"تاثیر معماری کدگزار بر عملکرد شبکه های عصبی در ترجمه ماشینی"
ترجمه خانم ساراناز عبداللهی از مقاله on the properties of neural machine translation: encoder–decoder approaches

چکیده
ترجمه ماشینی مبتنی بر شبکههای عصبی (NMT)، رویکردی نوآورانه نسبت به ترجمه ماشینی آماری (SMT) است که در آن برای بهبود دقت و روانی ترجمه از شبکههای عصبی استفاده میشود. هر مدل NMT معمولا از دو جزء کدگذار و کدگشا تشکیل شده است. کدگذار جملات ورودی با طولهای متغیر را به یک بازنمایی با طول ثابت تبدیل کرده، و پس از آن کدگشا از این بردار برای تولید ترجمه مناسب استفاده میکند. در این پست ویژگیهای NMT، مانند تاثیر طول جمله و تعداد کلمات ناشناخته بر عملکرد مدل را، براساس دو مدل شبکه عصبی بازگشتی کدگذار-کدگشا (RNNencdec) و شبکه عصبی پیچشی بازگشتی دروازهدار (grConv) توضیح میدهیم. همچنین، به بررسی این سوال میپردازیم که آیا شبکه عصبی با استفاده از رویکرد کدگذار-کدگشا میتواند بهطور خودکار ساختار دستوری یک جمله را یاد بگیرد یا خیر.
مقدمه
رویکرد ترجمه ماشینی مبتنی بر شبکههای عصبی (NMT) توسط جمعی از محققان در سال 2014 معرفی شد. این رویکرد، از روش یادگیری بازنمایی عمیق الهام گرفته شدهاست. یادگیری بازنمایی عمیق به روشی اطلاق میشود که با استفاده از شبکههای عصبی ژرف با تعداد لایههای بیشتر، به دنبال یادگیری بازنماییهای پیچیده و عمیقتر از دادهها است. بیشتر مدلهای NMT که در پژوهشهای پیشین معرفی شدهاند، از دو جزء کدگذار و کدگشا تشکیل شدهاند. کدگذار، جملات ورودی با طول متغیر را به شکل بردارهایی با طول ثابت بازنمایی کرده و کدگشا از این بازنمایی، ترجمهای صحیح با طول متغیر تولید میکند.
ظهور NMT بهصورت عملی و نظری اهمیت بالایی دارد. از لحاظ عملی، NMT نسبت به روشهای سنتی نظیر SMT به حافظهی کمتری نیاز دارد. در مقایسه با سیستمهای SMT که اغلب نیاز به دهها گیگابایت حافظه دارند، مدل NMT تنها به 500 مگابایت حافظه نیاز دارد. از لحاظ نظری، تمامی مؤلفههای مدل NMT بهطور همزمان و با همکاری یکدیگر آموزش داده میشوند که باعث بهبود کارایی ترجمه میشود.
به دلیل جدید بودن نسبی این رویکرد تا سال 2014، تحقیقات زیادی برای تجزیهوتحلیل ویژگیها و جنبههای مختلف این مدلها وجود نداشت. در نتیجه، پاسخ سوالاتی مانند موارد زیر در دست نبوده است:
- ویژگی جملاتی که روش NMT بر روی آنها عملکرد بهتری دارد، چیست؟
- انتخاب مجموعه واژگان مبدأ یا هدف چگونه بر عملکرد مدل تأثیر میگذارد؟
- NMT در چه مواردی شکست میخورد؟
درک رفتار و ویژگیهای مدل NMT، در جهتدهی تحقیقات آینده بسیار مهم خواهد بود. شناسایی نقاط ضعف و قوت مدلهای NMT، میتواند به یکپارچهسازی سامانههای SMT و NMT کمک کند. در این مقاله، دو مدل NMT، با نامهای RNNencdec و grConv مورد تحلیل و بررسی قرار میگیرند. این دو مدل در معماری کدگذار-کدگشا مشترک و در نوع شبکهی عصبی انتخابی در معماری کدگذار متفاوت هستند. این دو مدل در ترجمه فرانسوی به انگلیسی مورد ارزیابی قرار گرفتهاند.
پردازش دنبالههایی با طول متغیر
اولین مسئلهای که در ترجمهی ماشینی عصبی با آن مواجه هستیم، پردازش دنبالههای ورودی با طولهای متفاوت است. در این بخش، به معرفی دو نوع شبکه عصبی RNN و grConv میپردازیم که قادر به پردازش دنبالههایی با طول متغیر هستند.
شبکه عصبی بازگشتی (RNN) با نورونهای پنهان دروازهدار
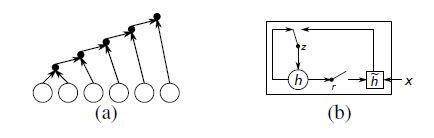
شکل 1 (a)، یک شبکهی RNN را نشان میدهد که دنباله ورودی ![]() با طول متغیر را، با حفظ یک وضعیت پنهان h در طول زمان پردازش میکند. فرمول زیر چگونگی بهروزرسانی وضعیت شبکه عصبی را در هر گام زمانی t نشان میدهد:
با طول متغیر را، با حفظ یک وضعیت پنهان h در طول زمان پردازش میکند. فرمول زیر چگونگی بهروزرسانی وضعیت شبکه عصبی را در هر گام زمانی t نشان میدهد:
براساس فرمول بالا در هر لحظه t، وضعیت پنهان فعلی شبکه عصبی ![]() با دریافت ورودی جدید
با دریافت ورودی جدید ![]() و استفاده از وضعیت قبلی خود
و استفاده از وضعیت قبلی خود ![]() ، بهروزرسانی میشود. در این فرمول، f یک تابع فعالسازی است که ابتدا یک تبدیل خطی بر روی بردارهای ورودی اعمال کرده، آنها را با هم جمع میکند، سپس تابع سیگموئید لجستیک مؤلفه به مؤلفه را بر روی نتیجه اجرا میکند.
