از کلمات تا بردارها (2): کشف رازهای مدل تعبیه کلمات glove
ترجمه مریم سادات هاشمی از مقاله global vectors for word representation

مقدمه
در پست قبلی مدل تعبیه کلمات Word2Vec را به طور کامل بررسی کردیم. در این پست میخواهیم یکی دیگر از معروفترین مدلهای تعبیه کلمات در پردازش زبان طبیعی به نام GloVe را معرفی کنیم. GloVe مخفف Global Vectors است که مدلی برای بازنمایی توزیع شده کلمات است. این مدل یک الگوریتم یادگیری بدون نظارت را برای بهدستآوردن بازنمایی برداری کلمات ارائه میکند. مدل GloVe بهعنوان یک پروژه منبعباز در استنفورد توسعه یافت و در سال 2014 راهاندازی شد. این مدل ویژگیهای دو روش فاکتورگیری سراسری ماتریسی و پنجره متن محلی را ترکیب میکند. مزیت GloVe این است که برخلاف مدل Word2vec، برای بهدستآوردن تعبیه کلمه هدف، فقط به کلمات اطراف آن (محلی) متکی نیست، بلکه از آمار حضور همزمان کلمات در کنار هم در کل پیکره متنی (سراسری) استفاده میکند. علاوه بر این، روشهای قبلی تعبیه کلمات مانند word2vec میتوانستند روابط نحوی و معنایی بین کلمات را بیاموزند، اما نحوه یادگیری این روابط در مدلها مشخص نبود. هدف مدل GloVe این است که بتواند بردار تعبیه کلمات را با استفاده از قاعده و قانون یاد بگیرد و منشأ یادگیری روابط نحوی و معنایی کلمات را پیدا کند. در ادامه این مطلب، جزئیات مدل GloVe را شرح میدهیم.
GloVe چیست؟
قبل از معرفی مدل GloVe، پژوهشگران از دو روش متفاوت بهمنظور تولید تعبیه کلمات استفاده میکردند: «فاکتورگیری سراسری ماتریسی» و «پنجره متن محلی». بااینحال، هر دو روش مشکلات قابلتوجهی داشتند. بهعنوانمثال، مدل تحلیل معنایی نهفته (LSA) که به دستهٔ روشهای فاکتورگیری سراسری ماتریسی تعلق دارد، از اطلاعات آماری بهره میبرد. بااینوجود، مدل LSA هنگامی که باید کلمات با معانی مشابه را پیدا کند، عملکرد چندان قوی نداشت . برعکس، مدلهایی مثل Word2Vec که از رویکرد پنجره متن محلی استفاده میکنند، در انجام آنالوژی بهتر عمل میکنند، اما در تحلیل آمار کلمات ضعیف هستند.
برای حل این مشکلات، مدل GloVe معرفی شد که از ترکیبی از روشهای فاکتورگیری سراسری ماتریسی و پنجره متن محلی استفاده میکند. مدل GloVe بر اساس این ایده ساخته شد که میتوان با بررسی آمار همزمانی کلمات در کل پیکره متنی، روابط بین کلمات را تعیین کرد. در واقع، اصلیترین مفهوم در مدل GloVe این است که کلماتی با معانی مشابه تمایل دارند در متون مشابه هم ظاهر شوند؛ بنابراین، مدل GloVe تلاش میکند تا از طریق آمار حضور همزمان کلمات در یک پیکره متنی بزرگ، روابط معنایی و نحوی را به دست آورد.
برای روشنشدن ایده مدل GloVe، یک مثال را مطرح میکنیم. دو کلمه «یخ» و «بخار» را در نظر بگیرید. ما انتظار داریم که کلماتی مانند «جامد» یا «آب» با احتمال بیشتری در کنار کلمه «یخ» در یک متن حضور یابد و احتمال اینکه کلماتی مانند «گاز» یا «مُد» در کنار کلمه «یخ» قرار بگیرد کم است. همچنین به طور مشابه، انتظار ما این است که کلمات «گاز» و «آب» را با احتمال بیشتری در کنار کلمه «بخار» در یک متن مشاهده کنیم تا اینکه کلمهای مانند «جامد» یا «مُد». برای بررسی درستی این موضوع، احتمال این کلمات در یک پیکره متنی بزرگ بهدستآمده است:
جدول 1: احتمال قرار گرفتن همزمان کلمات یخ و بخار با کلمات انتخاب شده از یک پیکره با 6 میلیارد کلمه.
