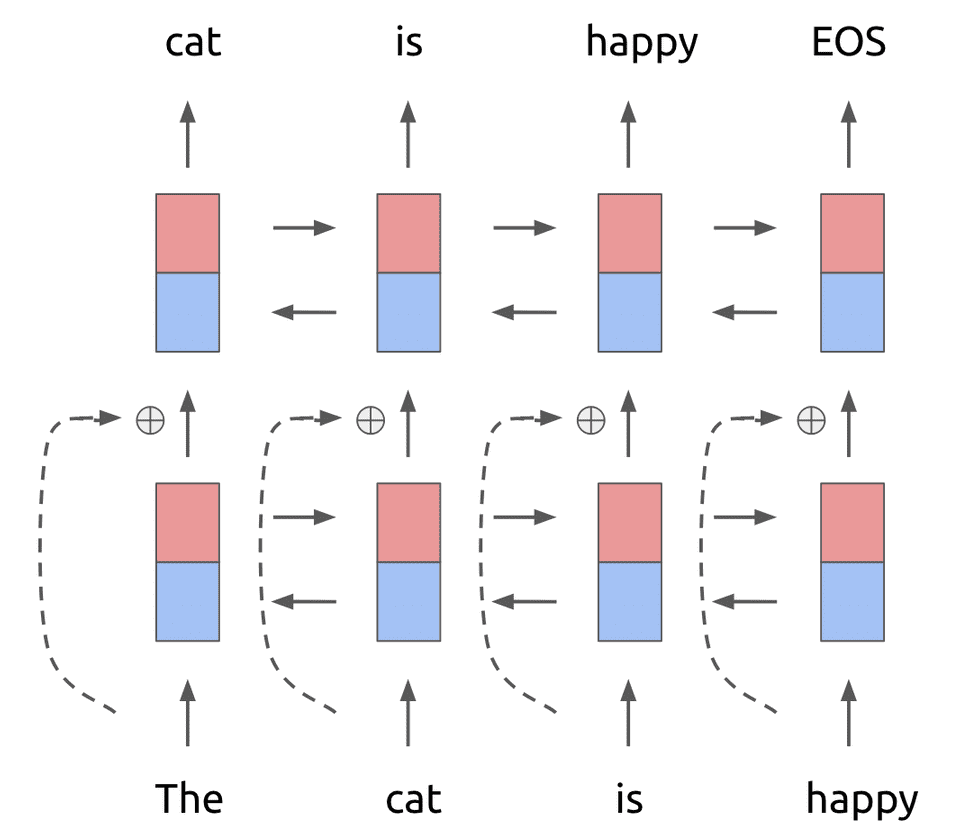
شکل 2: یک اتصال باقیمانده بین لایههای اول و دوم LSTM اضافه میشود. ورودی لایه اول قبل از اینکه بهعنوان ورودی به لایۀ دوم منتقل شود به خروجی آن اضافه میشود.
در مدلهای زبانی سنتی، هر توکن در لایه ورودی، به یک بردار تعبیۀ کلمه با طول ثابت تبدیل میشود که به دو روش مختلف میتوان این کار را انجام داد. روش اول این است که یک ماتریس تعبیۀ کلمات با مقداردهی اولیه تعریف کرد که اندازه آن برابر با تعداد واژگان در بُعد تعبیه باشد. روش دوم استفاده از تعبیههای از پیش آموزشدیده مانند مدل GloVe است که برای هر کلمه بردارهای تعبیه مشخصی را ارائه میدهد.
اما مدل زبانی ELMo از هیچکدام از این روشها استفاده نمیکند و بهجای آن، ابتدا هر توکن را با استفاده از تعبیه کاراکترها به یک بازنمایی مناسب تبدیل میکند. سپس این تعبیه کاراکترها به یک لایه پیچشی و یک لایه max-pool ورودی داده میشود. در نهایت این بردارهای تعبیه، از یک شبکه Highway با 2 لایه عبور میکند. این فرایند برای توکن «The» در شکل 3 نمایش داده شدهاست.
