با xgboost، پادشاه فعلی دنیای یادگیری ماشین آشنا شوید
ترجمه مهدی نورایی از مقاله xgboost

مقدمه
در پستهای قبلی به مدلهای درخت تصمیم و جنگل تصادفی اشاره کردیم. دیدیم که چگونه به کمک مجموعهای از درختهای تصمیم، جنگل تصادفی ساخته میشود و چگونه بهتر از مدل درخت تصمیم عمل میکند. مدل XGBoost در ادامهی همین مسیر تکاملی معرفی میشود و هم از نظر دقت پیشبینی و هم از نظر مدیریت منابع محاسباتی بر مدل جنگل تصادفی برتری دارد. در این پست به معرفی این مدل و طرز کار آن میپردازیم.
XGBoost
XGBoost یک الگوریتم یادگیری ماشینی مبتنی بر درخت تصمیم است که از چارچوب تقویت گرادیان استفاده میکند. در مسائلی که با دادههای بدون ساختار(مانند تصاویر، متن، و غیره) سروکار داریم، شبکههای عصبی مصنوعی معمولاً از همهی الگوریتمهای یادگیری ماشین بهتر عمل میکنند. با این حال، وقتی صحبت از دادههای ساختارمند(جدولی) با حجم کوچک یا متوسط میشود، الگوریتمهای مبتنی بر درخت تصمیم در حال حاضر بهترین راهحلهای موجود محسوب میشوند. لطفا شکل 1 را برای تکامل الگوریتمهای مبتنی بر درخت تصمیم در طول سالهای اخیر ببینید.
شکل 1: تکامل مدلهای مبتنی بر درخت در سالهای اخیر: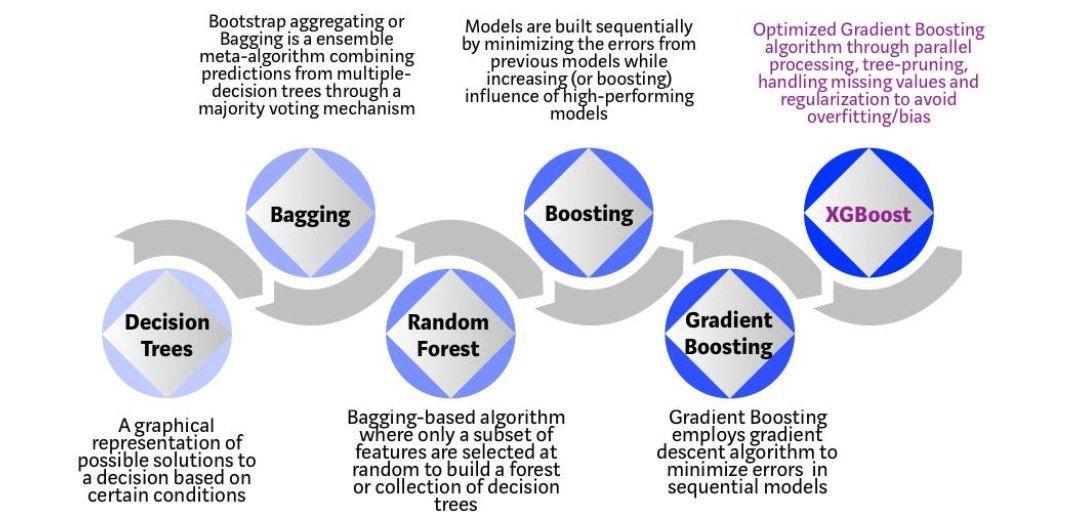
مرحلهی اول: درختهای تصمیم که یک نمایش بصری از راهحل بصری را ارائه میدادند، مرحلهی دوم: رویکرد تجمیعی، مرحلهی سوم: جنگل تصادفی که در هر درخت تصمیم خود، تنها به زیرمجموعهای از متغیرهای مستقل توجه میکرد، مرحلهی چهارم: رویکرد تقویتی، مرحلهی پنجم: رویکرد تقویت گرادیان که به کمک الگوریتم گرادیان کاهشی تلاش میکرد تا خطای مدلهای متوالی را به حداقل برساند، مرحلهی ششم: XGBoost
الگوریتم XGBoost به عنوان یک پروژهی تحقیقاتی در دانشگاه واشنگتن توسعه داده شد. تیانکی چن و کارلوس گسترین مقاله خود را در کنفرانس SIGKDD در سال 2016 ارائه دادند و دنیای یادگیری ماشین را وارد فضایی جدید کردند.