| k = fashion | k = water | k = gas | k = solid | Probability and Ratio |
| 1.7 × 10−5 | 3.0 × 10−3 | 6.6 × 10−5 | 1.9 × 10−4 | P(k|ice) |
| 1.8 × 10−5 | 2.2 × 10−3 | 7.8 × 10−4 | 2.2 × 10−5 | P(k|steam) |
| 0.96 | 1.36 | 8.5 × 10−2 | 8.9 | P(k|ice)/P(k|steam) |
در جدول 1 احتمال قرار گرفتن کلمه j در کنار کلمه i از رابطه زیر محاسبه شده است:
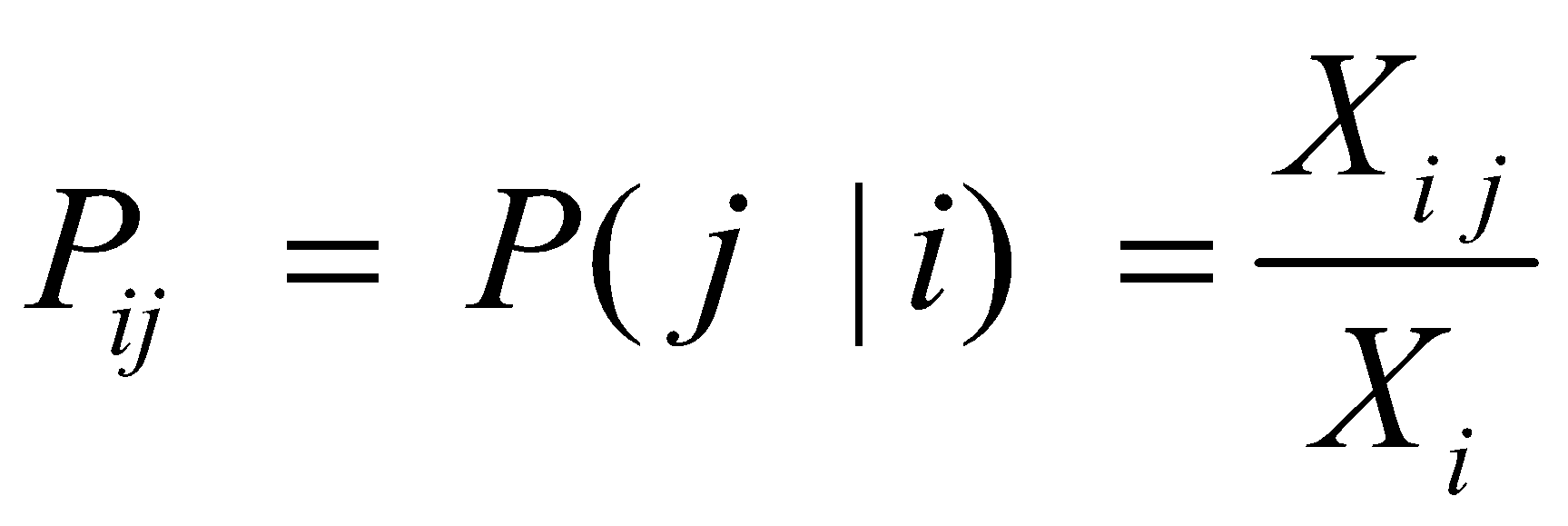
در عبارت (1)، X ماتریس همزمانی و Xij یک درایه از این ماتریس است که تعداد دفعات قرارگیری کلمه i با کلمه j در پنجره زمینه را نشان میدهد. Xi نیز برابر با تعداد دفعاتی است که کل کلمات در پنجره زمینه در کنار کلمه i قرار گرفتهاند. اعداد جدول 1 نشان میدهد که انتظاراتی که در مورد قرارگیری این کلمات در کنار هم وجود دارد، درست است. در جدول 1 علاوه بر احتمال همزمانی کلمات، نسبت احتمال برای کلمه «یخ» و «بخار» نیز محاسبه شده است. همانطور که در سطر آخر جدول 1 مشخص است، این نسبت برای کلمهای مانند «جامد» که به کلمه «یخ» مربوط است ولی ربطی به کلمه «بخار» ندارد، مقدار زیادی است. در مقابل این نسبت برای کلمه «گاز» که با کلمه «بخار» در ارتباط است ولی با کلمه «یخ» ارتباطی ندارد، مقدار کوچکی است. همچنین مقدار نسبت احتمالها برای کلمهای مانند «آب» که به هر دو کلمه «یخ» و «بخار» مربوط است و یا کلمه «مُد» که هیچ ارتباطی به کلمات «یخ» و «بخار» ندارد، نزدیک به عدد یک است. پس، از این مثال میتوانیم این نتیجه را بگیریم که نسبت احتمالات بهتر میتواند کلمات مرتبط را از کلمات نامربوط تشخیص دهد و همچنین بهتر میتواند بین دو کلمه مرتبط تمایز قائل شود.