، بهروزرسانی میشود. در این فرمول، f یک تابع فعالسازی است که ابتدا یک تبدیل خطی بر روی بردارهای ورودی اعمال کرده، آنها را با هم جمع میکند، سپس تابع سیگموئید لجستیک مؤلفه به مؤلفه را بر روی نتیجه اجرا میکند.
از RNN میتوان به شکل موثری در یادگیری توزیع دنبالههایی با طول متغیر استفاده کرد. این توزیع با یادگیری توزیع ورودی بعدی ![]() با توجه به ورودیهای فعلی به شکل
با توجه به ورودیهای فعلی به شکل ![]() ، قابل دستیابی است. RNN در دنبالهی
، قابل دستیابی است. RNN در دنبالهی ![]() ، با توجه به ورودی فعلی و تمام ورودیهای قبلی قادر است توزیعی دربارهی ورودی بعدی
، با توجه به ورودی فعلی و تمام ورودیهای قبلی قادر است توزیعی دربارهی ورودی بعدی ![]() یاد بگیرد. این قابلیت یادگیری توزیع، به دلیل وجود حافظهی بازگشتی در معماری RNN میباشد که اطلاعاتی از ورودیهای قبلی را در خود نگه میدارد.
یاد بگیرد. این قابلیت یادگیری توزیع، به دلیل وجود حافظهی بازگشتی در معماری RNN میباشد که اطلاعاتی از ورودیهای قبلی را در خود نگه میدارد.
بهعنوان مثال، اگر دنباله ورودی به شکل بردارهای ![]() (1 از K) باشد، یعنی هر بردار K مؤلفه دارد و تنها یکی از آنها مقدار 1 و بقیه مقدار صفر دارند. با استفاده از RNN، میتوان توزیع این دنباله را یاد گرفت. به این صورت که RNN، با دریافت هر بردار ورودی، پیشبینی میکند کدام یک از عناصر بعدی بردار باید مقدار 1 داشته باشد. در واقع توزیع ورودی بعدی را میتوان بهصورت زیر پیشبینی کرد:
(1 از K) باشد، یعنی هر بردار K مؤلفه دارد و تنها یکی از آنها مقدار 1 و بقیه مقدار صفر دارند. با استفاده از RNN، میتوان توزیع این دنباله را یاد گرفت. به این صورت که RNN، با دریافت هر بردار ورودی، پیشبینی میکند کدام یک از عناصر بعدی بردار باید مقدار 1 داشته باشد. در واقع توزیع ورودی بعدی را میتوان بهصورت زیر پیشبینی کرد:
j=1,..,K جایگاه عنصر را در بردار ورودی K بُعدی و wj عناصر هر سطر ماتریس وزن W را نشان میدهد. حاصل ضرب توزیع شرطی همهی عناصر بردار ورودی در یکدیگر، توزیع مشترک کل دنباله P(x) را میسازد:
در پژوهشی در سال 2014 یک تابع فعالسازی جدید برای RNN پیشنهاد شد. این تابع فعالسازی جدید، عملکرد تابع فعالسازی سیگموئید لجستیک را با استفاده از دو واحد دروازهدار به نام دروازه تنظیم r و دروازه بهروزرسانی z تغییر میدهد. براساس شکل 1 (b)، هر دروازه وابسته به حالت پنهان قبلی h(t-1) است و ورودی فعلی xt، جریان اطلاعات را کنترل میکند. بهتر است دقت داشته باشیم که در بقیه این مقاله، همواره از این تابع فعالسازی جدید استفاده شدهاست.
شبکه عصبی پیچشی بازگشتی دروازهدار (grConv)
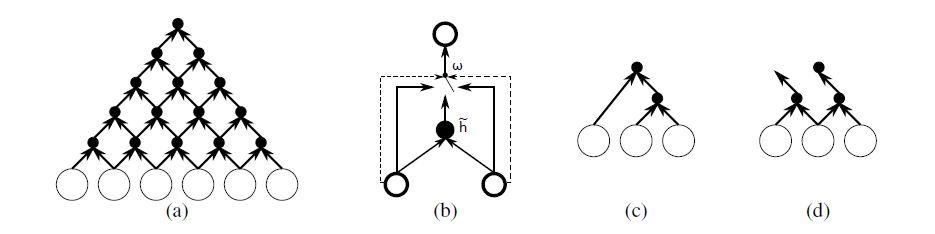
افزون بر RNNها، رویکرد دیگری برای کار با دنبالههایی با طول متغیر، استفاده از شبکههای عصبی پیچشی بازگشتی است که در آنها مطابق با شکل 2 (a)، پارامترهای شبکه در هر سطح، در کل شبکه به اشتراک گذاشته میشوند. در این بخش، به معرفی یک شبکه عصبی پیچشی دودویی میپردازیم. در این مدل وزنهای شبکه بهصورت بازگشتی بر روی دنباله ورودی اعمال میشوند تا زمانیکه خروجی آن به شکل یک بردار با طول ثابت در بیاید. علاوه بر ساختار پیچشی معمول، از مکانیزم دروازه اشاره شده نیز استفاده شده، تا به شبکه بازگشتی اجازه دهد ساختار جملات مبدأ را بهصورت پویا بیاموزد.
