جنگل تصادفی: همهچیز را همگان دانند!
ترجمه مهدی نورایی از مقاله random forest

چکیده
در این مقاله، الگوریتم شناختهشدهی یادگیری ماشین نظارتشدهی جنگل تصادفی را بررسی خواهیم کرد. هدف این مقاله ارائهی یک درک جامع و شهودی در مورد نحوهی عملکرد این الگوریتم است. این مباحث در ادامهی مطالبی مطرح میشود که در دو پست مربوط به درختهای تصمیم مطرح نمودیم. در آنجا به خطر بیشبرازش درختها اشاره کردیم و راههایی را برای جلوگیری از وقوع بیشبرازش مطرح کردیم. در این پست میخواهیم یک پله بالاتر رفته و به کمک درختهای تصمیم مدلی جدید را بر پایهی یادگیری جمعی معرفی کنیم که در کاربردهای عملی معمولا بسیار بهتر از درختهای تصمیم ساده عمل میکند.
مقدمه
قبل از شروع بحث خود در مورد جنگلهای تصادفی، ابتدا باید رویکرد تجمیعی را بشناسیم. رویکرد تجمیعی یک روش یادگیری جمعی ساده اما قدرتمند است. این رویکرد یک روش کلی است که میتواند برای کاهش واریانس مدلهای مختلف استفاده شود. واریانس بالاتر به این معنی است که مدل شما دچار بیشبرازش شده است.
الگوریتمهای خاصی مانند درخت تصمیم معمولا واریانس بالایی دارند. به بیان دیگر، درختهای تصمیم نسبت به دادههایی که روی آنها آموزش میبینند بسیار حساس هستند؛ یعنی اگر دادههای آموزشی حتی اندکی تغییر کنند، درخت تصمیم حاصل میتواند بسیار متفاوت باشد و در نتیجه پیشبینیهای مدل به شدت تغییر خواهند کرد.
رویکرد تجمیعی راهحلی برای مشکل واریانس بالا ارائه میدهد. این روش میتواند به طور سیستماتیک و با در نظر گرفتن میانگین چندین مدل، احتمال وقوع بیشبرازش را کاهش دهد.
رویکرد تجمیعی از نمونهگیری خودگردانساز استفاده میکند و در نهایت با میانگینگیری از مدلهای مختلف، پیشبینیهای نهایی را به دست میآورد.
نمونهگیری خودگردانساز به معنای نمونهگیری تصادفی با جایگذاری از سطرهای مجموعه دادهی آموزشی است. در شکل 1 سه مجموعه دادهی مختلف به همین روش بر مبنای مجموعه دادهی اصلی تولید شدهاند.
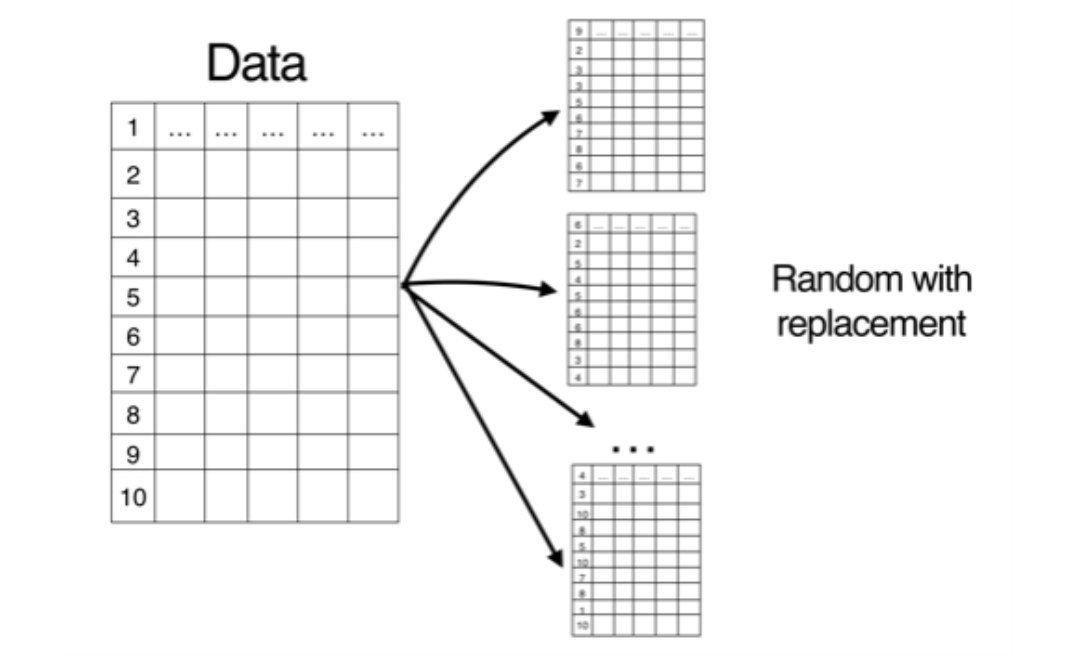
شکل 1: نحوهی اجرای نمونهگیری خودگردانساز
بنابراین با استفاده از روش تجمیعی ممکن است یک نمونهی آموزشی را بیش از یک بار مشاهده کنید. این موضوع منجر به ایجاد یک نسخهی تغییریافته از مجموعه دادهی آموزشی میشود که در آن برخی از سطرها چندین بار مشاهده میشوند و برخی دیگر ممکن است اصلا مشاهده نشوند.
