آشنایی با یادگیری تقویتی

امروزه کاربردهای هوش مصنوعی بسیار فراگیر شده تا آنجا که اثر آن را در تمامی ابعاد زندگی بشر از آموزش و مدیریت تا سرگرمی و تجارت میتوان یافت. یادگیری ماشین (Machine Learning) یکی از زیر مجموعههای مهم هوش مصنوعی< است که این امکان را برای سیستمها فراهم میکند تا با دسترسی به دادهها و آموختن از آنها بتوانند به درستی عمل کنند.
بهطور کلی یادگیری ماشین به سه دسته تقسیم میشود: یادگیری نظارتی (Supervised learning)، یادگیری غیرنظارتی (Unsupervised learning) و یادگیری تقویتی (Reinforcement learning). در یادگیری نظارتی هم جواب درست موجود است و هم دادهها برچسبگذاری شدهاند. از این مدل برای دستهبندی دادهها استفاده میشود. در یادگیری غیرنظارتی خبری از دادههای برچسبگذاری شده نیست، در واقع با به کارگیری الگوریتمها، دادهها دستهبندی میشوند و در آخر یادگیری تقویتی به وسیله یک عامل (agent) و نیز طی تعامل با محیط و آزمون و خطا سیستم آموزش میبیند. در ادامه این مقاله، سعی داریم با مفهوم یادگیری تقویتی بیشتر آشنا شویم.
