الگوریتم adaboost: تقویت عملکرد مدلها
ترجمه مهدی نورایی از مقاله adaboost

مقدمه
امروزه یادگیری ماشین نمایندۀ نوآوریهای بزرگ است و شرکتها را قادر میسازد تا بهترین تصمیمها را از طریق پیشبینیهای دقیق مدلهای یادگیری ماشین اتخاذ کنند. اما چه اتفاقی میافتد اگر خطای این الگوریتمها بالا و غیرقابل اغماض باشد؟ این نقطه همان جایی است که الگوریتمهای یادگیری گروهی[1] متولد میشوند.
الگوریتم توانافزایی تطبیقی یا AdaBoost [2] یک روش یادگیری گروهی است که در ابتدا برای افزایش کارایی مدلهای دستهبندیکنندۀ دودویی ایجاد شد. AdaBoost از یک رویکرد تکرارمحور برای درس گرفتن از اشتباهات دستهبندیکنندههای ضعیف و تبدیل آنها به مدلهای دستهبندیکنندۀ قوی استفاده میکند. مقالات «درخت تصمیم»[3] و «جنگل تصادفی» پیشنیاز مطالعۀ این مقاله هستند.
منظور از یادگیری گروهی چیست؟
یادگیری گروهی چندین الگوریتم پایه را برای تشکیل یک الگوریتم پیشبینیکنندۀ بهینه با هم ترکیب میکند. گاهی عملکرد یک مدل بهتنهایی برای حل مسئله با دقت بالا کافی نیست. برای مثال مدل درخت تصمیم برای دستهبندی، ویژگیهای مختلف را در نظر میگیرد و آنها را به سؤالاتی قاعدهمحور تبدیل میکند. سپس برای تصمیمگیری به مقدار یک ویژگی در نمونه توجه میکند و اگر ابهامی باشد، به سراغ ویژگی دیگری میرود.
خروجی درخت تصمیم میتواند در بعضی حالات مبهم باشد. برای مثال اگر عواملی از قبیل تعدد قوانین تصمیمگیری، نامشخص بودن آستانۀ تصمیمگیری مناسب برای ویژگیها یا پر شاخ و برگ بودن درخت در کار باشد، ممکن است تفسیر درخت تصمیم آسان نباشد و مدل به دقت مطلوب مورد نظر تحلیلگر نرسد.
اینجا جایی است که یادگیری گروهی معرفی میشود. روشهای یادگیری گروهی به جای انتظار عملکرد عالی از یک درخت تصمیم، چندین درخت تصمیم مختلف را آموزش داده و خروجی آنها را در یک پیشبینی نهایی و قوی تجمیع میکنند.
انواع روشهای یادگیری گروهی
روشهای یادگیری گروهی را میتوان به دلایل مختلفی به کار گرفت؛ این روشها عمدتاً برای:
- کاهش واریانس (رویکرد تجمیعی[4])
- کاهش سوگیری[5] (رویکرد تقویتی[6])
- بهبود پیشبینی (رویکرد انباشتهسازی[7]) استفاده میشوند.
روشهای یادگیری گروهی را از منظری دیگر نیز میتوان به دو گروه تقسیم کرد:
- مدلهای یادگیرندۀ متوالی:[8] که در آن، مدلهای مختلف بهصورت متوالی تولید میشوند و تلاش میکنند تا اشتباهها و نقاط ضعف مدلهای قبلی را پوشش دهند. هدف از این کار، ایجاد وابستگی بین مدلها با دادن وزنهای بالاتر به نمونههایی است که بهصورت اشتباه دستهبندی شدهاند (مانندAdaBoost ).
- یادگیری موازی: که در آن مدلهای پایه بهصورت موازی تولید میشوند. این رویکرد از استقلال بین مدلها استفاده میکند و بین خروجی مدلهای مختلف رأیگیری میکند (مانند جنگل تصادفی).
رویکرد تقویتی در روشهای یادگیری گروهی
درست همانطور که انسانها از اشتباههای خود درس میگیرند و سعی میکنند که آنها را در زندگی خود تکرار نکنند، رویکرد تقویتی نیز سعی میکند تا با در نظر گرفتن اشتباههای چندین مدل ضعیفتر، یک مدل یادگیرندۀ قوی بسازد.