این فرایند به شما امکان تولید مجموعه دادههای جدیدی مشابه مجموعه دادهی اصلی را میدهد. با کمک این مجموعه دادهها میتوانید تعداد زیادی از مدلهای مختلف اما مشابه را آموزش بدهید.
نحوهی عملکرد روش تجمیعی
قدم اول: ابتدا B نمونهی تصادفی با جایگذاری را از مجموعه دادهی اصلی انتخاب میکنیم که در آن B عددی کوچکتر یا مساوی با n یعنی تعداد کل نمونهها در مجموعه دادهی آموزشی است. این فرایند دو شکل 2 نمایش داده شده است.
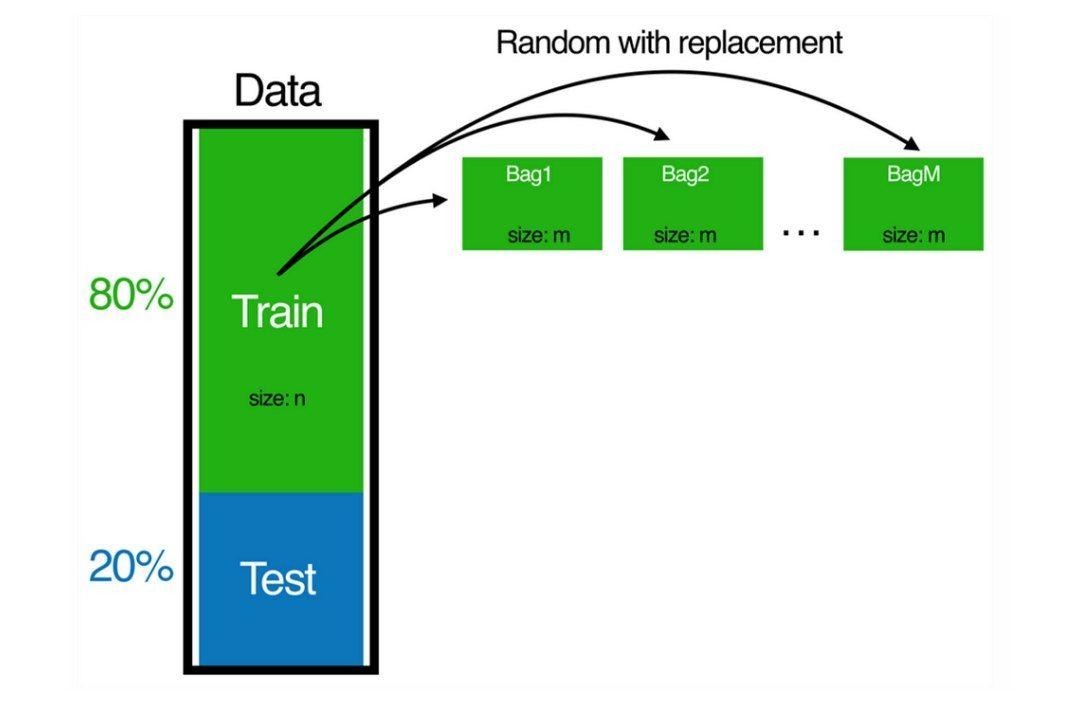
شکل 2: اجرای نمونهگیریهای باجایگذاری و ساخت نمونههای آموزشی جدید
قدم دوم: روی هر مجموعه دادهای که در قدم اول ایجاد شده است، یک درخت تصمیم جداگانه را آموزش دهید. مرحلهی اول و دوم را به تعداد دلخواه تکرار کنید.