یادگیری تقویتی چیست؟
یادگیری تقویتی به معنای یادگیری به وسیله کنش و واکنش با یک محیط خارجی معمولا نامشخص و پویا است. تصمیمگیرنده که عامل(agent) نامیده میشود، در یک عملیات آزمون و خطا (Trial and Error) به مرور زمان، هدف مشخصی را یاد میگیرد. یادگیری تقویتی به طور گستردهای در رباتیک (Robotics) و طراحی سیستمهای خودمختار (Autonomous Systems Design) کاربرد دارد.
|
|
|
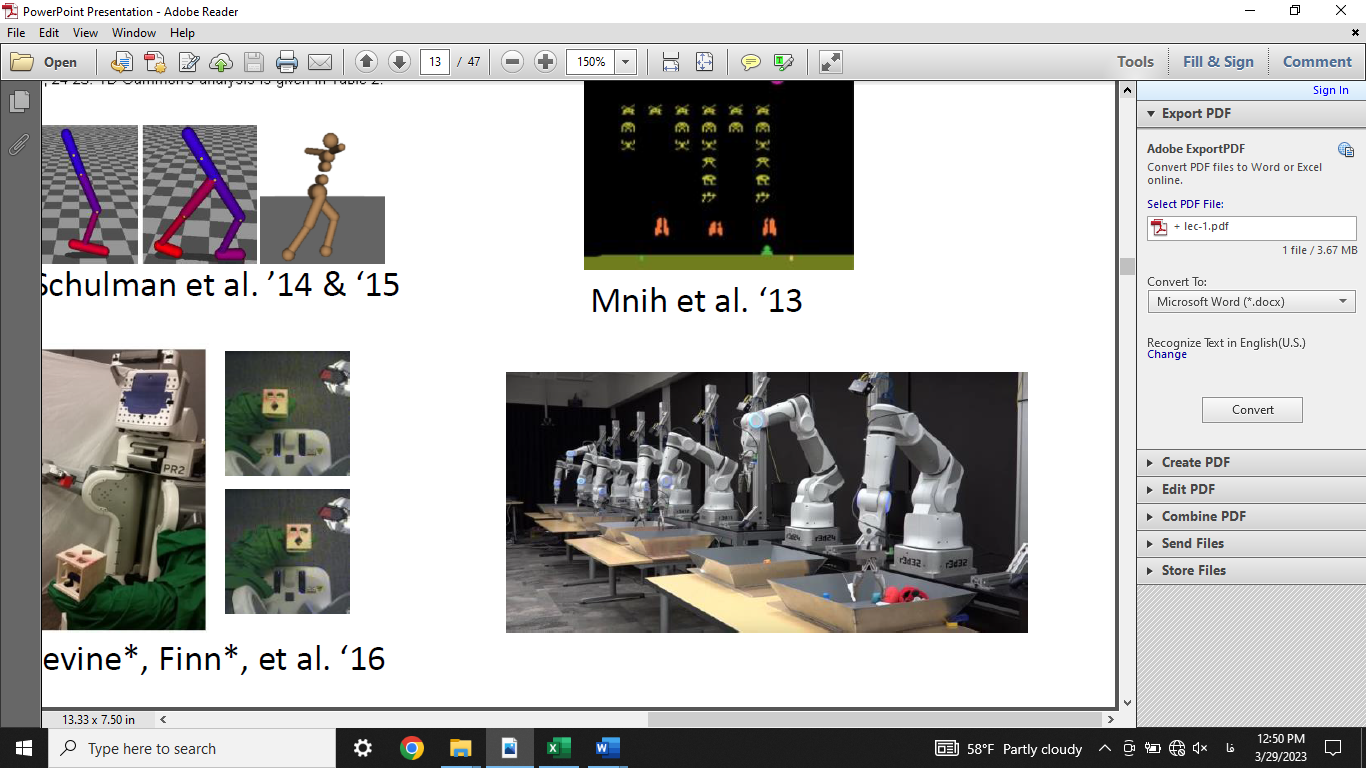
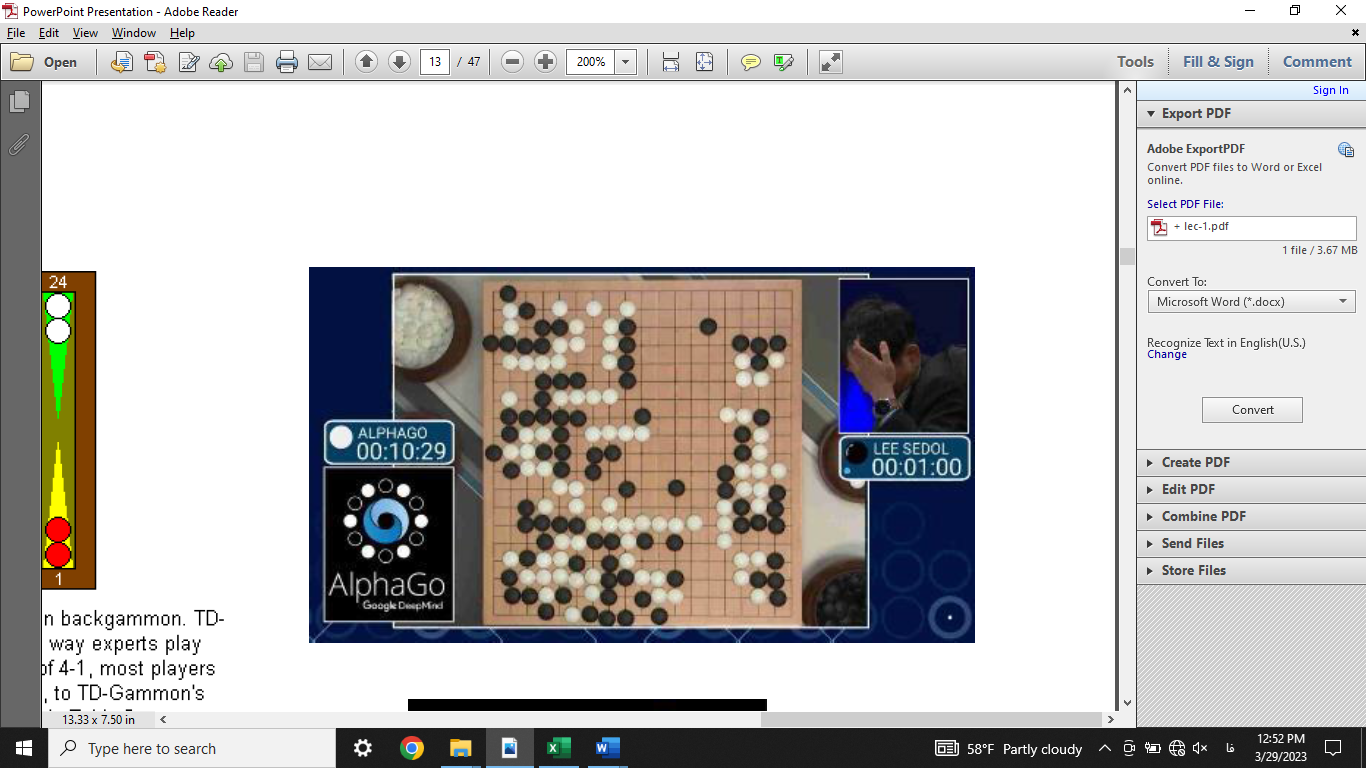
مشهورترین الگوریتم بهکار رفته در سیستمهای یادگیری تقویتی، Q-learning نام دارد که توسط واتکینز و دایان در سال 1992 میلادی ارائه شده است. این الگوریتم تاکنون برای حل بسیاری از مسائل دنیای واقعی به کار رفته، اما توانایی حل مسائل با بعد بالا را ندارد؛ چرا که محاسبات آن با افزایش تعداد ورودیهای مساله به طور قابل توجهی افزایش مییابد. این چالش که مشقت بعدچندی (Curse of Dimensionality) نام دارد، با ترکیب یادگیری تقویتی با شبکههای عصبی عمیق در سال 2015 توسط امنیه