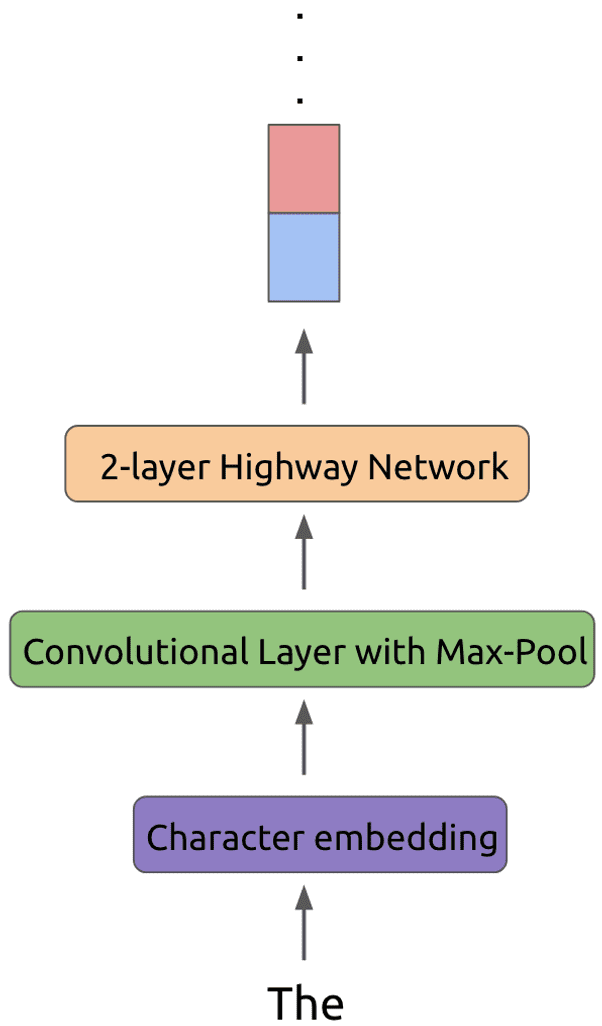
شکل 3: عملیاتی که بر روی هر توکن قبل از ورود به لایه اول LSTMانجام میشود.
استفاده از این روش برای تولید بردارهای تعبیه مزیتهایی دارد. یکی از این مزیتها این است که میتوان حتی برای کلمات خارج از واژگان نیز، یک بردار تعبیه کلمات معتبر ایجاد کرد. علاوه بر این، استفاده از فیلترهای پیچشی این امکان را فراهم میکنند که با درنظرگرفتن n-gramهای مختلف، بازنماییهای قویتری برای هر توکن ایجاد شود. همچنین شبکه Highway به انتقال راحتتر اطلاعات از طریق ورودی کمک میکند.
تا به اینجا، معماری مدل ELMo هیچ برتری خاصی نسبت به مدلهای گذشته
نداشتهاست. جایی که ELMo گام بلندی برمیدارد، در نحوه استفاده از مدل پس از
آموزش است. برای توضیح این امر، کلمه kام در ورودی را در نظر بگیرید. مدل ELMo
بردار بازنمایی کلمه k (![]() ) و بردارهای بازنمایی بهدستآمده از دو لایه LSTM (
) و بردارهای بازنمایی بهدستآمده از دو لایه LSTM (![]() و
و ![]() ) را بهصورت وزندار با هم ترکیب میکند. شکل
4 این موضوع را نشان میدهد.
) را بهصورت وزندار با هم ترکیب میکند. شکل
4 این موضوع را نشان میدهد.
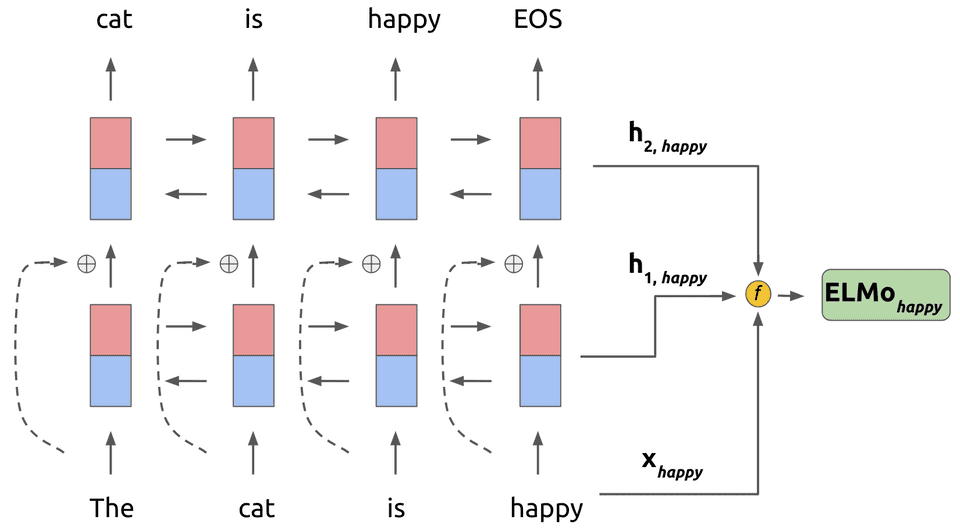
شکل 4: ترکیب بازنمایی کلمه «happy» در ورودی و بردارهای خروجی از لایههای LSTM دوطرفه برای به دست آوردن بردار تعبیه این کلمه از مدل ELMo.