به طور کلی افزایش تعداد درختان، نتیجهی بهتری را به همراه دارد اما توجه داشته باشید که افزایش بیش از حد تعداد درختها میتواند مدل را بیش از اندازه پیچیده کند و در نهایت منجر به بیشبرازش مدل شود(همان خطری که سعی داشتیم از آن فاصله بگیریم)؛ زیرا مدل شروع به دیدن روابط پیچیدهای در مجموعه دادهها میکند که در مجموعه دادهی آزمونی وجود ندارند و باعث کاهش تعمیمپذیری مدل میشوند. در شکل 3 نحوهی اجرای مرحلهی دوم را ملاحظه میکنید.
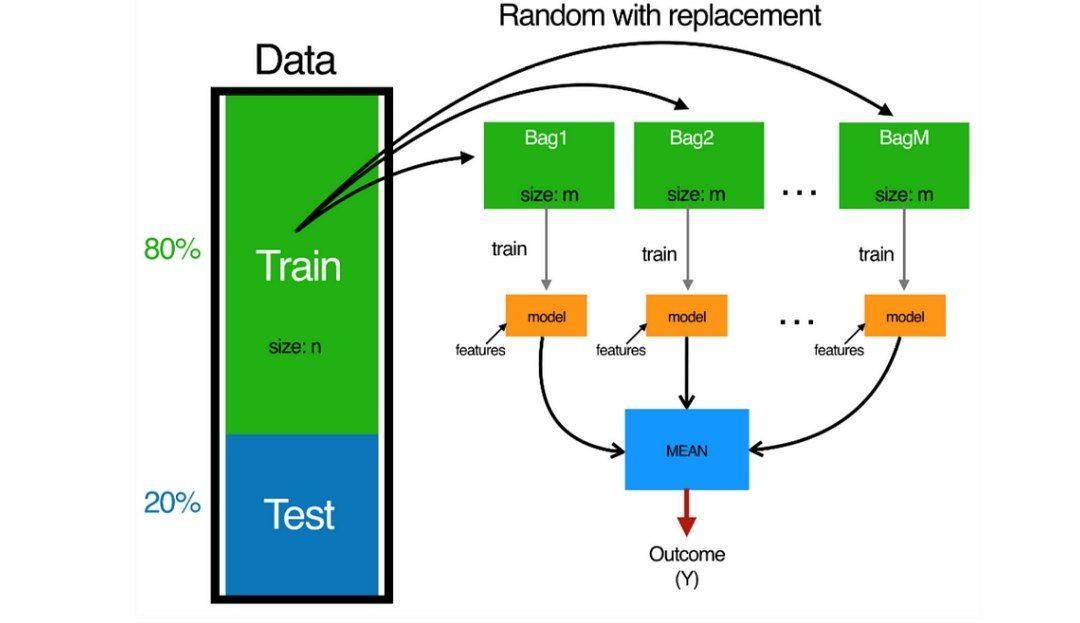
شکل 3: روی هر مجموعهی آموزشی جدید یک درخت تصمیم را آموزش میدهیم
برای انجام پیشبینی با استفاده از رویکرد تجمیعی، باید به کمک هر یک از درختهای تصمیم یک پیشبینی انجام دهید و سپس از تمام پیشبینیها میانگینگیری کنید تا پیشبینی نهایی را به دست بیاورید.
پیشبینی گروهی در واقع میانگین پیشبینیها در بین درختهای حاصل از نمونهگیری خودگردانساز است.
روش تجمیعی شبیه به یک شورای تصمیمگیری عمل میکند. معمولا وقتی یک شورا نیاز به تصمیمگیری دارد، صرفا رأی اکثریت را ملاک قرار میدهد. گزینهای که رای بیشتری بیاورد در نهایت تصمیم نهایی شورا خواهد بود. به طور مشابه در روش تجمیعی، هنگامی که در تلاش برای حل مسالهی طبقهبندی هستیم، اساسا رای اکثریت همهی درختهای تصمیم پیشبینی نهایی شما را مشخص میکند.
در صورتی که با یک مسالهی رگرسیونی مواجه هستید، میانگین تمام پیشبینیهای درختهای تصمیم، پیشبینی نهایی شما را تعیین خواهد کرد.
در فارسی میگوییم «همهچیز را همگان دانند» یا «هر سر یک فکر خاصی دارد» بنابراین مجموعهی متنوعی از درختهای تصمیم معمولاً در انجام پیشبینی از هر درخت تصمیم منفرد بهتر عمل میکنند. در مجموع روش تجمیعی استفاده از درختهای تصمیم معمولا عملکرد بهتری را در انجام پیشبینی ارائه میدهد.