این الگوریتم از زمان معرفی نه تنها با برنده شدن در مسابقات متعدد وبسایت Kaggle شناخته شده است، بلکه به عنوان نیروی محرکهی بسیاری از کاربردهای صنعتی پیشرفته نیز مشهور است.
در نتیجه یک گروه قوی از دانشمندان داده با 350 توسعهدهنده در GitHub با پروژههای منبعباز الگوریتم XGBoost مشارکت میکنند.
برخی مزایای الگوریتم XGBoost
- طیف گستردهای از کاربردها: این الگوریتم میتواند برای حل مسائل رگرسیونی، دستهبندی، رتبهبندی و پیشبینیهای خاص تعریفشده توسط کاربر استفاده شود.
- سازگاری با سیستم عاملهای مختلف: به راحتی در ویندوز، لینوکس و OS X اجرا میشود.
- زبانها: از تمامی زبانهای برنامهنویسی اصلی از جمله C++، Python، R، Java، Scala و Julia پشتیبانی میکند.
- سازگاری با محاسبات ابری: از خوشههای محاسباتی AWS، Azure و Yarn پشتیبانی میکند و با Flink،Spark و سایر اکوسیستمهای محاسباتی دادههای حجیم نیز به خوبی کار میکند.
درک شهودی الگوریتم XGBoost
درختهای تصمیم در شکل سادهی خود الگوریتمهایی با ظاهری آسان و قابل درک و تفسیر هستند؛ اما ایجاد شهود برای نسل جدید الگوریتمهای مبتنی بر درخت تصمیم میتواند تا حدی مشکل باشد. برای درک بهتر نحوهی تکامل الگوریتمهای مبتنی بر درخت تصمیم مقایسهی سادهی زیر را در نظر بگیرید.
تصور کنید که شما مدیر استخدامی یک شرکت هستید که با چند کاندید با شرایط مختلف مصاحبه میکنید.
هر مرحله از تکامل الگوریتمهای مبتنی بر درخت تصمیم را میتوان به عنوان بخشی از این فرآیند مصاحبه مشاهده کرد.
- درخت تصمیم: هر مدیر استخدامی دارای مجموعهای از معیارها مانند سطح تحصیلات، تجربهی کاری، و عملکرد متقاضی در مصاحبه است. درخت تصمیم شبیه به مصاحبهی یک مدیر استخدامی با کاندیدها بر اساس معیارهای خودش است.
- رویکرد تجمیعی: حال تصور کنید که به جای یک مصاحبه کننده، یک تیم مصاحبهکننده وجود دارد که در آن هر مصاحبهکننده یک رای دارد. رویکرد تجمیعی شامل نمونهگیری خودگردانساز شامل ترکیب ورودیهای همهی مصاحبهکنندگان برای اتخاذ تصمیم نهایی از طریق یک فرآیند رأیگیری دموکراتیک است.
- جنگل تصادفی: جنگل تصادفی یک الگوریتم مبتنی بر رویکرد تجمیعی است اما با یک تفاوت کلیدی: در جنگل تصادفی برای هر درخت تصمیم تنها زیرمجموعهای از ویژگیها به طور تصادفی انتخاب می شوند. به عبارت دیگر هر مصاحبهکننده، مصاحبهشونده را فقط بر اساس معیارهای خاصی که بهطور تصادفی انتخاب شدهاند (مثلا مصاحبهی فنی برای آزمودن مهارتهای برنامهنویسی و مصاحبهی منابع انسانی برای ارزیابی مهارتهای غیرفنی) بررسی میکند.