ابتدا با برازش[9] اولین مدل روی دادههای آموزشی شروع میکنیم. سپس مدل دوم را با تلاش برای کاهش خطاهای مدل قبلی آموزش میدهیم. مدلها بهصورت متوالی اضافه میشوند و هر کدام مدل قبلی خود را تصحیح میکنند، تا زمانی که دادههای آموزشی بهطور کامل بهدرستی پیشبینی شوند یا به حداکثر تعداد مدل برسیم.
اساساً رویکرد تقویتی تلاش میکند تا سوگیری مدل را کاهش دهد. سوگیری مدل زمانی ایجاد میشود که مدل، قادر به شناسایی روندها و الگوهای موجود در داده نیست. سوگیری با ارزیابی اختلاف بین مقدار پیشبینیشده و مقدار واقعی محاسبه میشود.
انواع رویکردهای تقویتی:
- AdaBoost (تقویت تطبیقی)
- تقویت گرادیان
- XGBoost
در این پست بر روی جزئیات مدلAdaBoost ، که احتمالاً محبوبترین روش مبتنیبر رویکرد تقویتی است، تمرکز خواهیم کرد.
زیر و بم AdaBoost
الگوریتمAdaBoost (توانافزایی تطبیقی) یک تکنیک تقویتی بسیار محبوب است که هدف آن ترکیب چند دستهبندیکنندۀ ضعیف به هدف ساخت یک دستهبندیکنندۀ قوی است.
در بسیاری از مسائل ممکن است یک مدل دستهبندیکننده نتواند دستۀ یک شیء را بهطور دقیق پیشبینی کند؛ اما وقتی چندین مدل دستهبندیکنندۀ ضعیف را کنار هم قرار میدهیم که هر کدام به تدریج از عملکرد مدلهای قبلی یاد میگیرند، میتوانیم مدل قویای را بسازیم. دستهبندیکنندهای که در اینجا ذکر شد میتواند هر یک از دستهبندیکنندههای شناختهشده باشد، از درختهای تصمیم (که اغلب بهصورت پیشفرض استفاده میشود) گرفته تا رگرسیون لجستیک و غیره.
ممکن است بپرسید منظور از دستهبندیکنندۀ «ضعیف» چیست؟ یک دستهبندیکنندۀ ضعیف مدلی است که عملکرد بهتری نسبت به حدس زدن کاملاً تصادفی دارد، اما همچنان در تعیین دستۀ نمونهها ضعیف عمل میکند. بهعنوان مثال، یک دستهبندیکنندۀ ضعیف ممکن است پیشبینی کند که ممکن نیست هیچ یک از افراد بالای 40 سال در دوی ماراتن موفق شوند، اما افرادی که زیر آن سن قرار دارند میتوانند. ممکن است دقت این مدل بالای 60% باشد، اما همچنان بسیاری از نمونههای داده را به اشتباه دستهبندی میکند.
مدلAdaBoost به جای اینکه به خودی خود یک مدل باشد، میتواند روی هر مدل دستهبندیکنندهای اعمال شود تا از کاستیهای آن درس بگیرد و مدل دقیقتری را ارائه دهد.
بیایید درک کنیم که الگوریتمAdaBoost چگونه با کُندههای تصمیم[10] کار میکند. کندههای تصمیم مانند درختهای جنگل تصادفی هستند، اما با این تفاوت که کاملاً رشدیافته نیستند. آنها تنها یک گره و دو برگ دارند. الگوریتمAdaBoost از جنگلی از این گونه کندهها به جای درختان استفاده میکند.
کندهها بهتنهایی راهحل خوبی برای تصمیمگیری نیستند. یک درخت تصمیم کامل همۀ متغیرها را برای پیشبینی مقدار متغیر هدف در نظر میگیرد، اما یک کنده تنها میتواند از یک متغیر برای تصمیمگیری استفاده کند. بیایید با یک مثال سعی کنیم پشتصحنۀ الگوریتمAdaBoost را گامبهگام و با نگاه کردن به چند متغیر درک کنیم و به کمک مدل مشخص کنیم که آیا یک فرد «تناسب اندام» دارد یا خیر.
