از کلمات تا بردارها (1): قدرت و پتانسیل word2vec
word2vec

مقدمه
در پردازش زبان طبیعی، بازنمایی کلمات به روشی معنادار همیشه یک چالش بوده است. روشهای اولیه برای بازنمایی کلمات، مانند کدگذاری وان هات، کلمات را بهعنوان بردارهای پراکنده نشان میدادند که قادر به درک تفاوتهای ظریف معنایی و روابط کلمات نبودند. در سال 2013، مقاله مهمی با عنوان «برآورد کارآمد بازنمایی کلمات در فضای برداری» توسط توماس میکولوف و همکاران منتشر شد و روشی به نام Word2Vec را معرفی کردند که جهشی قابلتوجهی در نحوه درک و کار با کلمات در پردازش زبان طبیعی ایجاد کرد. Word2Vec یک مدل مبتنی بر شبکه عصبی است که نمایشهای توزیع شده کلمات (جانمایی کلمات) را در یک فضای برداری پیوسته میآموزد. ایده اصلی Word2Vec این است که کلمات با معانی مشابه تمایل دارند در متنهای مشابه ظاهر شوند. با استفاده از این بینش، مدل یاد میگیرد که کلمات با معانی مشابه را در فضای برداری نزدیک به هم قرار دهد. در ادامه این مقاله جزئیات و معماری استفاده شده در Word2Vec را توضیح میدهیم.
Word2Vec چیست؟
فرایند آموزش Word2Vec توسط دو معماری اصلی هدایت میشود: Continuous Bag of Words (CBOW) و Skip-gram. مدل CBOW یاد میگیرد که یک کلمه هدف را با استفاده از تمام کلمات موجود در همسایگی آن پیشبینی کند. کلمات همسایهای که در نظر گرفته میشوند با اندازه پنجره از پیش تعریف شده اطراف کلمه هدف تعیین میشوند. در مقابل، مدل SkipGram یاد میگیرد که کلمات متنی را بر اساس یک کلمه هدف پیشبینی کند. به بیان ساده، با توجه به یک کلمه، میآموزد که کلمه دیگری را در زمینه آن پیشبینی کند. این یادگیری دوطرفه تضمین میکند که Word2Vec هم روابط نحوی و هم روابط معنایی بین کلمات را درک کند. با توجه به توضیحات بالا، در این روش نمونههای آموزشی از حذف کلمات در یک جمله کامل و پیشبینی آنها در خروجی ساخته میشود؛ بنابراین میتوانیم بگوییم که روش Word2Vec برای آموزش از یادگیری غیر نظارتی استفاده میکند. در ادامه این بخش جزئیات معماری CBOW و Skip-gram را بیان میکنیم.
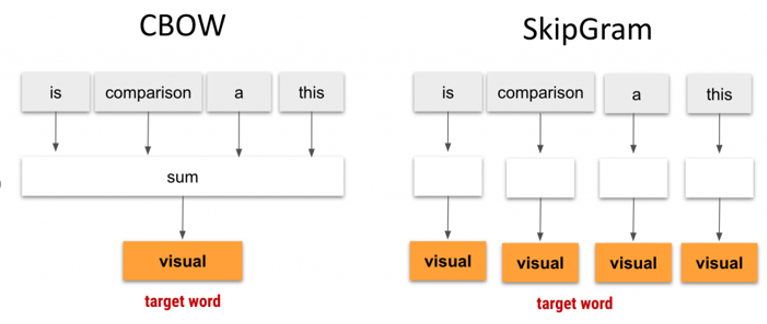
شکل 1: مقایسه مدل CBOW و SkipGram.
معماری CBOW
Continuous Bag of Words (CBOW) یک روش پردازش زبان طبیعی محبوب است که برای ایجاد جانمایی کلمات استفاده میشود. جانمایی کلمات برای بسیاری از وظایف پردازش زبان طبیعی مهم است؛ زیرا روابط معنایی و نحوی بین کلمات در یک زبان را نشان میدهد. روش CBOW، یک کلمه هدف را با توجه به کلمات اطراف آن در متن پیشبینی میکند (شکل 1).