- رویکردی تقویتی: این یک رویکرد جایگزین جنگل تصادفی است که در آن هر مصاحبهکننده معیارهای ارزیابی خود را بر اساس بازخوردهای مصاحبهکنندهی قبلی تغییر میدهد. با این روش کارایی فرایند مصاحبه با به کارگیری یک فرایند ارزیابی پویاتر، افزایش مییابد. رویکرد تقویتی یک تکنیک یادگیری گروهی محبوب در دنیای یادگیری ماشین است. در رویکرد تقویتی چندین مدل یادگیرندهی ضعیف (گاهی از آنها با عنوان مدلهای یادگیرندهی پایهای نیز یاد میشود) را برای ایجاد یک مدل کلی قوی ترکیب میکند. از این رویکرد میتوان برای حل مسائل رگرسیونی و دستهبندی استفاده کرد. الگوریتمهای رویکرد تقویتی به صورت تکراری و متوالی مدلهای یادگیرندهی ضعیف را آموزش میدهند؛ به طوری که هر مدل یادگیرنده بر بهبود کاستیهای مدلهای قبل از خود تمرکز میکند. ایدهی پشت رویکرد تقویتی این است که به نمونههایی که در تکرار قبلی توسط مدل به اشتباه دستهبندی شدهاند، وزنهای بالاتری نسبت داده شود تا مدل در فرایند یادگیری به آنها اهمیت بیشتری بدهد و مدلهای یادگیرندهی ضعیف بعدی در این راستا تنظیم شوند. به این ترتیب مدلهای ضعیف آموزش میبینند تا به نمونههای دشوار توجه بیشتری داشته باشند و به تدریج عملکرد کلی مدل را بهبود ببخشند. یکی از الگوریتمهای تقویتی شناختهشده AdaBoost(تقویت تطبیقی) است که در سال 1996 معرفی شد. AdaBoost به هر نمونه در مجموعه داده یک وزن اختصاص میدهد و در هر تکرار، یک مدل یادگیرندهی ضعیف را روی نمونههای وزندار آموزش میدهد. پس از هر تکرار، وزنهای نمونهها را بر اساس خطای دستهبندی نادرست مدلهای یادگیرندهی ضعیف بهروزرسانی میکند و به نمونههایی که به صورت اشتباه دستهبندی شدهاند، وزن بیشتری اختصاص میدهد و یادگیرندهی بعدی را بر اساس آن تنظیم میکند. مدل نهایی پیشبینیهای همه مدلهای ضعیف را با استفاده از ایدهی رأی اکثریت وزندار ترکیب میکند. یکی دیگر از الگوریتمهای محبوب تقویتی، تقویت گرادیان است که برای اولین بار توسط در سال 1999 ارائه شد. تقویت گرادیان مجموعهای از مدلها را به صورت تکراری و با تمرکز بر خطاهای مدلهای یادگیرندهی قبلی میسازد. این الگوریتم به مدلهای یادگیرندهی ضعیف آموزش میدهد تا شیب تابع خطا را با توجه به پیشبینیهای فعلی تقریب بزنند. هر مدل یادگیرندهی ضعیف برای به حداقل رساندن تابع خطا در جهت شدیدترین کاهش شیب تابع خطا آموزش میبیند. هر دو الگوریتم AdaBoost و Gradient Boosting به دلیل اثربخشی در بهبود عملکرد مدلهای یادگیرندهی ضعیف، به طور گسترده در یادگیری ماشین استفاده میشوند. الگوریتم های تقویتی چندین مزیت دارند. آنها اغلب مدلهای بسیار دقیقی تولید میکنند و تعمیمپذیری خوبی دارند. رویکرد تقویتی می تواند روابط پیچیدهی موجود در دادهها را مدیریت کند و به طور خودکار ویژگیهای مناسب را انتخاب کند. علاوهبراین، الگوریتمهای تقویتی در مقایسه با سایر روشهای روشهای یادگیری گروهی، کمتر مستعد بیشبرازش هستند(به شرطی که تکنیکهای منظمسازی مناسب اعمال شوند). با این حال رویکرد تقویتی میتواند نسبت به دادههای نویزی یا پرت حساس باشد و ممکن است تنظیم دقیق ابرپارامترها در این زمینه نیاز باشد. آموزش مدلهای تقویتی نیز میتواند از نظر محاسباتی گران باشد؛ بهویژه برای مجموعه دادههای بزرگ، زیرا مدلهای یادگیرندهی ضعیف بهطور متوالی آموزش داده میشوند و عملکرد هرکدام به مدلهای قبلی بستگی دارد.