یک مثال از نحوۀ عملکرد الگوریتم AdaBoost
مرحلۀ اول: یک دستهبندیکنندۀ ضعیف (مثلاً یک کندۀ تصمیم) را روی دادههای آموزشی و بر اساس نمونههای وزندار آموزش میدهیم. وزن هر نمونه نشان می دهد که دستهبندی صحیح آن نمونه چقدر اهمیت دارد. در ابتدا برای کندۀ اول به همۀ نمونهها وزن مساوی میدهیم.
مرحلۀ دوم: برای هر متغیر، یک کندۀ تصمیم ایجاد میکنیم و بررسی میکنیم که هر کندۀ تصمیم چقدر در دستهبندی صحیح نمونهها به دستههای هدف موفق عمل میکند. بهعنوان مثال در نمودار زیر سن، وضعیت خوردن غذای ناسالم و ورزش کردن نمونهها را بررسی میکنیم. سپس بررسی میکنیم که در هر کنده چند نمونه به درستی یا نادرستی بهعنوان نمونههای «سالم» یا «ناسالم» دستهبندی شدهاند.
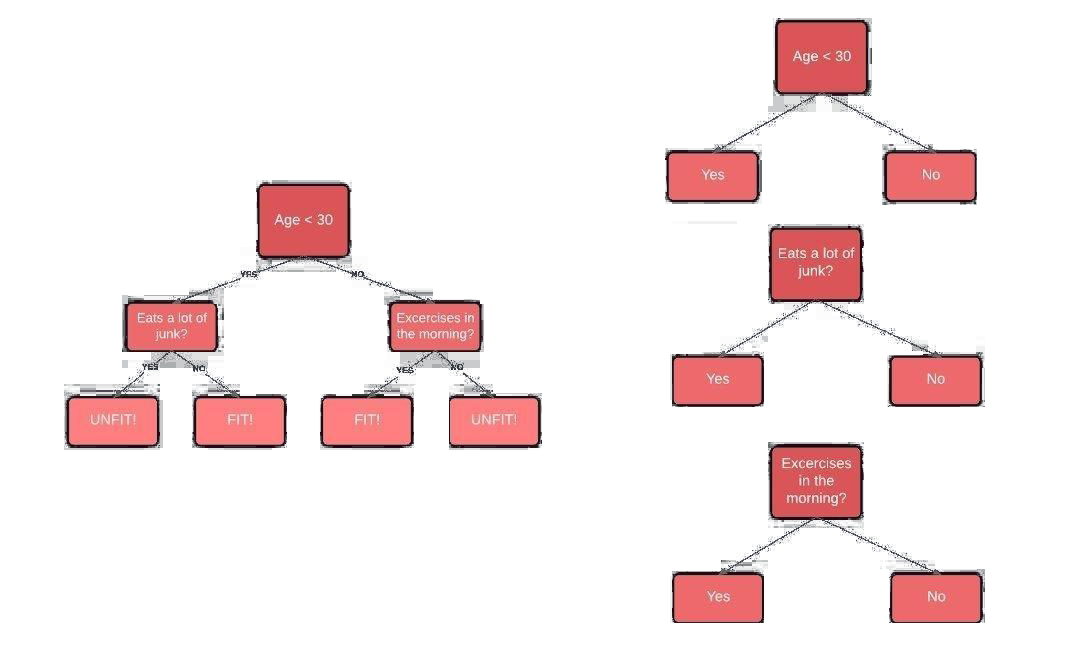
شکل 1: درخت تصمیم در سمت چپ و کندههای تصمیم در سمت راست
شکل 2: اتصال کندههای تصمیم به ترتیب اهمیتشان در فرایند تصمیمگیری
مرحلۀ سوم: به نمونههایی که اشتباه دستهبندیشدهاند وزنهای بزرگتری اختصاص داده میشود تا در کندۀ تصمیم بعدی به درستی دستهبندی شوند. به مدلها نیز بر اساس دقت دستهبندیشان وزنهایی اختصاص مییابد که به معنای این است که دقت مدل با مقدار وزن مدل رابطۀ عکس دارد.