شبکهی عصبی پیچشی دودویی، نوعی شبکهی عصبی است که در آن توابع فعالسازی و وزنها در همهی لایههای پنهان (به جز لایههای ورودی و خروجی) دارای مقادیر تکبیتی هستند(یعنی تنها مقدار 0 یا 1 را میپذیرند).
فرض کنید ![]() یک دنباله ورودی با ابعاد
یک دنباله ورودی با ابعاد ![]() باشد. مدل grConv دارای چهار ماتریس وزن
باشد. مدل grConv دارای چهار ماتریس وزن ![]() ،
، ![]() است. در هر سطح بازگشت
است. در هر سطح بازگشت ![]() ، فعالسازی j -امین واحد پنهان یعنی
، فعالسازی j -امین واحد پنهان یعنی با استفاده از رابطه زیر محاسبه میشود:
در فرمول بالا Wc، Wl و Wr مقادیر مربوط به دروازه هستند که مجموع آنها برابر با یک است. از آنجایی که شبکه دودویی است، مجموع یک به این معنا است که تنها یکی از وزنهای Wc، Wl و Wr یک خواهد بود. در نتیجه، با توجه به فرمول فعالسازی و شکل2 بخش(b)، میتوان فعالسازی یک گره در سطح بازگشتی را، بهعنوان انتخابی بین فعالسازی جدید محاسبهشده از هر دو فرزند چپ و راست، فعالسازی از فرزند چپ، یا فعالسازی از فرزند راست در نظر گرفت. این انتخاب، ساختار کلی پیچش بازگشتی را بهصورت تطبیقی با نمونه ورودی تغییر میدهد.
واحد پنهان بهصورت زیر مقداردهی اولیه میشود:
ماتریس U، بردار ورودی را به فضای پنهان نگاشت میکند.
تابع فعالسازی جدید ![]() ، که اطلاعات حالت پنهان دو گره سمت راست و چپ را با یکدیگر ادغام میکند، طبق فرمول زیر محاسبه میشود:
، که اطلاعات حالت پنهان دو گره سمت راست و چپ را با یکدیگر ادغام میکند، طبق فرمول زیر محاسبه میشود:
![]() یک تابع غیرخطی مولفه به مولفه است.
ضرایب دروازه بهصورت زیر محاسبه میشوند:
یک تابع غیرخطی مولفه به مولفه است.
ضرایب دروازه بهصورت زیر محاسبه میشوند:
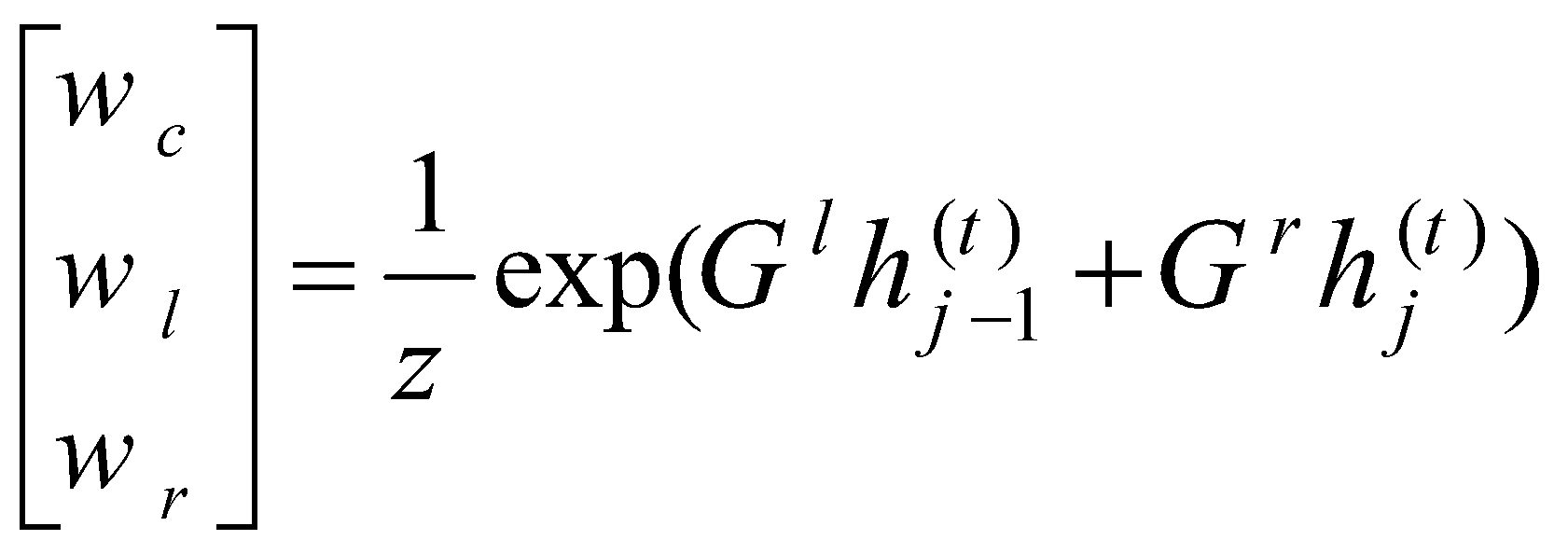
زمانیکه ابعاد دو ماتریس Gr و Gl بهصورت ![]() باشد، Z با فرمول زیر بهدست میآید:
باشد، Z با فرمول زیر بهدست میآید:
عملکرد مدل grConv را میتوان تجزیه کردن بدون نظارت دانست. اگر این حالت را در نظر بگیریم که دروازه برای تعیین مقادیر وزنهای w از کدگذاری 1-of-K پیروی کرده، و وزنهای اختصاص داده شده به قسمتهای مختلف شبکه را با مقدار دودویی تعیین کند، میتوان دید که شبکه با ورودی سازگار شده، و یک ساختار شبیه به درخت تشکیل میدهد (شکل 2 (c,d)). این ساختار درخت تجزیهوتحلیل (parse tree) است که توسط روشهای سنتی تجزیهوتحلیل متن برای پردازش زبان طبیعی استفاده میشود و وابستگیهای معنایی بین اجزای ورودی (مانند کلمات) را نشان میدهد.