- تقویت گرادیان: یک مورد خاص از رویکرد تقویتی که در آن خطای مدل با الگوریتم گرادیان کاهشی به حداقل می رسد. به عنوان مثال فرض کنید شرکتهای مشاورهی استراتژی با استفاده از مصاحبههای موردی برای از بین بردن نامزدهای کمتر واجد شرایط به مصاحبهکنندگان کمک میکنند.
- XGBoost: الگوریتم XGBoost را میتوانید به عنوان یک رویکرد تقویت گرادیان خیلی قوی و مؤثر در نظر بگیرید. (به همین دلیل به آن "تقویت گرادیان شدید" میگویند). این الگوریتم، ترکیبی مناسب از تکنیکهای بهینهسازی نرمافزاری و سختافزاری را برای به دست آوردن نتایج بهتر با استفاده از منابع محاسباتی کمتر در کوتاهترین زمان ممکن به کار میگیرد.
چرا XGBoost اینقدر خوب عمل میکند؟
XGBoost و Gradient Boosting Machines (GBMs) هر دو روشهای یادگیری جمعی مبتنی بر درخت تصمیم هستند که از اصل تقویت مدلهای یادگیرندهی ضعیف(معمولا درختهایCART) و الگوریتم گرادیان کاهشی استفاده میکنند. با این حال XGBoost چارچوب GBM را از طریق بهینهسازیهای سیستمی و پیشرفتهای الگوریتمی بهبود میبخشد.
در شکل 2 مزایای این الگوریتم نمایش داده شده است: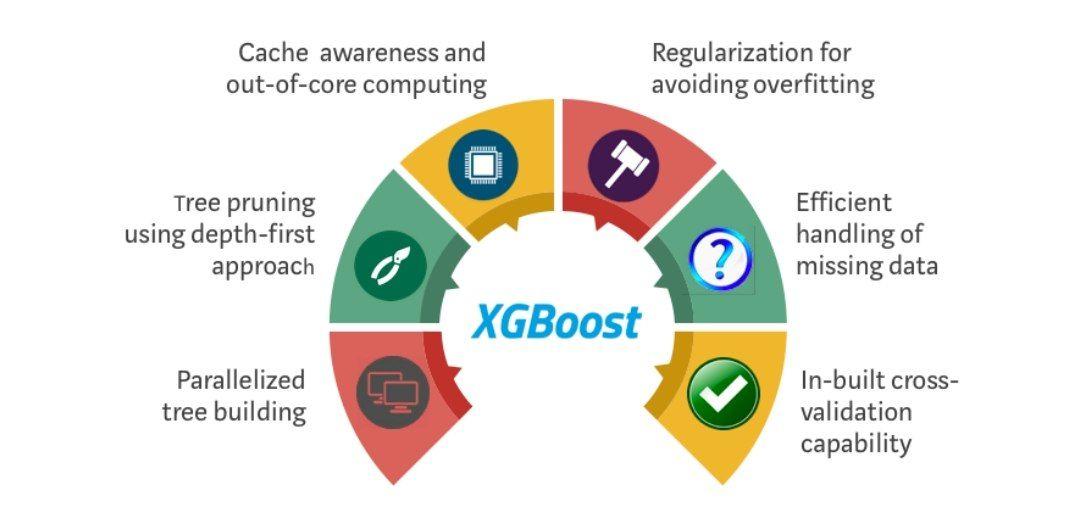
شکل 2: مزایای الگوریتم XGBoost (درختسازی موازی، هرس درخت با رویکرد اول-عمق، مصرف بهینهی منبع محاسباتی، منظمسازی تابع خطا برای جلوگیری از بیشبرازش مدل، مدیریت بهینهی مقادیر گمشده، خدکارسازی فرایند اعتبارسنجی متقابل
در قسمت پایین، 6 موردی را که در شکل 2 نمایش داده شده است را به اختصار بیان خواهیم نمود.