مرحله چهارم: مرحلۀ دوم را تا زمانی که تمام نمونههای داده به درستی دستهبندی شوند، یا به حداکثر سطح تکرار مورد نظر رسیده باشید، تکرار کنید.
توجه: برخی از کندههای تصمیم در دستهبندی بهتر از سایر کندهها عمل میکنند.
مبانی ریاضیاتی AdaBoost
میخواهیم الگوریتمAdaBoost را گامبهگام تجزیه کنیم تا درک آن آسانتر شود.
بیایید با در نظر گرفتن یک مجموعهداده باN نمونه یا ردیف در مجموعهداده شروع کنیم:
تعداد ویژگیهای مجموعهداده را با n نشان میدهیم. x مجموعهای از نمونههای مجموعهداده است و y متغیر هدف است که مقدار 1- یا 1+ را میگیرد، زیرا با یک مسئلۀ دستهبندی دودویی طرف هستیم که 1- و 1+ دستههای اول و دوم را نشان میدهند (مثلاً سالم و ناسالم).
حالا وزن نمونهها را در مجموعهداده محاسبه میکنیم. الگوریتمAdaBoost به هر نمونۀ آموزشی یک وزن اختصاص میدهد که اهمیت آن نمونه را در مجموعهدادۀ آموزشی تعیین میکند. زمانی که وزن اختصاصدادهشده به نمونۀ آموزشی بزرگ باشد، آن نمونه از داده احتمالاً در مجموعۀ آموزشی اهمیت خیلی بیشتری دارد. بهطور مشابه، زمانی که وزن تخصیصیافته به یک نمونه کوچک باشد، تأثیر کمی در فرایند آموزش دارد.
در ابتدا همۀ نمونههای داده دارای وزن یکسانی دارند:
که در آنN تعداد کل نمونههای مجموعهداده است.
جمع وزن نمونهها همیشه برابر با 1 میشود؛ بنابراین مقدار وزن هر نمونه همواره بین 0 و 1 خواهد بود. سپس تأثیر هر مدل دستهبندیکننده را در دستهبندی نقاط داده با استفاده از فرمول (3) محاسبه میکنیم:
آلفا میزان تأثیر کنده در دستهبندی نهایی است. خطای کل چیزی نیست جز تعداد کل دستهبندیهای اشتباه روی مجموعۀ آموزشی تقسیم بر اندازۀ مجموعۀ آموزشی. میتوانیم با وصل کردن مقادیر مختلف خطای کل از 0 تا 1، نمودار آلفا در برابر خطا را بهصورت زیر رسم کنیم.
شکل 3: نمودار آلفا در برابر خطا
توجه داشته باشید که وقتی یک کندۀ تصمیم بهخوبی عمل میکند، یعنی فاقد دستهبندی اشتباه است، منجر به خطای 0 و مقدار آلفای نسبتاً بزرگ و مثبت میشود (کندۀ تصمیم اهمیت بالایی پیدا میکند). اگر کندۀ تصمیم فقط نیمی از نمونهها را به درستی و نیمی را اشتباه دستهبندی کند، مدل خطای 50% خواهد داشت که بهتر از حدس زدن تصادفی نیست. در این صورت مقدار آلفا برابر با 0 خواهد بود.
زمانی که کندۀ تصمیم تمام نمونهها را اشتباه دستهبندی کند؛ یعنی کندۀ تصمیم به هر نمونه دقیقاً برعکس دستۀ واقعیاش را نظیر کند، آنگاه آلفا یک مقدار منفی بزرگ خواهد بود (یعنی اهمیت کندۀ تصمیم در فرایند تصمیمگیری بسیار پایین خواهد بود).
پس از محاسبۀ مقادیر خطای هر کندۀ تصمیم، وقت آن است که وزنهای مربوط به نمونهها را، که در ابتدا
برای هر نمونه برابر ![]() در نظر گرفته شده بود، بهروزرسانی کنیم. این کار را با استفاده از
فرمول زیر انجام میدهیم:
در نظر گرفته شده بود، بهروزرسانی کنیم. این کار را با استفاده از
فرمول زیر انجام میدهیم:
به عبارت دیگر، وزن جدید نمونهها برابر با وزن نمونه قدیمی ضرب در عدد اویلر به توان آلفای مثبت یا منفیای خواهد بود که در مرحلۀ قبل محاسبه کردیم.