در مثال فوق توانستیم نشان دهیم که با استفاده از اطلاعات آماری موجود در همزمانی کلمات، میتوانیم به برخی از روابط معنایی بین کلمات برسیم. ایده مدل GloVe دقیقاً همین است که از اطلاعات آماری همزمانی کلمات استفاده کند و بردارهایی عددی برای بازنمایی کلمات به دست آورد. اما یک مشکل اساسی برای انجام این محاسبات وجود دارد و آن هم محاسبه ماتریس همزمانی است. زیرا ماتریس همزمانی یک ماتریس مربعی است که اندازه آن برابر با تعداد کلمات در پیکره است. اندازه این ماتریس برای پیکرههای متنی حجیم بسیار بزرگ و نگهداری و محاسبه آن دشوار است؛ بنابراین مدل GloVe از روش فاکتورگیری ماتریس استفاده میکند و ماتریس همزمانی را بهصورت تقریبی به دست میآورد. این موضوع در شکل 1 نشان داده شده است.
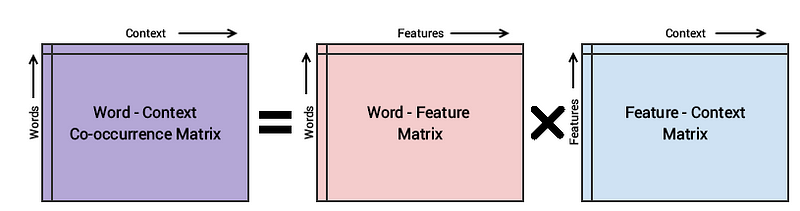
در این شکل، سه ماتریس Word-Context (WC )، Word-Feature (WF ) و Feature-Context (FC ) وجود دارد. با استفاده از روش فاکتورگیری ماتریسی، میتوان ماتریس WC را از ضرب دو ماتریس WF و FC بازسازی کرد. برای انجام این کار، ابتدا ماتریس WF و FC به صورت تصادفی وزندهی اولیه میشوند و از ضرب این دو ماتریس، ماتریس WC` (تقریب ماتریس WC ) به دست میآید و میزان نزدیک بودن آن به ماتریس WC اندازهگیری میشود. این فرایند چندین بار و با استفاده از کاهش گرادیان تصادفی انجام میشود تا خطا به حداقل برسد. در نهایت، ماتریس Word-Feature ( WF) ماتریس تعبیههای کلمات است. بنابراین مدلGlove تلاش میکند تابع خطا زیر را بهینه کند که به آن رگرسیون لگاریتمی-دوخطی سراسری میگویند:
تابع ضرر تعریف شده در عبارت (2) اندازه میگیرد که چقدر کلمه i به کلمه j با توجه به تعداد همزمانی این دو کلمه در یک متن مرتبط هستند ( ![]() ) و تلاش میکند که با بروزرسانی بردار تعبیه کلمات، فاصله ضرب بردارهای کلمه i و j را نسبت به لگاریتم Xij کمینه کند. علت استفاده از لگاریتم Xij این است که اعداد در ماتریس همزمانی در یک محدوده کوچک تر قرار بگیرند. زیرا برخی از کلماتی که به هم مرتبط نیستند مثل «مُد» و «یخ»، مقدار همزمانی برای آنها برابر صفر است و برای برخی دیگر از کلمات که تعداد دفعات زیادی در کنار هم قرار میگیرند، مقدار همزمانی زیاد است؛ بنابراین از لگاریتم استفاده میشود تا این محدوده را کوچک و نرمال کند. اما اشکال استفاده از لگاریتم این است که اگر مقدار برابر صفر باشد، لگاریتم آن تعریف نشده است. به همین علت از تابع وزن Xij استفاده میشود و به گونهای تعریف میگردد که اگر مقدار Xij برابر صفر شود، مقدار تابع وزن f(Xij) نیز صفر شود تا در نهایت در ضرب با Log Xij ، حاصل برابر صفر شود. علاوه بر این، کاربرد دیگر استفاده از تابع وزن f(Xij) این است که به کلماتی که تعداد دفعات زیادی در متن ها تکرار میشوند، وزن کمتری بدهد. زیرا کلماتی