ترجمه ماشینی مبتنی بر شبکههای عصبی (NMT)
رویکرد کدگذار-کدگشا
وظیفه ترجمه از منظر یادگیری ماشین میتواند بهعنوان یادگیری توزیع شرطی ![]() از جمله هدف (ترجمه) f با توجه به جمله مبدأ e در نظر گرفته شود. پس از یادگیری توزیع شرطی توسط مدل، با داشتن جملهی مبدأ و با استفاده از رویکرد نمونهبرداری واقعی یا استفاده از الگوریتم جستوجو، میتوان مستقیما جملهی هدف را نمونهبرداری کرد.
از جمله هدف (ترجمه) f با توجه به جمله مبدأ e در نظر گرفته شود. پس از یادگیری توزیع شرطی توسط مدل، با داشتن جملهی مبدأ و با استفاده از رویکرد نمونهبرداری واقعی یا استفاده از الگوریتم جستوجو، میتوان مستقیما جملهی هدف را نمونهبرداری کرد.
در روش نمونهبرداری واقعی، ابتدا مدل بهطور تصادفی کلمات را براساس احتمالات آنها در توزیع شرطی انتخاب میکند. سپس، با شروع از جمله مبدأ، هر کلمه از جمله هدف را با در نظر گرفتن متن و کلمات قبلی (تولیدشده) تولید میکند. در روش دیگر، الگوریتم جستوجو دنبالههای ممکن را براساس احتمالات آنها بررسی کرده و دنبالهای با بیشترین احتمال را بهعنوان جمله هدف انتخاب میکند.
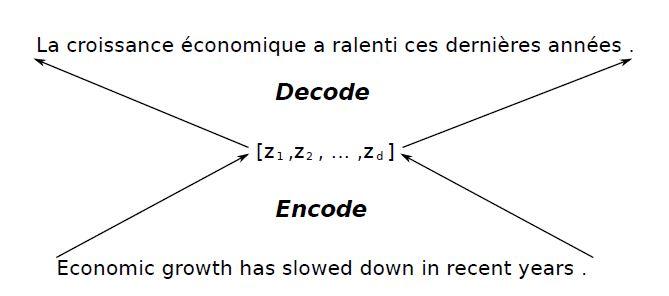
در هسته تمام مطالعات اخیر یک معماری کدگذار-کدگشا (شکل 3) نهفته است. بهطور کلی در یک سیستم ترجمه ماشینی با استفاده از شبکههای عصبی، ورودی بهشکل دنبالهای از کلمات(با طول متغیر) به شبکه داده میشود، سپس کدگذار این دنباله را به یک بردار بازنمایی (z در شکل3) نگاشت میکند. با توجه به بردار بازنمایی، کدگشا دنباله هدف(با طول متغیر) را تولید میکند.
پژوهشگران این مقاله عملکرد ترجمه مستقیم را با دو پیکربندی متفاوت برای مدل آزمایش کردهاند. آنها در این دو مدل، از یک RNN با واحد پنهان دروازهدار برای کدگشا استفاده میکنند، زیرا این رویکرد به تعیین طول هدف نیاز ندارد. مدل اول این مقاله از RNN با واحد پنهان دروازهدار برای کدگذار و مدل دوم از شبکهی عصبی پیچشی دروازهدار( grConv) بهعنوان یک کدگذار استفاده میکند. هدف کلی این مقاله درک سوگیری استنتاجی روش کدگذار-کدگشا به وسیله اندازهگیری عملکرد ترجمه با استفاده از معیار BLEU است.
تنظیمات آزمایشی
مجموعه داده
در این مقاله مدلهای کدگذار-کدگشا در وظیفه ترجمه انگلیسی به فرانسوی ارزیابی میشوند. به این منظور پژوهشگران از پیکره موازی دوزبانه شامل مجموعهای از 348 میلیون کلمه استفاده کردند، که ترکیبی از یوروپال (61 میلیون کلمه)، تفسیر خبری (5.5 میلیون کلمه)، دادههای مربوط به سازمان ملل (421 میلیون کلمه) و دو مجموعه واکشیشده به ترتیب با 90 و 780 میلیون کلمه است. علاوه بر این، در این مقاله عملکرد مدلهای NMT در مجموعههای news-test2012، news-test2013 و news-test2014 (هر کدام 3000 خط) اندازهگیری شدهاست. در هنگام مقایسه با سیستم SMT، پژوهشگران از news-test2012 و news-test2013 بهعنوان مجموعه توسعه خود برای تنظیم کردن سیستم SMT و از news-test2014 بهعنوان مجموعه آزمایشی خود استفاده کردهاند.