و همکارانش تا حد خوبی از میان برداشته شد. یادگیری تقویتی عمیق (Deep Reinforcement Learning) از آن پس به شدت مورد توجه محققان هوش مصنوعی قرار گرفته است. در بخش بعد با سیستمهای یادگیری تقویتی ساده و عمیق آشنا خواهیم شد.
اصطلاحات حوزه یادگیری تقویتی
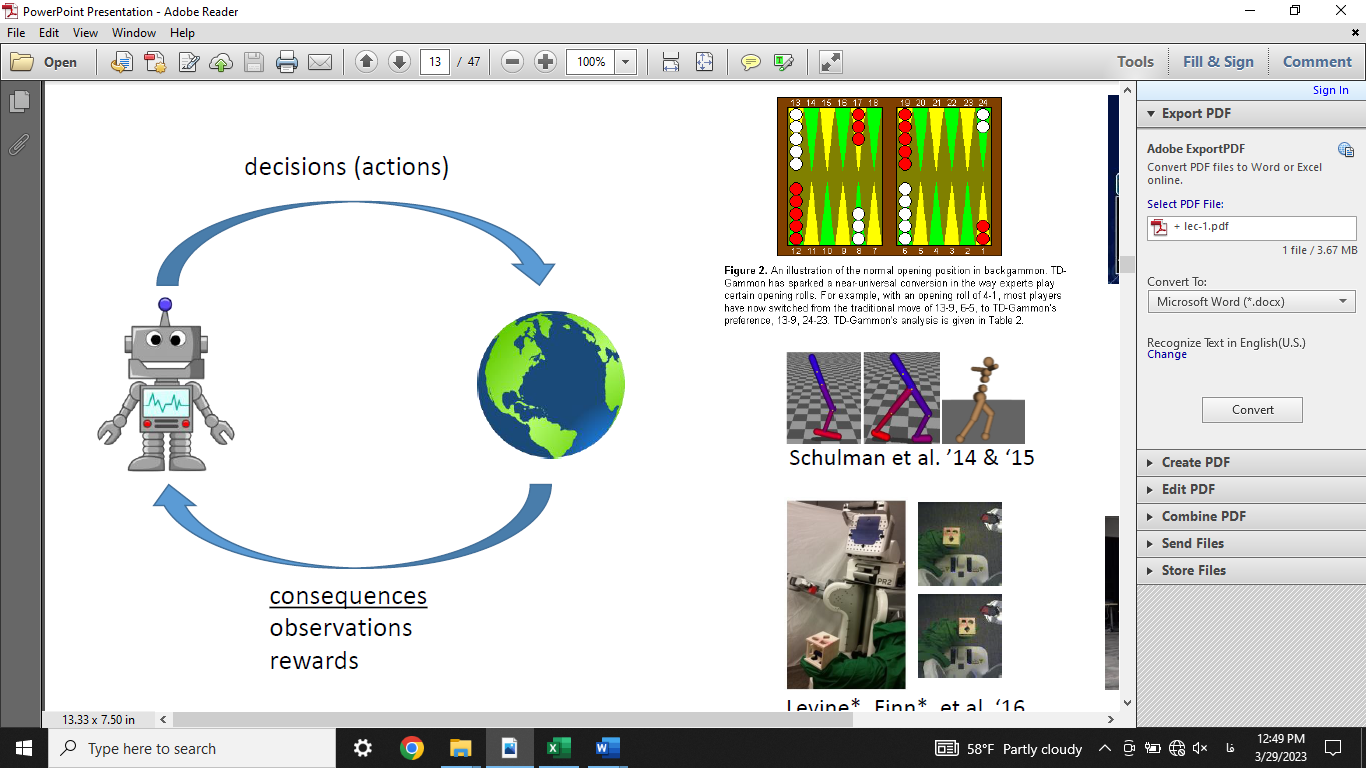
در الگوریتمهای یادگیری تقویتی، کنش و واکنشهای میان عامل و محیط با سه عنصر کلیدی توصیف میشود: حالت (state)، حرکت (action) و پاداش (reward). حالت محیط در زمان 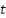 با
با 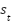 نشان داده میشود. در این زمان، عامل حرکت
نشان داده میشود. در این زمان، عامل حرکت 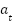 را انجام میدهد و پاداش
را انجام میدهد و پاداش 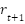 را دریافت میکند. در نتیجه این حرکت، محیط به حالت
را دریافت میکند. در نتیجه این حرکت، محیط به حالت 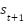 میرود. این فرآیند در شکل زیر نشان داده شده است.