که در متن زیاد تکرار میشوند شامل ضمائر، حروف ربط و غیره است و اطلاعات زیادی در مورد روابط کلمات ارائه نمیدهند؛ بنابراین چون میخواهیم تأثیر این کلمات بر روی تابع ضرر زیاد نباشد، تابع وزن f(Xij) به گونهای طراحی میشود که وزن اختصاص داده شده به این کلمات کوچک باشد. از طرفی دیگر کلماتی که تعداد دفعات کمی در متن تکرار میشوند، اغلب دارای اطلاعات زیادی در مورد روابط کلمات هستند. بنابراین تابع وزن f(Xij) به گونهای طراحی میشود که با افزایش مقدار Xij ، مقدار کاهش نیابد. زیرا اگر مقدار با افزایش کاهش یابد، اهمیت کلمات کمیاب کم میشود. تابعهای زیادی هستند که ویژگیهای ذکر شده در بالا را برای تابع f(Xij) برآورده کنند اما تابع پیشنهاد شده در مدل GloVe به صورت زیر تعریف میشود:
) و تلاش میکند که با بروزرسانی بردار تعبیه کلمات، فاصله ضرب بردارهای کلمه i و j را نسبت به لگاریتم Xij کمینه کند. علت استفاده از لگاریتم Xij این است که اعداد در ماتریس همزمانی در یک محدوده کوچک تر قرار بگیرند. زیرا برخی از کلماتی که به هم مرتبط نیستند مثل «مُد» و «یخ»، مقدار همزمانی برای آنها برابر صفر است و برای برخی دیگر از کلمات که تعداد دفعات زیادی در کنار هم قرار میگیرند، مقدار همزمانی زیاد است؛ بنابراین از لگاریتم استفاده میشود تا این محدوده را کوچک و نرمال کند. اما اشکال استفاده از لگاریتم این است که اگر مقدار برابر صفر باشد، لگاریتم آن تعریف نشده است. به همین علت از تابع وزن Xij استفاده میشود و به گونهای تعریف میگردد که اگر مقدار Xij برابر صفر شود، مقدار تابع وزن f(Xij) نیز صفر شود تا در نهایت در ضرب با Log Xij ، حاصل برابر صفر شود. علاوه بر این، کاربرد دیگر استفاده از تابع وزن f(Xij) این است که به کلماتی که تعداد دفعات زیادی در متن ها تکرار میشوند، وزن کمتری بدهد. زیرا کلماتی که در متن زیاد تکرار میشوند شامل ضمائر، حروف ربط و غیره است و اطلاعات زیادی در مورد روابط کلمات ارائه نمیدهند؛ بنابراین چون میخواهیم تأثیر این کلمات بر روی تابع ضرر زیاد نباشد، تابع وزن f(Xij) به گونهای طراحی میشود که وزن اختصاص داده شده به این کلمات کوچک باشد. از طرفی دیگر کلماتی که تعداد دفعات کمی در متن تکرار میشوند، اغلب دارای اطلاعات زیادی در مورد روابط کلمات هستند. بنابراین تابع وزن f(Xij) به گونهای طراحی میشود که با افزایش مقدار Xij ، مقدار کاهش نیابد. زیرا اگر مقدار با افزایش کاهش یابد، اهمیت کلمات کمیاب کم میشود. تابعهای زیادی هستند که ویژگیهای ذکر شده در بالا را برای تابع f(Xij) برآورده کنند اما تابع پیشنهاد شده در مدل GloVe به صورت زیر تعریف میشود:
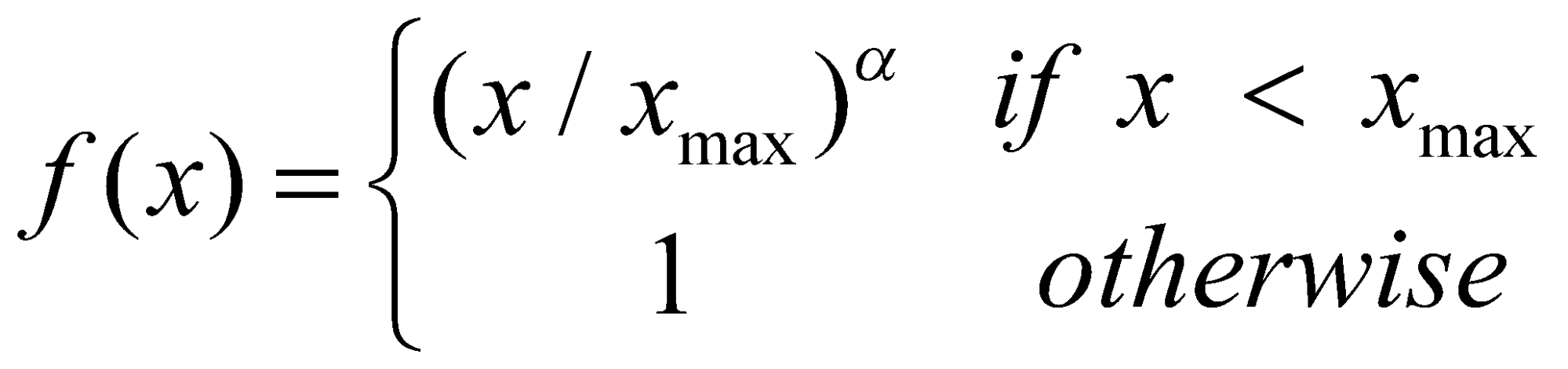
در عبارت ، Xmax و a پارامترهایی هستند که مقدار آن ها در مدل GloVe به ترتیب برابر با 100 و 3.4 تنظیم شده است.