با افزایش طول جملات، پیچیدگی مدلهای زبانی افزایش مییابد. در نتیجه به زمان و منابع بیشتری برای آموزش مدل نیاز است. به همین دلیل، عموما در مراحل اولیه آموزش از جملات کوتاهتری استفاده میشود. در این مقاله نیز به دلایل کارایی محاسباتی، پژوهشگران از میان تمام جفتهای جمله در پیکره موازی، تنها از جفتهایی از جملات انگلیسی و فرانسوی که حداکثر دارای 30 کلمه هستند، برای آموزش شبکههای عصبی استفاده کردند. علاوه بر این، در این مقاله فقط 30هزار کلمه پرتکرار برای هر دو زبان انگلیسی و فرانسوی به کار گرفته شده، و همه کلمات دیگر ناشناخته در نظر گرفته شده و به یک توکن خاص ([UNK]) نگاشت شده اند.
تنظیمات مدل
در این مقاله دو مدل RNNencdec و grConv آموزش داده میشوند. هر دو مدل از RNN با واحدهای پنهان دروازهدار بهعنوان کدگشا استفاده کردهاند(برای اطلاعات بیشتر به بخش 1. 2 مراجعه کنید). این مقاله از روش گرادیان کاهشی با استفاده از زیردسته و نمونهبرداری تصادفی از دادهها با آدادلتا، برای آموزش دو مدل خود استفاده کردهاست. برای آموزش مدلها در آدادلتا، دادهها به گروههای کوچکتری تقسیم شده و براساس گرادیان فعلی، تغییرات وزنها بهصورت گامبهگام اعمال میشوند.
علاوه بر این، پژوهشگران در دو مدل RNNencdec و grConv، ماتریس وزن را بهعنوان یک ماتریس متعامد مقداردهی اولیه کردهاند. به این منظور، مقدار شعاع طیفی در مدلRNNencdec برابر با 1 و در مدلgrConv برابر با 0.4 تنظیم شدهاست. با مقداردهی اولیه ماتریس وزن بهشکل یک ماتریس متعامد، به یادگیری کارآمد مدل کمک کرده و از مشکل ناپدید شدن یا انفجار گرادیان در مدلهای یادگیری عمیق جلوگیری میکنند. همچنین از دو تابع tanh و (max(0; x)) rectifier بهعنوان توابع غیرخطی بهصورت عنصر به عنصر برای RNNencdec و grConv استفاده شدهاند.
مدلgrConv دارای 2000 نورون پنهان و مدل RNNencdec دارای 1000 نورون پنهان است. تعبیه کلمات (تبدیل کلمات به بردارهای عددی)، در هر دو مورد در فضای 620 بُعدی صورت میگیرد. هر دو مدل تقریباً برای 110 ساعت آموزش داده شده اند که بهترتیب معادل 296144 بهروزرسانی برای grConv و 846322 بهروزرسانی برای RNNencdec بودهاست.
ترجمه با استفاده از جستوجو بیم
در این مقاله از فرم اولیه جستوجوی بیم برای یافتن ترجمهای که احتمال شرطی مدل (در این حالت، RNNencdec و یا grConv) را بیشینه میکند، استفاده شدهاست. پژوهشگران در هر گام زمانیِ کدگشا، جاییکه عرض بیم برابر S = 10 است، کاندیدهای ترجمه S با بالاترین احتمال لگاریتمی را برای ترجمه بعدی نگه میدارند. منظور از عرض بیم، تعداد کاندیدهایی است که در هر گام زمانی برای ترجمه نگه داشته میشوند. در گامهای بعدی عرض بیم کاهش مییابد، تا زمانیکه به صفر برسد و ترجمه نهایی بهدست آید. در طول جستوجوی بیم (اگر نحوه عملکرد این الگوریتم را فراموش کردید یا از آن اطلاعی ندارید به انتهای پست مراجعه کنید)، هر فرضی که شامل کلمه ناشناخته باشد حذف میشود.
بهتر است بدانیم که با افزایش طول جمله یا تعداد کلمات ممکن برای ترجمه، تعداد حالتها و فضای جستوجو نیز بهطور نمایی افزایش مییابد. بهعنوان مثال در ترجمه ماشینی، تعداد ترجمههای ممکن برای یک جمله با طول مشخص، بسیار زیاد است و در نتیجه جستوجوی عمیق هزینه زمانی و محاسباتی بالایی را ایجاد میکند. با استفاده از الگوریتم جستوجوی بیم و تعریف عرض بیم، تعداد کاندیدهای کمتری در فضای جستوجو باقی میماند که این باعث کاهش هزینه محاسباتی و دستیابی سریعتر به ترجمه نهایی میشود.
در این مقاله، در الگوریتم جستوجوی بیم برای یافتن k بهترین ترجمه، از احتمال لگاریتمی معمول استفاده نشده است. بلکه پژوهشگران از یک احتمال لگاریتمی نرمالشده با توجه به طول ترجمه استفاده کردهاند تا با این روش از رفتار معمولی مدل RNN در ترجیح دادن ترجمههای کوتاهتر جلوگیری کنند.