بهینهسازیهای سیستمی XGBoost
- موازیسازی: الگوریتم XGBoost با رویکرد پیادهسازی موازی به فرایند ساخت درختهای متوالی نگاه میکند. این امر به دلیل ماهیت قابل تعویض حلقههای مورد استفاده برای ساخت یادگیرندههای پایه امکانپذیر است. به صورت کلی در جنگل تصادفی حلقهی بیرونی گرههای برگ درخت را محاسبه میکند و حلقهی داخلی دوم ویژگیها را محاسبه میکند. این حلقههای تودرتو موازیسازی را محدود میکنند زیرا بدون تکمیل حلقهی داخلی (که از نظر محاسباتی مهمتر است)، حلقهی خارجی نمیتواند شروع به کار کند. بنابراین، در الگوریتم XGBoost برای بهبود زمان اجرا، ترتیب حلقهها با استفاده از مقداردهی اولیه از طریق اسکن سراسری همهی نمونهها و مرتبسازی با استفاده از رشتههای موازی تعویض میشود. این تغییر رویکرد، عملکرد الگوریتم را با موازیسازی در محاسبات بهبود میبخشد.
- هرس درختها: معیار توقف تقسیم گرههای درختها در چارچوب الگوریتم GBM ماهیت حریصانه دارد و متکی به میزان تابع خطا در نقطهی تقسیم است. XGBoost به جای معیار خطا از ابتدا از پارامتر "max_depth" استفاده و شروع به هرس درختان به صورت عقبگرد میکند. این رویکرد عملکرد محاسباتی الگوریتم را به طور قابل توجهی بهبود میبخشد.
- بهینهسازی سختافزاری: این الگوریتم برای استفادهی بهینه از منابع سختافزاری طراحی شده است. این امر با استفاده از یک حافظهی پنهان و ذخیرهی آمار گرادیان در هر رشتهی محاسباتی انجام میشود. پیشرفتهای بیشتر مانند محاسبات «خارج از هسته»، فضای موجود دیسک را بهینه و در عین حال دادههای بزرگ که در حافظه جا نمیشوند را مدیریت میکند.
پیشرفتهای الگوریتمی XGBoost
- منظمسازی: مدلهای درختی پیچیدهتر را از طریق عبارات منظمساز لاسو و ریج جریمه میکند تا از بیشبرازش مدل جلوگیری شود. در رابطه با این عبارات منظمساز در پست مربوط به رگرسیون لاسو و ریج به صورت مفصل صحبت کردهایم.
- آگاهی از پراکندگی دادهها: XGBoost به طور خودکار ویژگیهای پراکنده(ویژگیهایی که بیشتر نمونهها در آن مقدار یکسانی دارند) و مقادیر گمشده را به عنوان ورودی میپذیرد و طی فرایند یادگیری، به خوبی روی آنها آموزش میپذیرد. این الگوریتم همچنین به خوبی از عهدهی دادههای گمشده برمیآید و انواع مختلف الگوهای پراکندگی و گمشدگی در مجموعه داده را به طور کارآمدی مدیریت میکند.
- طرح چندک وزنی: XGBoostاز الگوریتم طرح چندک وزنی توزیعشده برای یافتن نقاط تقسیم بهینه در مجموعه داده استفاده میکند. این کار سرعت و عملکرد الگوریتم را بسیار بالا میبرد. طرح چندک وزنی یک الگوریتم است که به شما امکان میدهد چندکهای یک مجموعه داده را به طور موثر و دقیقی تخمین بزنید. این الگوریتم به ویژه در هنگام کار کردن با مجموعه دادههای بزرگ یا جریانهای آنلاین داده که در آن امکان ذخیرهی کل مجموعه داده وجود ندارد، بسیار مفید است. برای درک الگوریتم طرح چندک وزنی، بیایید با مرور مفهوم چندک شروع کنیم. چندک، مقداری را نشان میدهد که نسبت خاصی از نمونههای موجود در مجموعه داده مقادیر کمتر از آن را اختیار کردهاند. به عنوان مثال، میانه مقداری است که 50٪ از دادهها زیر آن قرار می گیرند. چندکها اغلب برای