جنگلهای تصادفی
الگوریتم جنگل تصادفی از یک جهت با استفادهی صرف از رویکرد تجمیعی معرفیشده در بالا متفاوت است. درختهای جنگل تصادفی از یک الگوریتم یادگیری اصلاحشده استفاده میکنند که در آن هر درخت تصمیم روی تنها زیرمجموعهای تصادفی از متغیرهای مستقل آموزش میبیند.
این کار برای جلوگیری از ایجاد همبستگی و شباهت بین درختهای تصمیم انجام میشود. فرض کنید یک متغیر مستقل بسیار مهم در مجموعهی داده به همراه تعدادی دیگر از پیشبینیکنندههای نسبتا قوی داریم؛ اگر صرفا از رویکرد تجمیعی استفاده کنیم، اکثر یا همهی درختهای تصمیم از پیشبینیکنندهی بسیار قوی برای انجام تقسیم در گره اول استفاده میکنند. بنابراین همهی درختهای تصمیم شبیه به یکدیگر خواهند بود. از این رو پیشبینیهای تمام درختها همبستگی بسیار بالایی خواهند داشت. میدانیم که مشابهت پیشبینیهای درختها نمیتواند در بهبود دقت پیشبینی کل کمک کند.
جنگل تصادفی با در نظر گرفتن یک زیرمجموعهی تصادفی از ویژگیهای مستقل در هر درخت، به طور سیستماتیک از ایجاد مشابهت بین درختها اجتناب میکند و با این روش عملکرد مدل را بهبود میبخشد. شکل 3 نحوهی عملکرد جنگل تصادفی را نمایش میدهد.
فرض کنید که در حال تلاش برای حل یک مسالهی دستهبندی هستیم. همانطور که در شکل 4 مشهود است، داده های آموزشی ما دارای چهار ویژگی یا Feature است.
مدل بر روی هر یک از دادههای حاصل از نمونهگیری خودگردانسازی و بر روی زیرمجموعهی خاصی از ویژگیها آموزش داده میشود. به عنوان مثال، درخت تصمیم اول روی ویژگیهای 1 و 4 آموزش داده میشود. درخت تصمیم دوم روی ویژگیهای 2 و 4 و در نهایت درخت تصمیم سوم روی ویژگیهای 3 و 4 آموزش میبیند. بنابراین ما 3 مدل مختلف خواهیم داشت که هر کدام روی زیرمجموعهای از ویژگیها آموزش داده میشوند.
در نهایت دادهی آزمونی جدید خود را به هر یک از این مدلها میدهیم و از هرکدام یک پیشبینی دریافت میکنیم. پیشبینیای که بیشترین تعداد رای را در بین درختها کسب کند، تصمیم نهایی الگوریتم جنگل تصادفی خواهد بود.
به عنوان مثال در شکل 4، درخت اول و سوم کلاس مثبت را برای یک نمونهی آزمونی پیشبینی کردهاند؛ در حالی که درخت دوم آن را یک نمونه از کلاس منفیها تشخیص داده است.
از آنجایی که کلاس مثبت اکثریت آرا را به دست آورده است، جنگل تصادفی ما در نهایت این نمونه را به عنوان یک نمونهی مثبت پیشبینی میکند.