میرود. این فرآیند در شکل زیر نشان داده شده است.
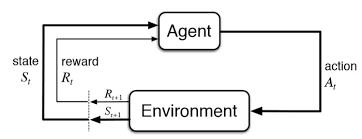
با توجه به آنچه گفته شد، کنش و واکنشهای میان عامل و محیط را میتوان توسط دنبالهای به شکل 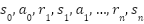 نشان داد. این دنباله از حالتها، حرکتها و پاداشها از حالت اولیه تا حالت انتهایی سیستم، یک اپیزود (Episode) نام دارد. هدف آن است که در یک اپیزود، مجموع پاداشهای کسب شده توسط عامل بیشینه شود.
نشان داد. این دنباله از حالتها، حرکتها و پاداشها از حالت اولیه تا حالت انتهایی سیستم، یک اپیزود (Episode) نام دارد. هدف آن است که در یک اپیزود، مجموع پاداشهای کسب شده توسط عامل بیشینه شود.
سیاست (Policy) یک نگاشت از مجموعه حالات به مجموعه حرکات است که توسط عامل تصمیمگیرنده برای رسیدن به نتیجه مطلوب اتخاذ میشود. در صورتی که هر حالت محیط، تنها به حالت قبلی و حرکت انجام شده توسط عامل (و نه تاریخچه حالات و حرکات) بستگی داشته باشد، مساله یک فرآیند تصمیمگیری مارکوف (Markov Decision Process) خواهد بود.