خلاصهسازی مجموعه دادهها و به دست آوردن بینش کلی در مورد توزیع احتمال حاکم بر آنها استفاده میشوند. رویکرد کلاسیک برای تخمین چندکها مرتبسازی مجموعه داده و سپس استفاده از فرمول مناسب برای محاسبهی کمیت مورد نظر است. با این حال، مرتبسازی کل مجموعه داده میتواند از نظر زمان و حافظه گران باشد؛ بهویژه زمانی که با مجموعه دادههای بزرگ سروکار داریم. الگوریتم طرح چندک وزنی یک روش جایگزین کارآمد برای تخمین چندکها ارائه میدهد. این الگوریتم به شما این امکان را میدهد که مجموعه داده یا جریان آنلاین داده را طوری پردازش کنید که در زمان اجرا و حافظهی مصرفی نیز در وضعیت مطلوبی قرار داشته باشید. این الگوریتم مجموعهای از تنها نمونههایی از مجموعه داده که نمایندهی توزیع احتمال کل مجموعه داده هستند را نگه میدارد. هر نمونه شامل یک مقدار و وزن مربوط به آن است. نمونههای نماینده با ورود دادههای جدید بهروزرسانی میشوند و الگوریتم تضمین میکند که نمونهها با توجه به وزنشان به صورت تصادفی انتخاب میشوند. تعداد نمونههای نماینده دقت تخمین را تعیین میکند. تعداد نمونههای نمایندهی بیشتر معمولاً به تخمینهای دقیقتری منجر میشود؛ اما این کار به حافظهی بیشتری نیاز دارد. تعداد نمایندهها معمولا بر اساس موازنهی بین دقت مورد نظر و حافظهی در دسترس انتخاب میشود. هنگامی که می خواهید یک کمیت را به کمک این الگوریتم تخمین بزنید، مقدار کمیت مورد نظر را ارائه میکنید (مثلاً 0.5 برای میانه) و الگوریتم مقدار تخمینی آن را برمیگرداند که انتظار میرود نزدیک به کمیت واقعی در مجموعه دادهی اصلی باشد. این الگوریتمها از نظر میزان استفاده از حافظه، دقت و سرعت، گزینههای متنوعی را ارائه میدهد. شما میتوانید گزینهای را انتخاب کنید که به بهترین وجه با نیازهای شما مطابقت دارد. به طور کلی، الگوریتم طرح چندک وزنی یک تکنیک قدرتمند برای تخمین چندک در مجموعه دادههای بزرگ، بدون نیاز به ذخیره یا مرتبسازی کل مجموعه داده است. این الگوریتم به طور گستردهای در زمینههای مختلف از جمله آمار، تجزیه و تحلیل دادهها و پردازش دادههای آنلاین استفاده میشود.
- اعتبارسنجی متقابل: الگوریتم XGBoost با روش اعتبارسنجی متقابل که در داخل آن تعبیه شده است در هر تکرار اجرا میشود. این موضوع نیاز به برنامهنویسی صریح جداگانه برای جستجو و تعیین تعداد دقیق تکرارهای تقویت گرادیان مورد نیاز را از بین میبرد.
مقایسهی XGBoost با الگوریتمهای دیگر
ما از تابع Make Classification موجود در کتابخانهی Scikit-learn برای ایجاد یک مجموعه دادهی تصادفی با 1 میلیون سطر و 20 ویژگی استفاده کردیم. چندین الگوریتم مانند رگرسیون لجستیک، جنگل تصادفی، تقویت گرادیان و XGBoost را روی این مجموعه داده بررسی کردیم. نتیجهی این آزمایش در شکل 3 نمایش داده شده است.
همانطور که در شکل 3 نشان داده شده است، مدل XGBoost بهترین عملکرد را در پیشبینی و زمان مورد نیاز آموزش در مقایسه با سایر الگوریتمها دارد. آزمایشهای دیگری را نیز برای محک زدن این الگوریتم اجرا کردیم و به نتایج مشابهی رسیدیم. جای تعجب نیست که XGBoost به طور گسترده در رقابتهای اخیر علم داده استفاده میشود.