آلفا (مثبت یا منفی) نشان میدهد که:
آلفا زمانی مثبت است که مقدار پیشبینیشده و مقدار واقعی مطابقت داشته باشند؛ یعنی نمونه به درستی دستهبندی شده باشد. در این مورد، وزن نمونه را نسبت به قبل کاهش میدهیم، زیرا کندۀ تصمیم بر روی این نمونه عملکرد خوبی دارد.
آلفا زمانی منفی است که مقدار پیشبینیشده با مقدار واقعی مطابقت نداشته باشد؛ یعنی نمونه به اشتباه دستهبندی شده باشد. در این حالت باید وزن نمونه را افزایش دهیم تا از تکرار این دستهبندی اشتباه در کندۀ تصمیم بعدی جلوگیری کنیم. به این ترتیب کندههای تصمیم به کندههای پیش از خود وابسته میشوند.
شبهکد الگوریتم AdaBoost
در تصویر زیر شبه کد الگوریتم AdaBoost رو مشاهده میکنید.
Initially set uniform example weights.
For Each base learner do:
Train base learner with a weighted sample.
Test base learner on all data.
Set learner weight with a weighted error.
Set example weights based on ensemble predictions.
End for
شکل 4 : شبه کد AdaBoost
پیادهسازی الگوریتمAdaBoost در محیط پایتون
مرحلۀ اول: فراخوانی کتابخانهها
اولین قدم در ساخت مدل، فراخوانی بستهها و کتابخانههای مورد نیاز است.
در محیط پایتون دستههایAdaBoostClassifier
وAdaBoostRegressor در کتابخانۀ
scikit-learn تعبیه شدهاند. برای این مثال،
AdaBoostClassifier را فراخوانی میکنیم؛ زیرا مثال ما یک مسئلۀ دستهبندی
است. متد train_test_split برای تقسیم مجموعهداده به مجموعههای
آموزشی و آزمونی استفاده میشود. مجموعهدادهIris که در مورد گلهای
زنبق است و در پستهای قبلی با آن آشنا شدیم را نیز فراخوانی میکنیم.
شکل 4: فراخوانی کتابخانهها
مرحلۀ دوم: آمادهسازی مجموعهداده
مجموعهداده را با بارگیری از بستۀ مجموعهدادهها با استفاده از متد load_iris () فراخوانی میکنیم.
علاوهبراین مجموعهداده خود را به متغیرهای مستقل (X) که شامل ویژگیهای طول
کاسبرگ، عرض کاسبرگ، طول گلبرگ و عرض گلبرگ است و متغیر هدف (y) که نوع گل زنبق است،
تقسیم میکنیم. 
شکل 5: آمادهسازی داده
مرحلۀ سوم: تقسیم دادهها
تقسیم مجموعهداده به مجموعههای آموزشی و آزمونی ایدۀ خوبی است تا ببینیم آیا مدل نمونههای دیدهنشده و جدید را به درستی دستهبندی میکند یا خیر.

شکل 6: تقسیم دادهها به مجموعههای آموزشی و آزمونی
در این مثال مجموعهداده را به 70% آموزشی و 30% آزمونی تقسیم میکنیم که یک رویکرد رایج است.
مرحلۀ چهارم: برازش مدل
الگوریتمAdaBoost بهطور پیشفرض درخت تصمیم را بهعنوان مدل یادگیرندۀ خود انتخاب میکند. یک شیAdaBoostClassifier میسازیم و نام آن را abc میگذاریم. چند پارامتر مهم AdaBoost عبارتاند از:
:base_estimator یادگیرنده ضعیفی است که برای آموزش مدل استفاده میشود.
N_Estimators: تعداد مدلهای یادگیرندۀ ضعیف که برای آموزش در هر تکرار به کار گرفته میشوند.
Learning_rate: پارامتر نرخ یادگیری به فرایند بهروزرسانی وزن مدلهای یادگیرندۀ ضعیف کمک میکند. مقدار آن را برابر 1 قرار میدهیم.