هدف عامل در هر مرحله نباید تنها رسیدن به بیشینه پاداش ممکن در همان مرحله باشد؛ بلکه باید پاداش قابل کسب در دراز مدت را مدنظر خود قرار دهد. میزان اهمیت پاداشهایی که در مراحل آینده (نسبت به مرحله فعلی) به دست خواهند آمد، نیز در مسائل مختلف متفاوت است. در نتیجه در تعریف مساله، ارزش بازگشتی (Return Value) زیر را برای مرحله تعریف میکنیم.
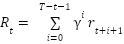
که در آن 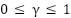 فاکتور کاهشی نام دارد. اگر این فاکتور به یک نزدیکتر باشد، عامل دوراندیش و اگر به صفر نزدیک باشد، عامل کوتاهبین است.
فاکتور کاهشی نام دارد. اگر این فاکتور به یک نزدیکتر باشد، عامل دوراندیش و اگر به صفر نزدیک باشد، عامل کوتاهبین است.
تابع ارزش (Value Function) حالت 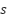 در صورتی که سیاست
در صورتی که سیاست 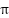 اخذ شود، برابر با امید ریاضی پاداش کسب شده از حالت تحت این سیاست تعریف و با
اخذ شود، برابر با امید ریاضی پاداش کسب شده از حالت تحت این سیاست تعریف و با 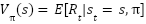 نشان داده میشود. تابع ارزش زوج حالت-حرکت
نشان داده میشود. تابع ارزش زوج حالت-حرکت 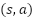 نیز توسط
نیز توسط 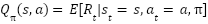 نشان داده میشود که بیانگر امید ریاضی پاداش کسب شده با شروع از حالت و انجام حرکت
نشان داده میشود که بیانگر امید ریاضی پاداش کسب شده با شروع از حالت و انجام حرکت 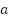 تحت سیاست میباشد. هدف عامل آن است که به سیاست بهینه دست یابد. چنین سیاستی توانایی آن را دارد تا معادله زیر را که به معادله بلمن (Bellman Equation) معروف است، ارضاء نماید.
تحت سیاست میباشد. هدف عامل آن است که به سیاست بهینه دست یابد. چنین سیاستی توانایی آن را دارد تا معادله زیر را که به معادله بلمن (Bellman Equation) معروف است، ارضاء نماید.
| ||
|
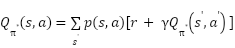
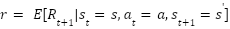
مروری بر چند الگوریتم یادگیری تقویتی
الگوریتمهای یادگیری تقویتی بسیار متنوع هستند، در صورتی که بخواهیم از الگوریتمهای یادگیری تقویتی در پروژه خود استفاده کنیم، لازم است بدانیم کدام الگوریتم را باید برای چه فرآیندی بهکار بگیریم. در ادامه به بررسی الگوریتم Q-learning به عنوان مشهورترین الگوریتم یادگیری تقویتی و همچنین چند الگوریتم یادگیری تقویتی عمیق میپردازیم.
الگوریتم Q-learning
مشهورترین روش برای به دست آوردن سیاست بهینه الگوریتم Q-learning نام دارد. این الگوریتم نیاز به هیچگونه دانشی راجع به احتمال انتقال بین حالات (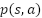 ) ندارد و در آن توابع ارزش به صورت زیر بروزرسانی میشوند.
) ندارد و در آن توابع ارزش به صورت زیر بروزرسانی میشوند.
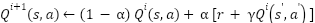
که در آن 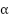 پارامتر اندازه گام (step size) نام دارد. معادله فوق را میتوان به صورت زیر بازنویسی کرد.
پارامتر اندازه گام (step size) نام دارد. معادله فوق را میتوان به صورت زیر بازنویسی کرد.