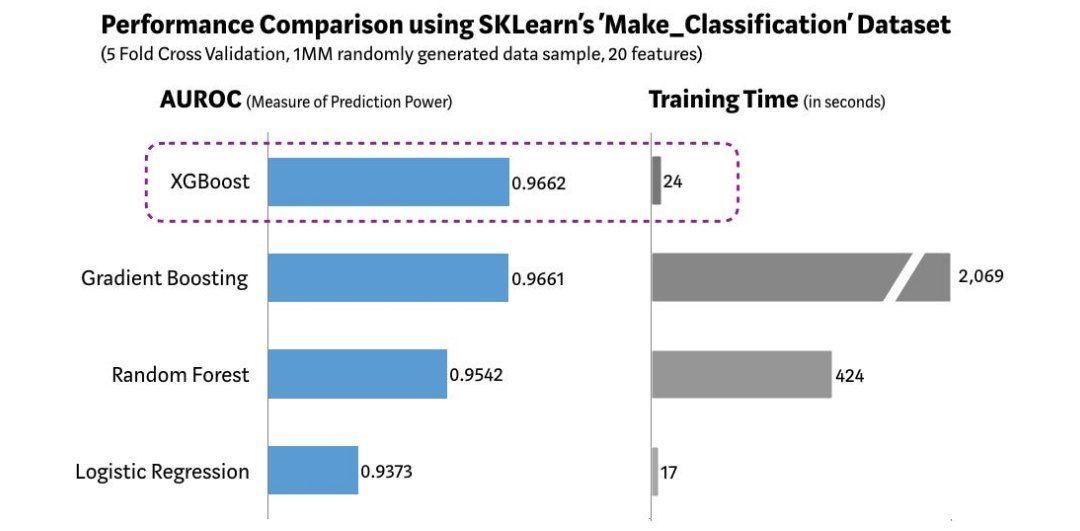
شکل 3: مقایسهی الگوریتم XGBoost با الگوریتمهای دیگر
پس آیا باید همیشه از XGBoost استفاده کنیم؟
وقتی صحبت از یادگیری ماشین (یا حتی خود زندگی) میشود، هیچ راهحل همواره مناسبی برای مسائل وجود ندارد و راهحل را باید در خود مساله جستجو کنیم. به عنوان یک دانشمند داده، ما باید تمام الگوریتمهای ممکن را بر روی دادههای موجود آزمایش کنیم تا الگوریتم مناسب را شناسایی کنیم.
علاوهبراین، انتخاب الگوریتم مناسب کافی نیست. ما همچنین باید پیکربندی و تنظیمات صحیح الگوریتم را برای مجموعه دادهمان با تنظیم ابرپارامترهای مدل انتخاب کنیم. همچنین، چندین ملاحظهی دیگر نیز برای انتخاب الگوریتم مناسب مانند حجم پیچیدگی محاسباتی، توضیحپذیری و سهولت پیادهسازی وجود دارد. اینجا دقیقا همان نقطهای است که یادگیری ماشین شروع میکند به دور شدن از علم و نزدیک شدن به هنر! اما صادقانه بگوییم، گاهی در یادگیری ماشین چیزی مشابه جادو اتفاق می افتد!
در آینده چه چیزی در انتظار ماست؟
یادگیری ماشین یک حوزه تحقیقاتی بسیار فعال است و در حال حاضر چند جایگزین برای XGBoost معرفی شده است. تیم تحقیقاتی مایکروسافت اخیرا مدل LightGBM را برای تقویت گرادیان منتشر کرده است که پتانسیل بالایی را از خود نشان داده است.
مدلCatBoost که توسط فناوری Yandex توسعه یافته است نیز نتایج قابل توجهی را ارائه کرده است. هر زمان که مدلی معرفی شود که از نظر عملکرد در پیشبینی، انعطافپذیری، توضیحپذیری و سهولت استفاده، از XGBoost بهتر عمل کند، میتوانیم آن مدل را به عنوان جایگزین مناسب XGBoost معرفی کنیم؛ اما تا زمانی که یک رقیب قدرتمند از راه برسد، XGBoost بر دنیای یادگیری ماشینی سلطنت خواهد کرد.
مثال عملی
در این بخش میخواهیم نحوهی استفاده از الگوریتم XGBoost را در یک مثال عملی در محیط پایتون ببینیم. برای این مثال از مجموعه دادهی گلهای زنبق استفاده میکنیم. از آنجا که این مجموعه داده را در پستهای قبلی معرفی کردهایم، از معرفی دوبارهی آن در مجموعه داده در این پست صرف نظر میکنیم.
میخواهیم نژاد گل زنبق را براساس ویژگیهای گلها تشخیص دهیم. مجموعه داده شامل 150 نمونه از 3 نژاد از گلهای زنبق است.