نتایج و تجزیه و تحلیل
تحلیل کمی
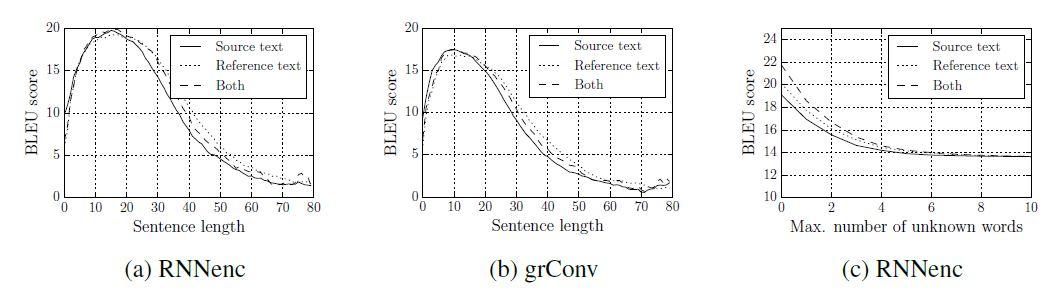
در این مقاله، پژوهشگران ویژگیهای مدلهای NMT شامل؛ کیفیت ترجمه را با توجه به طول و تعداد کلمات ناشناختهی جملات مبدأ/هدف بررسی کردهاند. براساس شکل ۴ (a) و (b)، پژوهشگران ابتدا امتیاز BLEU که نشاندهنده عملکرد ترجمه است، با توجه به طول جملات بررسی میکنند. به وضوح، هر دو مدل در جملات کوتاه عملکرد قابل قبولی دارند، اما با افزایش طول جملات به شدت دچار مشکل میشوند.
شکل 4 (c)، روند مشابهی با تعداد کلمات ناشناخته را نشان میدهد، با افزایش تعداد کلمات ناشناخته، عملکرد مدل بهسرعت کاهش مییابد. در نتیجه، در مطالعات آینده، افزایش اندازه مجموعه واژگان مورد استفاده در سیستم NMT یک چالش مهم خواهد بود. اگر چه در این مقاله نتیجه فقط با RNNencdec ارائه میشود، اما پژوهشگران رفتار مشابهی برای grConv نیز مشاهده کردهاند.
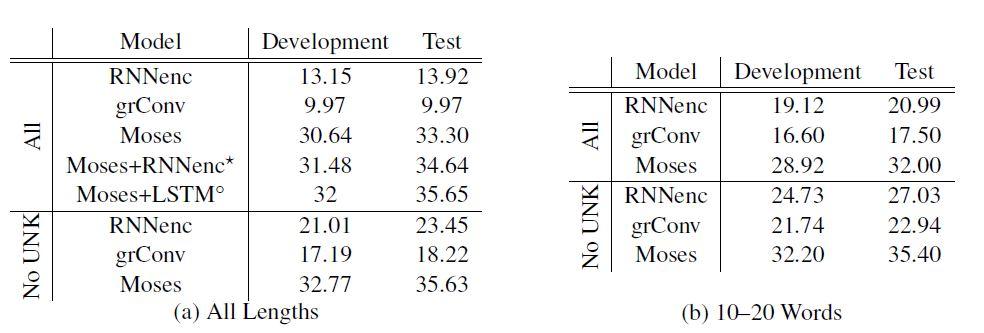
شکل5 به وضوح برتری عملکرد سیستم SMT بر پایه عبارات را نسبت به سیستم NMT خالص پیشنهادی نشان میدهد، اما میتوانیم ببینیم که در شرایط خاص(عدم وجود کلمات ناشناخته در جملات مبدأ و هدف)، تفاوت بهمیزان قابل توجهی کاهش مییابد. علاوه بر این براساس شکل 5 (b)، اگر فقط جملات کوتاه (با ۱۰-۲۰ کلمه در هر جمله) را در نظر بگیریم، تفاوت به شکل چشمگیری کاهش مییابد. علاوه بر این، همانطور که در شکل 5 (a) آمده، امکان استفاده از مدلهای NMT به همراه سیستم بر پایه عبارات نیز وجود دارد که در مطالعات سال 2014 برای بهبود عملکرد کلی ترجمه استفاده شدهاست.
تجزیهوتحلیل مطالعات گذشته نشان میدهد که رویکرد فعلی ترجمه عصبی در مدیریت جملات بلند ضعف دارد. محتملترین دلیل برای این موضوع این است که بازنمایی برداری با طول ثابت قدرت کافی برای کدگذاری یک جمله بلند با ساختار و معنای پیچیده را ندارد. بهمنظور کدگذاری یک دنباله با طول متغیر، شبکه عصبی ممکن است برخی از موضوعات مهم در جمله ورودی را قربانی کند تا بتواند سایر موضوعات را بهخاطر بسپارد.
در واقع، زمانیکه پژوهشگران برای طول جمله مبدأ و ترجمه هدف در بازه ۱۰ تا ۲۰ کلمه محدودیت قرار دهند و فقط از جملاتی بدون کلمات ناشناخته استفاده کنند، امتیاز BLEU در مجموعه تست برای RNNencdec برابر با ۲۷.۸۱ و برای Moses برابر با ۳۳.۰۸ میشود. در این مقاله حتی زمانیکه از جملاتی با حداکثر ۵۰ کلمه برای آموزش مدلها استفاده شده، روند مشابهی مشاهده شدهاست.
تحلیل کیفی
اگرچه امتیاز BLEU بهعنوان یک معیار استاندارد برای ارزیابی عملکرد ترجمه ماشینی استفاده میشود، اما براساس پژوهشهای سونگ، لیو و همکاران، این معیار کامل نیست. بنابراین، در این مقاله ترجمههای واقعی حاصل از دو مدل RNNencdec و grConv بهعنوان معیار ارزیابی در نظر گرفته شدهاست.