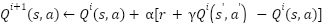
الگوریتم بالا در حل مسائل ساده توانایی فوقالعادهای دارد؛ اما برای حل مسائل پیچیده، برای مثال فضاهای با بعد بالا یا دارای فضای حالت یا حرکت پیوسته، برای تخمین توابع ارزش کارایی آن کاهش مییابد. در چنین مسائلی، شبکههای عصبی بسیار مفید واقع میشوند.
یادگیری تقویتی عمیق و شبکه DQN
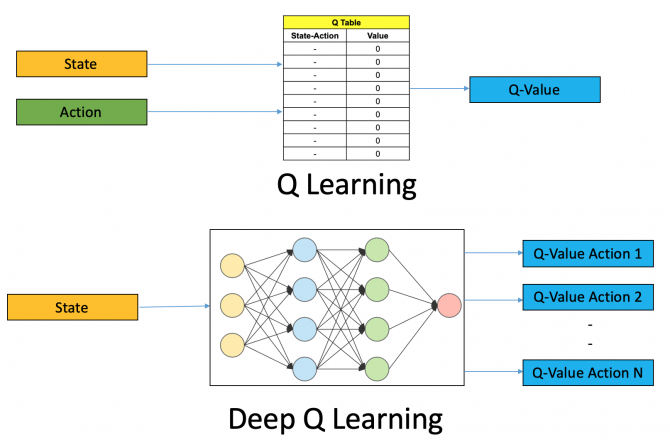
مشهورترین شبکه در حوزه یادگیری تقویتی تکعامله، شبکه عمیق Q19 (Deep Q-Network) و یا به اختصار DQN نام دارد. برخلاف الگوریتم اولیه، که مقادیر Q به ازای هر حالت و حرکت در یک جدول ذخیره میشوند، ورودی DQN حالت محیط در هر مرحله و خروجی آن، مقادیر Q به ازای حرکات ممکن قابل انجام توسط عامل است. دو شکل زیر تفاوت الگوریتم Q-learning در نسخههای عادی (تصویر بالا) و عمیق (تصویر پایین) را نشان میدهند.
|
|
شبکه DQN نمونههایی را به شکل 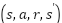 از یک حافظه بازپخش (Replay Memory) نمونهگیری میکند و از آنها برای آموزش شبکه اصلی استفاده میکند که شبکه سیاست (Policy Network) نام دارد و پارامترهای آن با مجموعه
از یک حافظه بازپخش (Replay Memory) نمونهگیری میکند و از آنها برای آموزش شبکه اصلی استفاده میکند که شبکه سیاست (Policy Network) نام دارد و پارامترهای آن با مجموعه 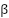 نشان داده میشوند. سپس در هر مرحله، تابع ضرر زیر در شبکه سیاست کمینه میشود.
نشان داده میشوند. سپس در هر مرحله، تابع ضرر زیر در شبکه سیاست کمینه میشود.
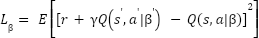
که در آن 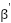 پارامترهای شبکه هدف (Target Network) است. شبکه هدف، همان شبکه سیاست میباشد که پارامترهای آن در هر N گام بروزرسانی میشوند. این عمل به دلیل پایداری سیستم و همچنین افزایش سرعت همگرایی آن صورت میگیرد. شکل زیر ساختار این شبکه را نشان میدهد.
پارامترهای شبکه هدف (Target Network) است. شبکه هدف، همان شبکه سیاست میباشد که پارامترهای آن در هر N گام بروزرسانی میشوند. این عمل به دلیل پایداری سیستم و همچنین افزایش سرعت همگرایی آن صورت میگیرد. شکل زیر ساختار این شبکه را نشان میدهد.