ابتدا مجموعه داده را در محیط پایتون فراخوانی میکنیم و متغیرهای مستقل را از متغیر پاسخ جدا میکنیم:

شکل 4: فراخوانی مجموعه داده و مشخص کردن متغیرهای مستقل و هدف
حالا مجموعه دادهی آموزشی و آزمونی را با نسبت 80 به 20 به صورت تصادفی تشکیل میدهیم:
شکل 5: مشخص کردن مجموعه دادههای آموزشی و آزمونی
برای استفاده از الگوریتم XGBoost لازم است که ابتدا کتابخانهی xgboost را نصب کنیم:

شکل 6: نصب کتابخانهی xgboost
حالا الگوریتم را بر روی مجموعه دادهی آموزشی، آموزش میدهیم. ما از مقادیر پیشفرض برای ابرپارامترها استفاده کردیم. شما میتوانید در صورت تمایل مقادیر آنها را تغییر دهید.
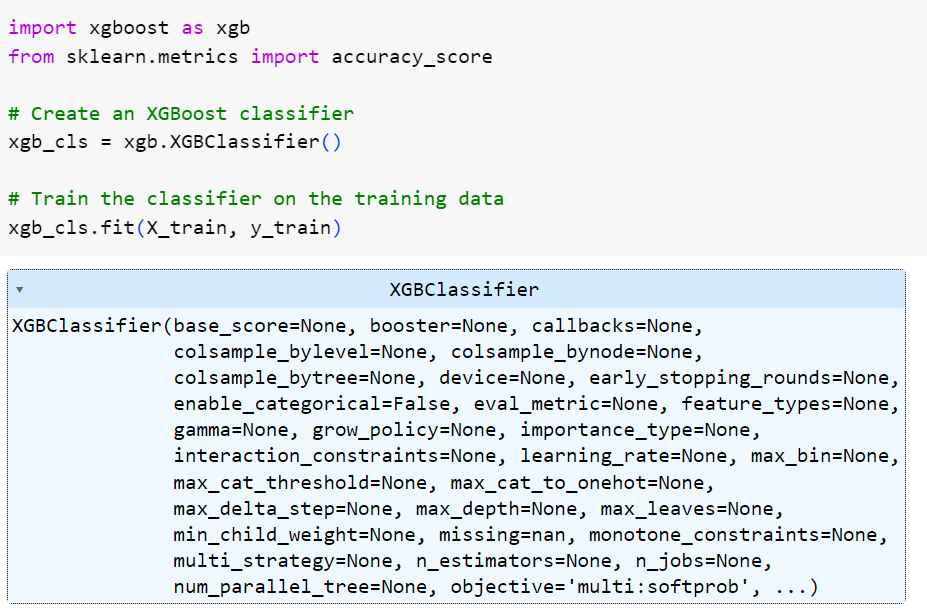
شکل 7: آموزش مدل XGBoost
حالا دقت مدل روی مجموعه دادهی آموزشی و آزمونی را محاسبه میکنیم تا بتوانیم دربارهی عملکرد مدل قضاوت کنیم:
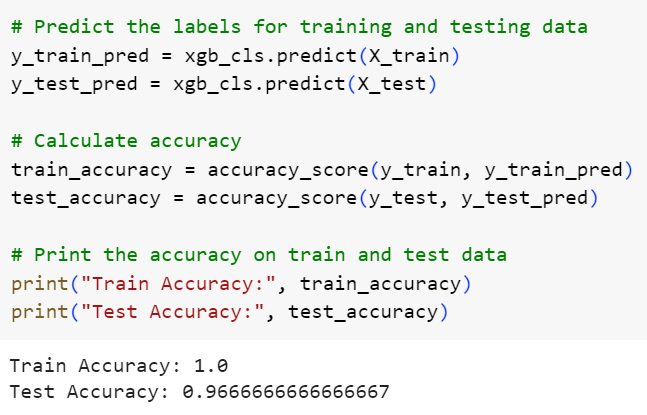
شکل 8: گزارش عملکرد مدل
همانطور که مشاهده میکنید دقت الگوریتم روی مجموعه دادهی آموزشی و آزمونی به ترتیب برابر ۱۰۰٪ و ۹۶.۶۶٪ است که کاملا مطلوب است.
امیدواریم این پست برایتان مفید بوده باشد و از آن لذت برده باشید.
منبع

نظرات