مجددا بر این نکته تأکید میکنیم که الگوریتم جنگل تصادفی از زیرمجموعههایی تصادفی از ویژگیها برای آموزش مدلها استفاده میکند. بنابراین هر مدل فقط زیرمجموعهی خاصی از ویژگیهای موجود در مجموعه داده را مشاهده میکند.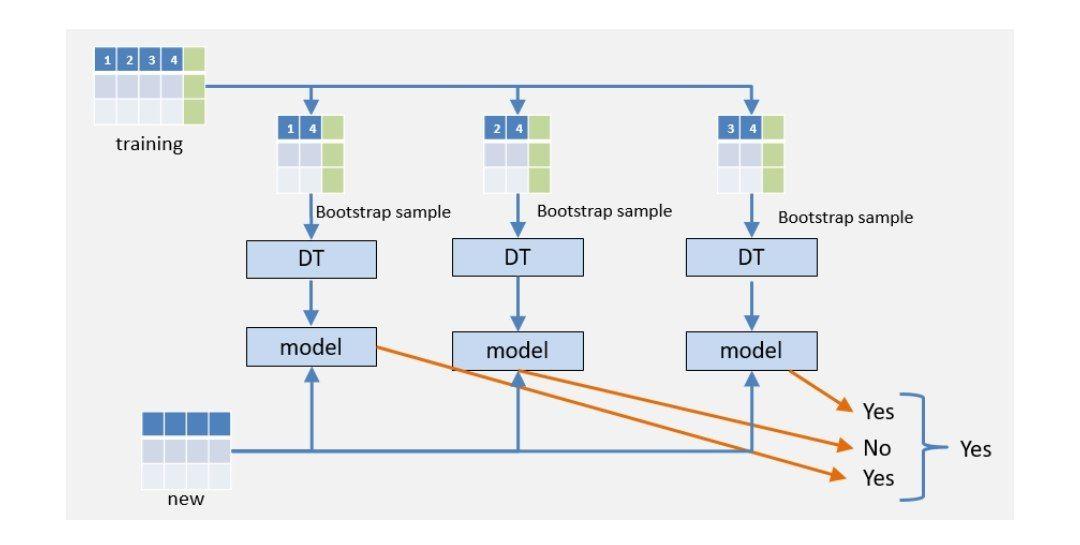
شکل 4: نحوهی انجام پیشبینی در درختهای تصمیم
جنگل تصادفی یکی از پرکاربردترین الگوریتمهای یادگیری گروهی است. چرا این الگوریتم اینقدر مفید و مؤثر است؟ دلیل آن این است که جنگل تصادفی با استفاده از نمونههای تصادفی مختلف از مجموعه دادهی اصلی، واریانس مدل نهایی را کاهش میدهد. به یاد داشته باشید که واریانس کم به معنای جلوگیری از مشکل بیشبرازش است.
بیشبرازش زمانی اتفاق میافتد که مدل سعی میکند تا تغییرات کوچک و بیمعنی مجموعه دادهی آموزشی را نیز توضیح دهد. از آنجا که مجموعه دادهی ما فقط نمونهی کوچکی از جمعیت همهی نمونههای تصادفی ممکن از پدیدهای است که سعی میکنیم مدل کنیم، ممکن است روابط جزیی و بیمعنیای در آن موجود باشد.
به عنوان مثال ممکن است همهی کسانی که در مجموعه دادهی ما نامشان «امیر» ثبت شده است، دارای بدهی بانکی باشند. اگر در مرحلهی نمونهگیری از جامعهی هدف کمی بدشانس باشیم، ممکن است برخی از پدیدههای نامطلوب (اما اجتنابناپذیر) را در مجموعه دادهمان مشاهده کنیم مانند نویز، دادههای پرت و نمونههایی که بیشازحد یا کمتر از انتظار(نسبت به جامعهی هدف) ظاهر شدهاند.
با ایجاد چندین نمونهی تصادفی با جایگذاری از مجموعه آموزشی، تأثیر این پدیدهها را تا حد امکان کاهش میدهیم.
مثال عملی
در این قسمت نحوهی پیادهسازی الگوریتم جنگل تصادفی را در پایتون خواهیم دید. تمام مراحل لازم (از جمله چند کار مربوط به پیشپردازش داده) را شرح خواهیم داد.
پیشپردازش مجموعه داده
ما از مجموعه دادهی bank-full-additionaldatabase.csvبرای اجرای این پیادهسازی استفاده خواهیم کرد.