در معماری شبکه DQN اغلب از لایههای حلقوی (Convolutional) استفاده میشود که قادر هستند تنها با گرفتن تصویر خامی از محیط بازی، ویژگیها و حالت آن را کشف نمایند. روش DQN علیرغم حل بسیاری از مسائل دنیای واقعی، اشکالات زیادی دارد که در نسخههای ارائه شده پس از آن بهبود یافتهاند. این تغییرات در ساختار یا معماری شبکه، تعریف توابع ضرر، نوع بهینهسازی شبکه و یا نوع به کارگیری حافظه بازپخش، برای نمونه حافظه بازپخش اولویتبندی شده (Prioritized replay memory) مشاهده میشوند.
شبکه DDQN
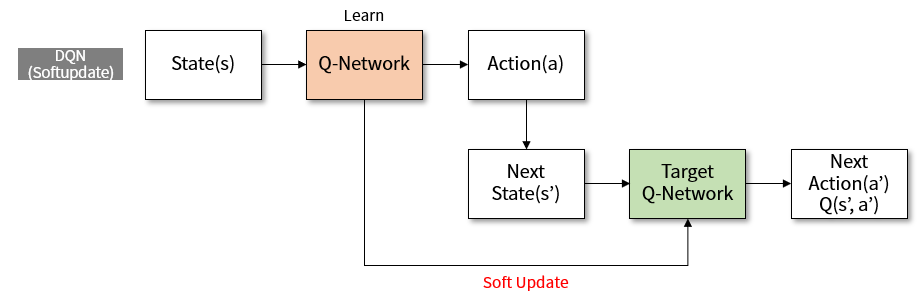
به عنوان مشهورترین نسخه بهبود یافته DQN میتوان به شبکه عمیق Q مضاعف (Double Deep Q-Network ) یا به اختصار DDQN اشاره نمود که توسط هزلت در سال 2016 میلادی ارائه شده است. هزلت نشان میدهد که از آنجایی که در تابع ضرر روش DQN از تابع max استفاده میشود، مقادیر Q که توسط این روش تخمین زده میشوند معمولا از مقدار واقعی بزرگتر هستند.
برای رفع این مشکل، در روش DDQN از دو شبکه سیاست کاملا مشابه استفاده میشود. در نتیجه به جای به کار بردن تابع ماکزیمم برای به دست آوردن ارزش حالت بعدی، از شبکه سیاست دیگری به طور همزمان بهره گرفته میشود؛ در نتیجه مقادیر Q بهتر تخمین زده میشوند. شکل زیر ساختار این شبکه را نشان میدهد.
الگوریتم Actor-Critic
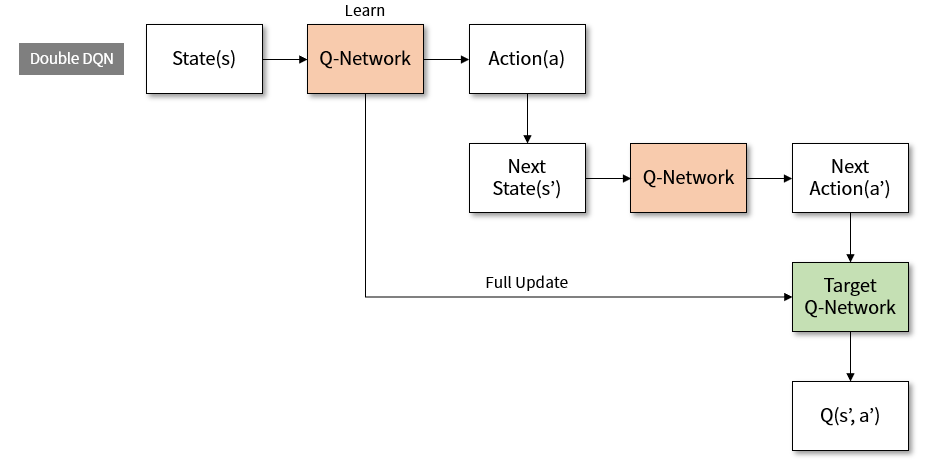
یکی دیگر از الگوریتمهای یادگیری تقویتی عمیق، الگوریتم بازیگر-منتقد (Actor-Critic Algorithm) نام دارد که از دو شبکه برای تصمیمگیری استفاده میکند. شبکه بازیگر، حرکت مرحله بعد را با توجه به حالت فعلی انتخاب میکند و شبکه منتقد، ارزش حالت را محاسبه میکند. شکل زیر دو ساختار نمونه برای این الگوریتم را نشان میدهد.