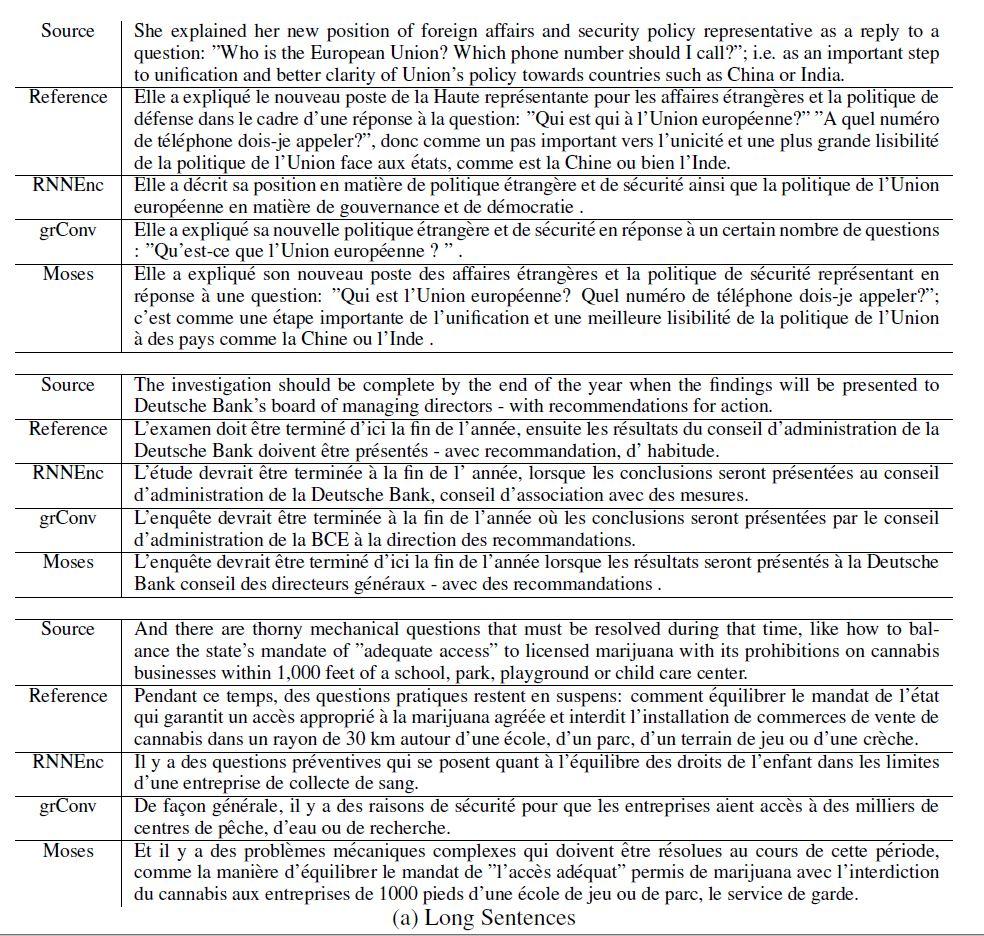
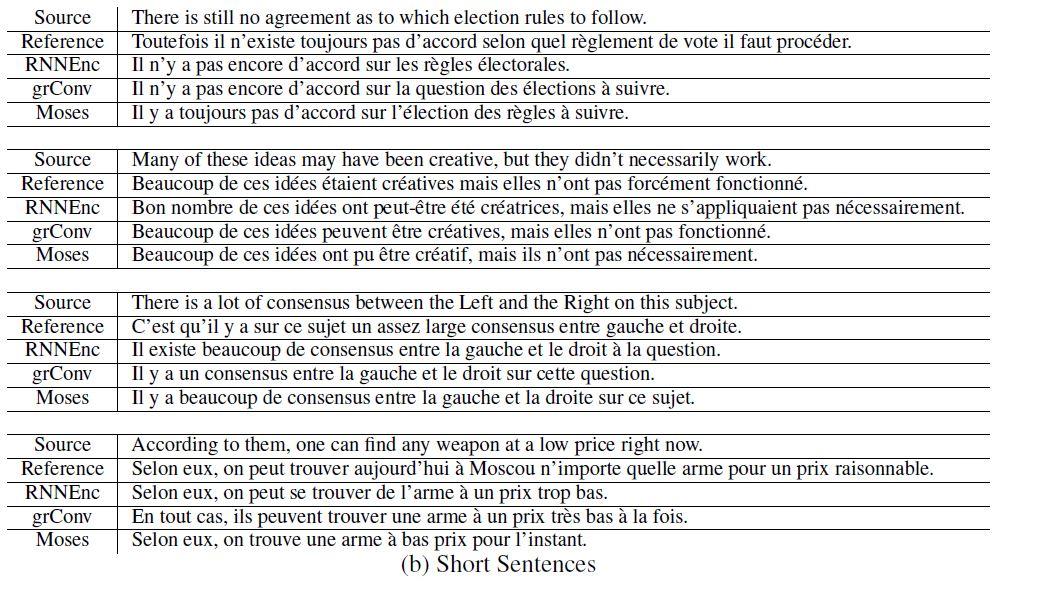
شکل6 ترجمهی برخی از جملات تصادفی از مجموعه توسعه و تست را نشان میدهد. در این مقاله جملاتی انتخاب شدهاند که هیچ کلمه ناشناختهای ندارند. شکل 6 (a) لیستی از جملات بلند (بیش از 30 کلمه) و شکل 6 (b) جملات کوتاه (کمتر از 10 کلمه) را نشان میدهد. همانطور که مشاهده میکنیم، با وجود تفاوت در امتیاز BLEU، هر سه مدل (RNNencdec، grConv و Moses) در ترجمه، به ویژه در جملات کوتاه عملکرد خوبی دارند. با این حال، زمانیکه جملات مبدأ بلند هستند، عملکرد مدلهای NMT کاهش مییابند.