این مجموعه داده در مورد کمپینهای بازاریابی یک موسسه بانکی پرتغالی است. این کمپینهای بازاریابی مبتنی بر تماسهای تلفنی بودهاند. با استفاده از ویژگیهایی مانند سن، شغل، وضعیت تاهل، تحصیلات و غیره، سعی میکنیم تا پیشبینی کنیم که آیا مشتری مشترک سپرده مدتدار شده است یا خیر. ابتدا مجموعه داده را فراخوانی میکنیم: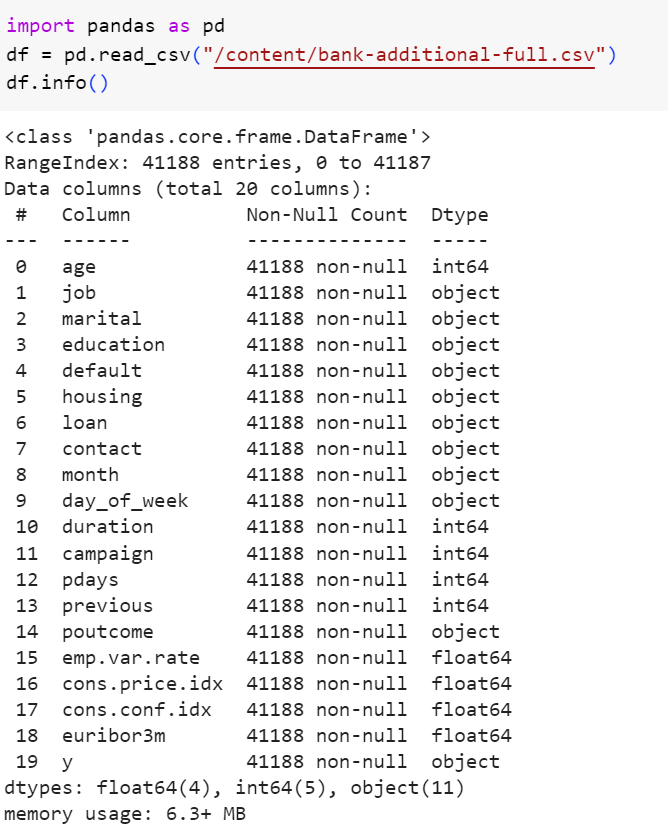
شکل 5: فراخوانی مجموعه داده در محیط پایتون
شکل 6: نگاه کلی به متغیرهای موجود در مجموعه داده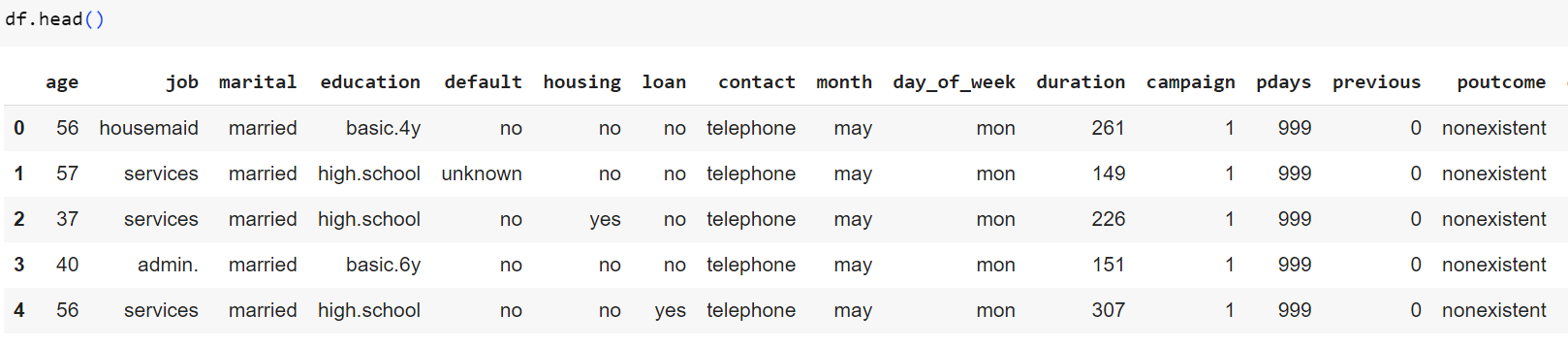
با نگاهی به مجموعه داده میبینیم که برخی از ویژگیها مانند شغل، تحصیلات و... ماهیت گسسته دارند. بنابراین برای استفاده از آنها، ابتدا باید آنها را کدگذاری نموده و متغیرهای مجازی مناسبی را براساس آنها بسازیم تا کتابخانهی sklearn بتواند با آنها کند. این کار را با استفاده از متد pd.get_dummies از کتابخانهی pandas انجام میدهیم.
شکل 7: ایجاد متغیرهای مجازی برای متغیرهای گسسته
اکنون آماده هستیم تا مجموعه داده را به مجموعههای آموزشی و آزمونی تقسیم کنیم تا در نهایت الگوریتم جنگل تصادفی را اجرا کنیم. خطوط کد زیر برچسبهای y را از متغیرهای مستقل جدا میکند و مجموعه داده را به بخشهای آموزش و آزمون تقسیم میکند. 30 درصد از دادهها را برای آزمون مدل جدا میکنیم:

شکل 8: آمادهسازی مجموعه دادهی آموزشی و آزمونی
آموزش و آزمون دستهبندی مدل جنگل تصادفی
اکنون زمان آن رسیده است که مدل جنگل تصادفی دستهبندیکنندهی خود را برازش دهیم. n_estimators را برابر 1000 قرار دادیم که به این معنی است که جنگل تصادفی کننده ما در مجموع 1000 درخت تصمیم خواهد داشت.