در این الگوریتم، وظیفه شبکه بازیگر به دست آوردن مقادیر 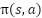 است که این عبارت بیانگر احتمال انجام حرکت در حالت میباشد که اغلب با به کارگیری تابع softmax در لایه آخر شبکه انجام میپذیرد. شبکه منتقد نیز ارزش حالت یا
است که این عبارت بیانگر احتمال انجام حرکت در حالت میباشد که اغلب با به کارگیری تابع softmax در لایه آخر شبکه انجام میپذیرد. شبکه منتقد نیز ارزش حالت یا 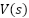 را به دست میآورد که پیش از این درباره آن صحبت شد.
را به دست میآورد که پیش از این درباره آن صحبت شد.
یکی دیگر از تفاوتهای الگوریتم بازیگر-منتقد، نسبت به الگوریتم Q-learning، علاوه بر ساختار دو روش، آن است که الگوریتم بازیگر-منتقد از حافظه بازپخش استفاده نمیکند، و تنها بهرههای به دست آمده در همان مرحله را برای آموزش شبکه به کار میگیرد؛ در نتیجه احتمال به کارگیری دادههای قدیمی در آن کم است.
همچنین الگوریتم بازیگر-منتقد را میتوان به نوعی ترکیب Q-learning و روش گرادیان سیاست (Policy Gradient) دانست. روش گرادیان سیاست یا تقویت (REINFORCE) روشی است که در آن احتمال انتخاب هریک ازحرکات عامل، مستقیما از رفتار او و با جستوجوی فضای سیاست و مشتقگیری از آن یاد گرفته شود. این روش به دلیل انتخاب مستقیم سیاست، اغلب ناپایدار (Unstable) میباشد. هدف در روش بازیگر-منتقد، افزودن پایداری به سیستم با به کارگیری تابع ارزش (در شبکه منتقد) بوده است. روشهایی همچون Advantage Actor-Critic (A2C) وجود دارند که از تابع منفعت (Advantage) به عنوان خروجی شبکه منتقد استفاده میشود.
منابع
- Watkins, C. J., and Dayan, P. (1992). Q-learning. Machine Learning, 8(3-4), 279-292.
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., & Petersen, S. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529-533.
- Hasselt, H. V., Guez, A., and Silver, D. (2016). Deep reinforcement learning with double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (pp. 2094-2100). AAAI Press.
- Lample, G., and Chaplot, D. S. (2017). Playing FPS games with deep reinforcement learning. Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (pp. 2140-2146).
- Duan, Y., Chen, X., Houthooft, R., Schulman, J., and Abbeel, P. (2016). Benchmarking deep reinforcement learning for continuous control. International Conference on Machine Learning, pp.1329-1338.
- Nguyen, T. T., Nguyen, N. D., & Nahavandi, S. (2020). Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE transactions on cybernetics.
- https://redmag.ir/%DB%8C%D8%A7%D8%AF%DA%AF%DB%8C%D8%B1%DB%8C-%D8%AA%D9%82%D9%88%DB%8C%D8%AA%DB%8C-%D8%B9%D9%85%DB%8C%D9%82/
- https://hooshio.com/%DB%8C%D8%A7%D8%AF%DA%AF%DB%8C%D8%B1%DB%8C-%D8%AA%D9%82%D9%88%DB%8C%D8%AA%DB%8C-%DA%86%DB%8C%D8%B3%D8%AA/
نظرات