پس از آموزش مدل GloVe، بردارهای تعبیهای به دست میآید که کلمات را بر اساس الگوهای همزمانی آنها نشان میدهد. اندازه یا ابعاد بردارهای تعبیه کلمات در GloVe میتواند بسته به تنظیمات آموزشی خاص و نیازهای یک پروژه متفاوت باشد. به طور معمول، اندازه بردارهای GloVe بهعنوان یک ابرپارامتر در طول آموزش مدل انتخاب میشود. انتخابهای رایج برای اندازه بردارهای تعبیه کلمات در GloVe عبارتاند از:
پس از آموزش مدل GloVe، بردارهای تعبیهای به دست میآید که کلمات را بر اساس الگوهای همزمانی آنها نشان میدهد. اندازه یا ابعاد بردارهای تعبیه کلمات در GloVe میتواند بسته به تنظیمات آموزشی خاص و نیازهای یک پروژه متفاوت باشد. به طور معمول، اندازه بردارهای GloVe بهعنوان یک ابرپارامتر در طول آموزش مدل انتخاب میشود. انتخابهای رایج برای اندازه بردارهای تعبیه کلمات در GloVe عبارتاند از:
- بردارهای 50 بعدی: بردارهای GloVe با ۵۰ بعد نسبت به سایر ابعاد نسبتاً کوچکتر هستند و ممکن است برای وظایف با منابع محاسباتی محدود مناسب باشند. این بردارها روابط پایه واژهها را نشان میدهند.
- بردارهای 100 بعدی: این یک انتخاب متداول است و تعادل خوبی بین عملکرد مدل و کارآیی محاسباتی ارائه میدهد. این بردارها میتوانند روابط معنایی بیشتری بین واژهها را نشان دهند.
- بردارهای 200 بعدی: بردارهای GloVe با 200 بعد، اطلاعات معنایی پیچیدهتری درباره روابط واژهها ثبت میکنند. این بردارها اغلب برای وظایفی استفاده میشوند که نیازمند دقت بالاتری هستند.
- بردارهای 300 بعدی: این بردارها ظرفیت بیشتری برای ضبط اطلاعات معنایی دقیقتر ارائه میدهند و معمولاً برای وظایف پیچیدهتر که نیاز به دقت بالا دارند انتخاب میشوند.
در عمل، انتخاب اندازه بردار GloVe به وظیفه و منابع محاسباتی موجود بستگی دارد. اندازههای برداری کوچکتر ممکن است برای کارهای ساده مناسب باشند، درحالیکه اندازههای برداری بزرگتر میتوانند عملکرد بهتری را در کارهای پیچیدهتر ارائه دهند. محققان اغلب با اندازههای برداری مختلف آزمایش میکنند تا بهترین مورد را برای نیازهایشان بیابند.
نتیجهگیری
در این پست مدل تعبیه کلمات GloVe را معرفی کردیم و نشان دادیم که مدل GloVe چگونه با بهحداقلرساندن یک تابع هدف که روابط بین کلمات را به تصویر میکشد، بردارهای تعبیه کلمات را تولید میکند که برای طیف گستردهای از وظایف پردازش زبان طبیعی مفید هستند. در پست آینده با مدل تعبیه کلمات دیگری به نام ELMO آشنا میشویم.
منابع
https://towardsdatascience.com/glove-research-paper-explained-4f5b78b68f89
https://sh-tsang.medium.com/review-glove-global-vectors-for-word-representation-8b237446a134

نظرات