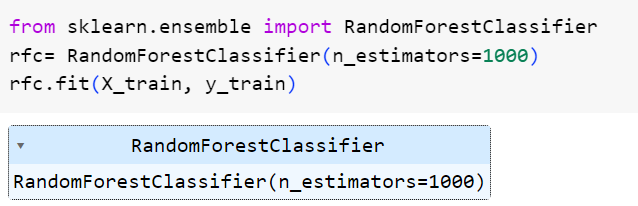
شکل 9: آموزش مدل جنگل تصادفی
اکنون داده های آزمونی خود را به مدل میدهیم. در این قسمت چند ماژول دیگر را برای دسترسی به ماتریس درهمریختگی، صحت و گزارش عملکرد مدل فراخوانی کردهایم.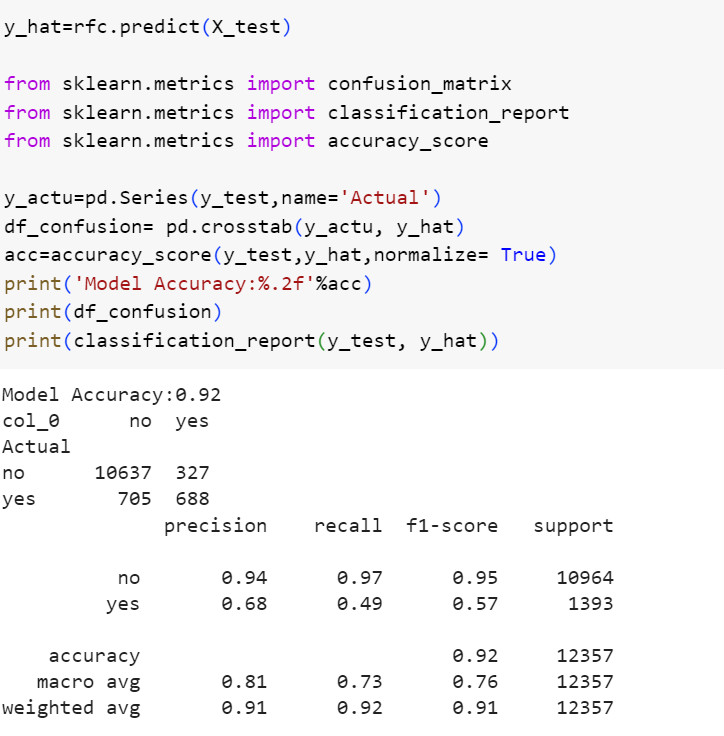
شکل 10: گزارش عملکرد مدل جنگل تصادفی
خلاصهی عملکرد مدل در گزارش بالا قابل مشاهده است. صحت کلی مدل برابر 0.92 است که مقدار خوبی را نشان میدهد. مقادیر دقت و بازیابی برای کلاس مثبت خیلی پایینتر از کلاس منفی است. این موضوع بیان میکند که مدل، کلاس منفی را بسیار راحتتر از کلاس مثبت شناسایی میکند. بنابراین اگر شناسایی کلاس مثبت برایمان از اهمیت بالاتری برخوردار است، بهتر است به سراغ روشهای ابتکاری رفته و تلاش کنیم تا با تغییر تابع خطای مدل و با افزودن عبارات منظمساز به آن، مدل را مجبور کنیم که در فرایند یادگیری به کلاس مثبت توجه بیشتری کند و در صورتی که از آن تخطی کند، جریمهی سنگینی را بپردازد.
مزایای جنگل تصادفی
- دقت بالا: جنگل تصادفی به طور کلی دقت بالایی را با کاهش واریانس ناشی از درختهای تصمیم منفرد فراهم میکند. این مدل، پیشبینیهای چندین درخت تصمیم را با هم ترکیب میکند و به این صورت خطر وقوع بیشبرازش را کاهش میدهد و تعمیمپذیری مدل را بهبود میبخشد.
- مناسب مجموعه دادههای بزرگ: جنگل تصادفی بر روی مجموعه دادههای بزرگ به خوبی کار میکند. از آنجا که مجموعه دادههای زیادی به کمک نمونهگیری خودگردانساز ایجاد میشوند که معمولا از مجموعه دادهی اصلی کوچکترند و همچنین از آنجا که هر درخت تصمیم تنها روی زیرمجموعهای از مجموعهی ویژگیها آموزش میبیند، مدل میتواند تعداد زیادی از ویژگیها و نمونهها را به طور موثری مدیریت کند.