در اینجا شاید این سؤال برای شما ایجاد شود که چه تفاوتی بین مدل کیسه کلمات (BOW) که در پستهای قبلی بررسی کردیم با مدل CBOW وجود دارد. مدل BOW متن ورودی را بهعنوان مجموعهای از کلمات و فراوانی آنها در یک پیکره معین نشان میدهد و ترتیب یا متنی که کلمات در آن ظاهر میشوند را در نظر نمیگیرد؛ بنابراین، ممکن است معنای کامل متن را دریافت نکند. پیادهسازی مدل BOW ساده و آسان است، اما این مدل محدودیتهایی در درک معنای زبان دارد. در مقابل، مدل CBOW یک رویکرد مبتنی بر شبکه عصبی است که متنی که کلمه در آن ظاهر شده است را در نظر میگیرد. CBOW یاد میگیرد که کلمه موردنظر را بر اساس کلماتی که قبل و بعد از آن در یک پنجره مشخص ظاهر میشوند، پیشبینی کند. با درنظرگرفتن کلمات اطراف، مدل CBOW میتواند معنای یک کلمه را در یک متن مشخص، بهتر دریافت کند.
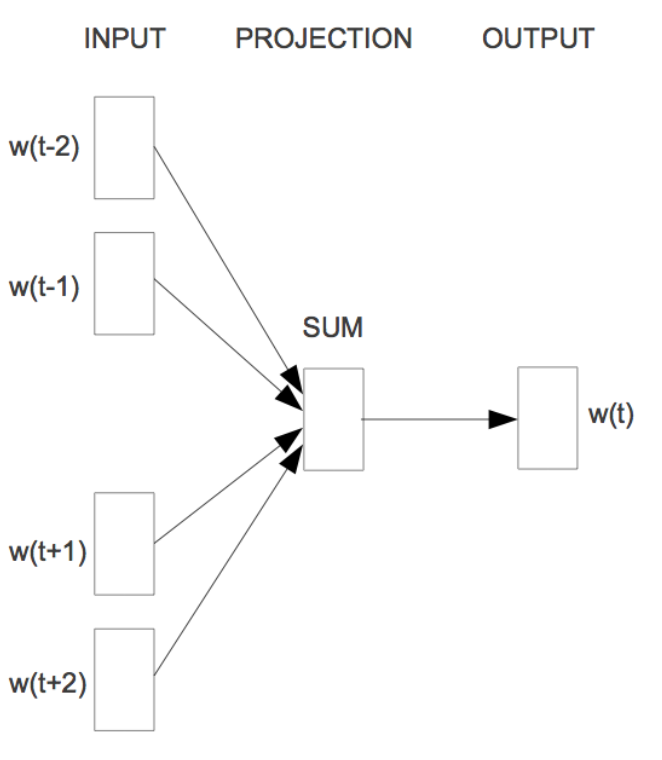
شکل 2: معماری CBOW.
شکل 2 معماری مدل پیادهسازی شده CBOW را نشان میدهد. همانطور که در این شکل مشخص است، ابتدا کلمات اطراف ![]() کلمه هدف
کلمه هدف ![]() به عنوان ورودی به یک لایه جانمایی (با وزنهای اولیه تصادفی) ارسال و یک بردار جانمایی برای هر کلمه محاسبه میشود. سپس این بردارها به لایه بعدی (Lambda Layer) منتقل میگردند و میانگین این بردارهای جانمایی محاسبه میشود. پس از آن، بردار جانمایی بهدستآمده از یک لایه Softmax عبور میکند تا کلمه هدف
به عنوان ورودی به یک لایه جانمایی (با وزنهای اولیه تصادفی) ارسال و یک بردار جانمایی برای هر کلمه محاسبه میشود. سپس این بردارها به لایه بعدی (Lambda Layer) منتقل میگردند و میانگین این بردارهای جانمایی محاسبه میشود. پس از آن، بردار جانمایی بهدستآمده از یک لایه Softmax عبور میکند تا کلمه هدف ![]() در خروجی پیشبینی شود. سپس کلمه پیشبینی شده
در خروجی پیشبینی شود. سپس کلمه پیشبینی شده ![]() توسط مدل با کلمه هدف تطبیق داده میشود و ضرر محاسبه میگردد. در نهایت، با انجام عملیات پسانتشار جانماییها بهروزرسانی میشوند. پس از تکمیل آموزش این مدل، میتوان جانمایی کلمات موردنیاز را از لایه جانمایی استخراج کرد.
توسط مدل با کلمه هدف تطبیق داده میشود و ضرر محاسبه میگردد. در نهایت، با انجام عملیات پسانتشار جانماییها بهروزرسانی میشوند. پس از تکمیل آموزش این مدل، میتوان جانمایی کلمات موردنیاز را از لایه جانمایی استخراج کرد.
شکل 3: شماتیک مدل پیادهسازی شده CBOW.
کد معماری مدل CBOW در TensorFlow بهصورت زیر است:

شکل 4: کد پیادهسازی شده مدل CBOW در TensorFlow.
که پس از آموزش این مدل بر روی مجموعهداده موردنظر، جانمایی کلمات را میتوان از لایه Embedding در مدل به دست آورد:

شکل 5: نحوه استفاده از جانماییهای بدست آمده از مدل CBOW پس از آموزش.
مدل Skip-gram
در مدل Skip-gram، با توجه به یک کلمه هدف، کلمات اطراف متن پیشبینی میشوند (شکل 5). از آنجایی که مدل skip-gram باید چندین کلمه را از یک کلمه داده شده پیشبینی کند، دادههای جفتی (X, Y) به مدل داده میشود که X ورودی و Y برچسب است. این کار با ایجاد نمونههای ورودی مثبت و نمونههای ورودی منفی انجام میشود. نمونههای ورودی مثبت به صورت [(Target، Context)، 1] است که در آن Target، کلمه هدف و Context کلمات اطراف کلمه هدف است و برچسب یک نشان میدهد کلمه هدف و کلمات اطراف آن با هم مرتبط هستند. به طور مشابه نمونههای ورودی منفی به شکل [(Target، Random)، 0] هستند. در این حالت، بهجای کلمات اطراف واقعی، کلماتی که به طور تصادفی انتخاب شدهاند به همراه کلمه هدف با برچسب صفر وارد میشوند که نشان میدهد کلمه هدف و کلمات اطراف آن به هم مرتبط نیستند. نمونههای منفی، مدل را از کلمات مرتبط با هم در یک متن آگاه میکنند و در نتیجه جانماییهای مشابهی را برای کلمات با معانی مشابه ایجاد میکنند. به این روش نمونهبرداری منفی میگویند.
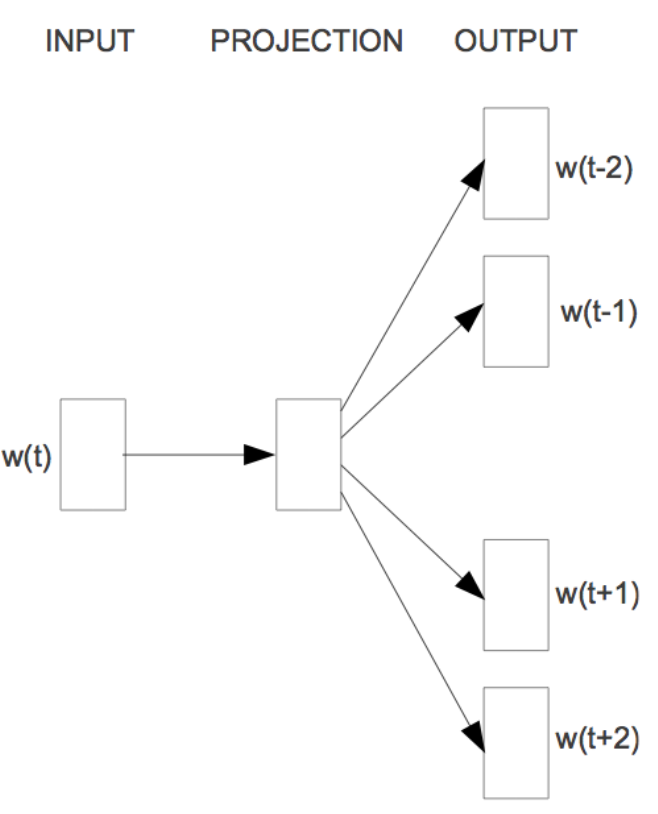
شکل 6: معماری Skip-gram.
معماری مدل پیادهسازی شده Skip-gram در شکل 6 نشاندادهشده است. کلمه هدف ![]() و کلمات اطراف آن
و کلمات اطراف آن ![]() به لایههای جانمایی جداگانه ارسال و جانمایی هر دو محاسبه میشود. سپس در لایه ادغام (Merge Layer) حاصلضرب نقطهای این دو بردار جانمایی به دست میآید. در مرحله بعد، مقدار حاصلضرب نقطهای این دو بردار به یک لایه سیگموئید ارسال میشود که مقدار صفر یا یک را در خروجی برمیگرداند. خروجی
به لایههای جانمایی جداگانه ارسال و جانمایی هر دو محاسبه میشود. سپس در لایه ادغام (Merge Layer) حاصلضرب نقطهای این دو بردار جانمایی به دست میآید. در مرحله بعد، مقدار حاصلضرب نقطهای این دو بردار به یک لایه سیگموئید ارسال میشود که مقدار صفر یا یک را در خروجی برمیگرداند. خروجی ![]() با برچسب واقعی Y مقایسه و مقدار ضرر محاسبه میشود. در نهایت وزنهای مدل با انجام عملیات پسانتشار بهروزرسانی میگردد.
با برچسب واقعی Y مقایسه و مقدار ضرر محاسبه میشود. در نهایت وزنهای مدل با انجام عملیات پسانتشار بهروزرسانی میگردد.
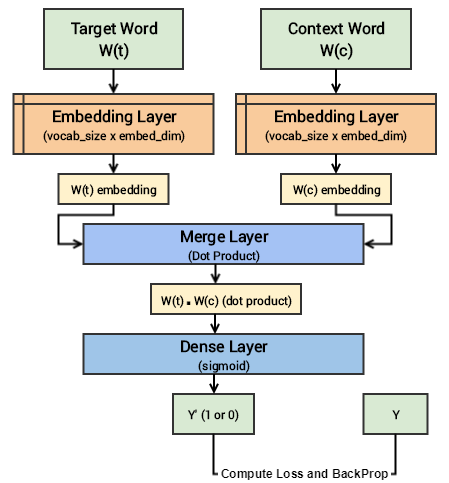
شکل 7: شماتیک مدل پیادهسازی شده Skip-gram در TensorFlow
کد پیادهسازی شده مدل Skip-gram در TensorFlow به شکل زیر است:

شکل 8: کد پیادهسازی شده مدل Skip-gram در TensorFlow.
برای بهدستآوردن جانمایی کلمات پس از آموزش مدل Skip-gram میتوان از قطعه کد زیر استفاده نمود:

شکل 9: نحوه استفاده از جانماییهای بدست آمده از مدل Skip-gram پس از آموزش.
آموزش مدل Word2Vec بر روی مجموعه اشعار فارسی
در این بخش میخواهیم یک مدل Word2Vec را بر روی مجموعه اشعار فارسی 48 شاعر فارسی زبان آموزش دهیم. برای انجام این کار ابتدا مجموعه داده مورد نظر را دانلود میکنیم:
شکل 10: دانلود مجموعه داده اشعار فارسی.
در مرحله بعد، دادههای این مجموعهداده را از فایل میخوانیم. سپس بر روی دادهها پیشپردازش انجام میدهیم و هر مصرع از اشعار را به عنوان یک جمله یا عبارت در نظر میگیریم. در این صورت 1216286 مصرع با حداکثر 18 کلمه به دست میآید:

شکل 11: پیشپردازش مجموعه اشعار فارسی.
حال، از کتابخانه genism که دارای مدلهای جانمایی پیادهسازی شده است استفاده میکنیم و یک مدل Word2Vec بر روی مصرعهای بهدستآمده با اندازه پنجره 5 و طول بردار جانمایی 100 برای 10 دور آموزش میدهیم. علت استفاده از کتابخانه Gensim این است که مدلهای CBOW و Skip-gram که در بخشهای قبل پیادهسازی کردیم؛ به اندازه کافی برای آموزش بر روی مجموعهدادههای بزرگ بهینه نشدهاند. از این رو از مدلهای پیادهسازی شده در کتابخانه Gensim استفاده میکنیم که کارآمد، مقاوم و مقیاسپذیر هستند و می توان آنها را بر روی دادههای حجیم آموزش داد:

شکل 12: آموزش مدل Word2Vec با استفاده از کتابخانه Gensim.
در این مرحله، از مدل آموزشدادهشده استفاده میکنیم و از مدل میخواهیم برای هر یک از کلمات «خدا»، «ساغر» و «سیاوش»، سه کلمه با بیشترین میزان شباهت را در خروجی تولید کند:

شکل 13: پیدا کردن شبیهترین کلمات به کلمههای خدا، ساغر و سیاوش.
نتایج نشان میدهد که مدل بهخوبی توانسته است کلماتی که از نظر معنا شبیه هم هستند را مشخص کند و بردارهای جانمایی یکسانی را در فضای برداری به آنها اختصاص دهد. یکی از ویژگیهای مهم مدل Word2Vec این است که روابط معنایی بین کلمات را بهخوبی درک میکند. به عنوان مثال، اگر بردار مربوط به کلمه «پاریس» را با بردار جانمایی کلمه «فرانسه» جمع کنیم و از بردار حاصل، بردار مربوط به کلمه «تهران» را کم کنیم به برداری میرسیم که بسیار شبیه به بردار جانمایی کلمه «ایران» است. در قطعه کد زیر چند نمونه از این رابطهها را برای مدلی که آموزش دادهایم را نشان میدهیم:

شکل 14: پیدا کردن روابط معنایی کلمات در مدل Word2Vec آموزش داده شده.
نتیجهگیری
در این مقاله یکی از اولین روشهای پیشگام در جانمایی کلمات به نام Word2Vec را بررسی کردیم. Word2Vec به طور کارآمد امکان نمایش کلمات در یک فضای برداری پیوسته را فراهم میکند و روابط معنایی پیچیده بین کلمات را به تصویر میکشد. در پستهای آینده روشهای دیگر جانمایی کلمات مانند روش GloVe را بررسی میکنیم.

نظرات