از طرف دیگر، این مقاله مشخص میکند که grConv با یادگیری چه نوع ساختاری توانسته اطلاعات موجود در جملات را به بهترین شکل بازنمایی کند. در شکل 7، ساختارتجزیه یاد گرفته شده توسط کدگذار grConv و ترجمههای تولیدشده برای جمله نمونه “Obama is the President of the United States” نشان داده شدهاست. تجزیه فرایندی است که در آن، رشته ورودی بهصورت گرامری تجزیهوتحلیل شده و ساختار آن استخراج میشود. در واقع شکل 7 نشان میدهد که شبکه grConv چگونه توانسته ساختار تجزیه جمله را یاد بگیرد و ترجمههای تولیدشده را بهصورت گرافیکی نمایش دهد.
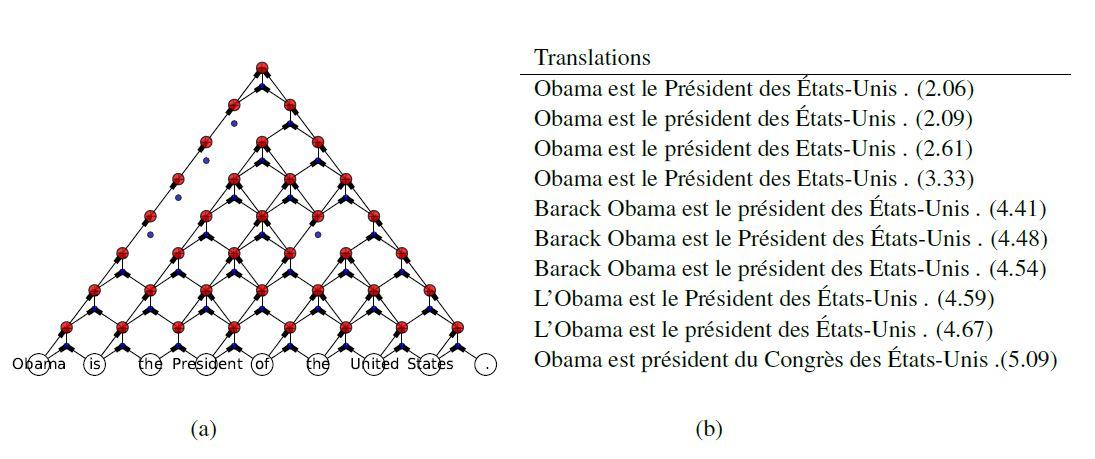
تصویر بالا نشان میدهد که grConv از بازنمایی برداری جمله با اولین ترکیب "of the United States" و "is the President of" شکل میگیرد و در نهایت این دو را با "Obama is" و "." ترکیب میکند. با وجود عملکرد پایینتر grConv در مقایسه با RNNencdec، پژوهشگران معتقدند که نحوه یادگیری ساختار دستور زبان در grConv به تحقیقات بیشتر نیاز خواهدداشت.
نتیجهگیری و بحث و تبادلنظر
در این مقاله پژوهشگران عملکرد دو مدل (1) RNN با واحدهای پنهان دروازهدار (RNNencdec) و (2) grConv را آزمودند. پس از آموزش این دو مدل بر روی جفتهایی از جملات انگلیسی و فرانسوی، ترجمههای خروجی این مدلها با توجه به طول جملات و وجود کلمات ناشناخته/نادر در جملات با استفاده از امتیازهای BLEU بررسی شد. براساس این پژوهش، عملکرد مدلهای NMT بهشدت به طول جملات وابسته است. با این حال، از نظر کیفی، هر دو مدل ترجمههای صحیح را بهخوبی تولید میکنند.
مطابق با نظر پژوهشگران، پیش از هر چیز باید راهی برای افزایش مقیاس آموزش شبکه عصبی هم در محاسبات و هم در حافظه یافت، تا بتوان از مجموعه واژگان بسیار بزرگتر برای زبان مبدأ و هدف استفاده کرد. بهویژه در زبانهایی با ریشهشناسی غنی، ممکن است به یک رویکرد کاملاً جدید در جواب دادن به واژهها نیاز باشد. این رویکرد میتواند شامل روشهای خاصی مانند تقسیم واژهها به بخشهای مختلف، استفاده از دیکشنریهای خاص برای ریشهیابی و ساخت واژههای جدید و یا استفاده از استراتژیهای دیگر در هنگام پردازش واژهها باشد. همچنین، این مقاله در زمینه جلوگیری از کاهش کارایی NMT با جملات طولانی، نیازمند تحقیقات بیشتری است. در نهایت، محققان باید در جهت یافتن معماریهای مختلف عصبی بهخصوص برای کدگشا تلاشهای بیشتری داشته باشند. زیرا با وجود تفاوت چشمگیر در معماری بین RNN و grConv که بهعنوان کدگذار استفاده شدهاند، هر دو مدل با مشکل طول جمله مواجه هستند.
پژوهشگران در مورد مدل پیشنهادی grConv، علاوه بر خصوصیت سیستم ترجمه ماشینی، یک ویژگی دیگر هم مشاهده کردهاند. مدل grConv بدون هیچ گونه نظارتی بر روی ساختار نحوی زبان، میتواند ساختار گرامری جمله ورودی را شبیهسازی کند. این خاصیت میتواند برای برنامههای پردازش زبان طبیعی به جز ترجمه ماشینی نیز مناسب باشد.
منابع
https://www.ms.uky.edu/~qye/MA721/presentations/Neural_Machine_Translation_Armin_Hadzic.pdf

نظرات