- مقاوم در برابر دادههای پرت: جنگل تصادفی نسبت به دادههای پرت مقاوم است، زیرا مدل از پیشبینیهای چندین درخت تصمیم میانگینگیری میکند. بنابراین دادههای پرت موجود در درختها تأثیر کمتری در پیشبینی نهایی خواهند داشت.
- کشف میزان اهمیت ویژگیها: جنگل تصادفی راهی برای کشف اهمیت هر ویژگی در مجموعه داده را ارائه میدهد. ویژگیهایی که در درختهای تصمیم بیشتری مورد توجه قرار گرفتهاند، ویژگیهای مهمتری هستند. بنابراین جنگل تصادفی به شما این امکان را میدهد که کشف کنید کدام ویژگیها بیشترین سهم را در پیشبینی کلی دارد. این اطلاعات میتواند برای انتخاب ویژگیهای مهم و درک منطق درونی دادهها ارزشمند باشد.
- کاهش خطر بیشبرازش: جنگل تصادفی با میانگینگیری پیشبینیهای چندین درخت تصمیم به کاهش خطر بیشبرازش کمک میکند. این مدل با افزودن تصادفیسازی در مراحل ساخت مدل، سطحی از منظمسازی را فراهم میکند که میتواند از بیشبرازش مدل تا حد خوبی جلوگیری کند.
- مدیریت دادههای گمشده: جنگل تصادفی میتواند مقادیر از دست رفته را بدون نیاز به جانهی مدیریت کند. این مدل مقادیر از دست رفته را به عنوان یک دستهی جداگانه در طول فرایندهای تقسیم در نظر میگیرد و از اطلاعات موجود در ویژگیهای دیگر بهره میبرد.
- قابلیت موازیسازی: جنگل تصادفی را میتوان به راحتی موازیسازی کرد؛ به این معنا که این مدل میتواند در مراحل محاسباتی از چندین هسته یا پردازندهی محاسباتی استفاده کند. این کار مدل را از نظر محاسباتی کارآمدتر میکند و امکان آموزش مدل روی مجموعه دادههای بزرگ را نیز فراهم میکند.
معایب جنگل تصادفی
- پیچیدگی: مدلهای جنگل تصادفی میتوانند از نظر محاسباتی گران و در فرایند آموزش، آهسته باشند؛ مخصوصا زمانی که تعداد درختها بالا است یا درختها عمق زیادی داند. با این حال، این مشکل احتمالی میتواند با موازیسازی فرایند آموزش و استفاده از تکنیکهایی مانند توقف زودهنگام فرایند آموزش رفع شود.
- عدم تفسیرپذیری: در حالی که جنگل تصادفی میزان اهمیت ویژگیها را مشخص میکند، به عنوان یک کل به راحتی قابل تفسیر نیست. به دلیل ماهیت مبتنی بر یادگیری گروهی این الگوریتم، درک منطق پنهان فرایند تصمیمگیری و انجام پیشبینیها میتواند چالشبرانگیز باشد.
- بیشبرازش بر روی دادههای نویزی: اگر جنگل تصادفی به درستی تنظیم نشود، میتواند بر روی دادههای نویزی دچار بیشبرازش شود. ویژگیهای نویزی پرتعداد یا ویژگیهای نامربوط میتوانند منجر به بیشبرازش مدل شوند. بنابراین انتخاب ویژگیهای ورودی مدل و تنظیم ابرپارامترها از اهمیت بالایی برخوردار است.
- سوگیری نسبت به کلاسهای پرتعداد: جنگل تصادفی متمایل به کلاسهای پرتعداد است. این موضوع به طور بالقوه اهمیت سایر کلاسهای با تعداد کمتر را تضعیف میکند. این مشکل را میتوان با استفاده از تکنیکهایی مانند ایجاد جایگشت در مجموعه داده و یا استفاده از نمونهگیری طبقهبندیشده در هنگام تقسیم مجموعه دادهی اصلی به مجموعه دادههای آموزشی و آزمونی کنترل کرد.
- مصرف حافظه: جنگل تصادفی میتواند مقدار قابل توجهی حافظه مصرف کند؛ به خصوص زمانی که با مجموعه دادههای بزرگ یا تعداد زیادی درخت تصمیم سروکار داریم. هنگام کار با جنگل تصادفی مهم است که به محدودیت های منابع محاسباتی نیز توجه داشته باشیم.
منبع
https://medium.com/@harshdeepsingh_35448/understanding-random-forests-aa0ccecdbbbb

نظرات