در شکل 4، تابع f عملیات زیر را برای ترکیب بردارهای بازنمایی کلمه k انجام میدهد:
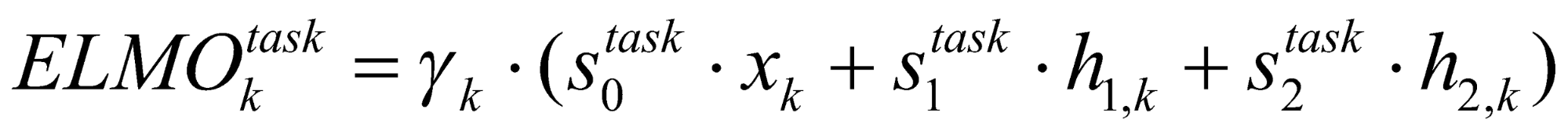
که در آن، ![]() وزنهای نرمالشده با softmax در بازنماییهای پنهان از مدل را نشان
میدهد و
وزنهای نرمالشده با softmax در بازنماییهای پنهان از مدل را نشان
میدهد و ![]() نشاندهندۀ یک ضریب مقیاس متناسب با هر وظیفه است. توجه داشته باشید
که مدل ELMo برای هر وظیفه (پرسشوپاسخ، تجزیهوتحلیل احساسات و غیره) یک بازنمایی جداگانه یاد میگیرید.
و در واقع بردار تعبیۀ کلمات بهدستآمده از مدل ELMo ترکیبی از بردارهای بازنمایی لایههای میانی مدل
BiLM است.
نشاندهندۀ یک ضریب مقیاس متناسب با هر وظیفه است. توجه داشته باشید
که مدل ELMo برای هر وظیفه (پرسشوپاسخ، تجزیهوتحلیل احساسات و غیره) یک بازنمایی جداگانه یاد میگیرید.
و در واقع بردار تعبیۀ کلمات بهدستآمده از مدل ELMo ترکیبی از بردارهای بازنمایی لایههای میانی مدل
BiLM است.
برای استفاده از مدل ELMo در یک وظیفه خاص، ابتدا مدل زبانی آموزش
میبیند. سپس وزنهای مدل زبانی منجمد میشود و مدل با استفاده از عبارت فاینتیون میشود. در نهایت برای
هر کلمه با توجه به آن وظیفه یک بردار تعبیه به دست میآید. همانطور که مشخص است، فاکتورهای وزنی ![]() و
و ![]() در حین فاینتیونینگ برای هر وظیفۀ خاص آموخته میشود.
در حین فاینتیونینگ برای هر وظیفۀ خاص آموخته میشود.
-
نتیجهگیری
در این پست مدل تعبیه کلماتELMo را معرفی کردیم. نوآوری کلیدی مدل ELMo این است که برای هر کلمه، با توجه به معنایی که در متن دارد، بردار تعبیه ایجاد میکند. این موضوع در تضاد با مدلهای سنتی تعبیۀ کلمات است که یک بازنمایی واحد و ثابت برای هر کلمه ارائه میکردند. در پستهای آینده با مدلهای قدرتمندتری برای ایجاد تعبیۀ کلمات آشنا خواهیم شد.
-
منابع
https://arxiv.org/pdf/1802.05365.pdf
https://www.mihaileric.com/posts/deep-contextualized-word-representations-elmo/
[1] Word Embedding
[2] Natural Language Processing
[3] Language Model
[4] Natural Language Processing
[5] Embeddings from Language Models
[6] Allen Institute
[7] Deep Contextualized Word Representations
[8] Sentiment Analysis
[9] Name Entity Recognition
[10] Machine Translation
[11] Bidirectional
[12] Static Representation
[13] Dynamic
[14] context-sensitive
[15] Forward LSTM
[16] Backward LSTM
[17] Residual Connection
[18] Vanishing or Exploding Gradient

نظرات