شکل 7: فراخوانی و تنظیم پارامترهای مدل
سپس مدل را روی مجموعهدادۀ آموزشی آموزش میدهیم.
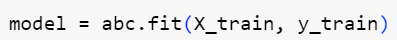
شکل 8: آموزش مدل
مرحلۀ پنجم: انجام پیشبینی
قدم بعدی ما این است که ببینیم مدل آموزشدادهشده چقدر در انجام پیشبینی روی نمونههای جدید خوب عمل میکند. از متدpredict() برای پیشبینی دستهای که نمونه به آن تعلق دارد استفاده میکنیم.

شکل 9: انجام پیشبینی به وسیلۀ مدل
مرحله ششم: ارزیابی مدل
دقت مدل به ما میگوید که مدل چند درصد اوقات دستۀ نمونهها را بهصورت صحیح پیشبینی میکند.

شکل 10: دقت مدل روی دادههای آزمونی
دقت 91.11٪ را دریافت میکنیم که بسیار خوب است. شما میتوانید با مدلهای یادگیرندۀ پایۀ دیگر مانند ماشین بردار پشتیبان[11] و رگرسیون لجستیک[12] که ممکن است دقت بالاتری به شما بدهند را نیز آزمایش کنید.
مزایا و معایب الگوریتم AdaBoost
مزایا:
الگوریتمAdaBoost مزایای زیادی دارد؛ از جمله اینکهAdaBoost در مقایسه با الگوریتمهایی مانند ماشین بردار پشتیبان، نیاز کمتری به تنظیم مقدار پارامترها دارد. همچنینAdaBoost قابلیت ترکیب با مدلهای دیگر مثلا ماشین بردار پشتیبان بهعنوان یادگیرندۀ پایه را دارد. از نظر تئوری، الگوریتمAdaBoost مستعد بیشبرازش[13] نیست. ممکن است دلیلش این باشد که پارامترها بهطور مشترک و همزمان بهینه نمیشوند بلکه تنظیم و تخمین آنها بهصورت مرحله به مرحله انجام میشود. این موضوع باعث کند شدن روند یادگیری میشود اما تا حد خوبی از بیشبرازش مدل پیشگیری میکند.
الگوریتمAdaBoost میتواند برای بهبود دقت دستهبندیکنندههای ضعیف شما استفاده شود و از این رو این الگوریتم انعطافپذیری خوبی دارد.
امروزه این الگوریتم فراتر از مسائل دستهبندیکنندۀ دودویی رفته و به دستهبندی متون و تصاویر نیز گسترش یافته است.
معایب:
رویکرد تقویتی بهصورت تدریجی یاد میگیرد؛ بنابراین مهم است که اطمینان حاصل کنید که مجموعه دادۀ آموزشی با کیفیتی در اختیار دارید. الگوریتمAdaBoost همچنین به دادههای نویزی و پرت بسیار حساس است. بنابراین اگر قصد دارید از الگوریتمAdaBoost استفاده کنید، بهشدت توصیه میشود که دادههای پرت مجموعهداده را کنار بگذارید.
همچنین ثابت شدهاست که الگوریتمAdaBoost از الگوریتمXGBoost کندتر است.
خلاصه و نتیجهگیری
در این پست الگوریتمAdaBoost را مورد بحث قرار دادیم. با معرفی یادگیری گروهی و انواع مختلف آن شروع کردیم تا متوجه شویم که الگوریتمAdaBoost دقیقاً در کجای این سیر تکاملی قرار میگیرد. مزایا و معایب این الگوریتم را مورد بحث قرار دادیم و یک مثال از پیادهسازی آن در محیط پایتون را ارائه کردیم.
الگوریتمAdaBoost ، در صورتی که به درستی مورد استفاده قرار بگیرد، مانند یک موهبت برای بهبود دقت مدلهای مختلف عمل میکند. AdaBoost اولین الگوریتم موفق برای تقویت عملکرد دستهبندیکنندههای دودویی است.AdaBoost بهطور فزایندهای در صنعت مورد استفاده قرار میگیرد و جایگاه خود را در سیستمهای تشخیص چهره برای تشخیص وجود یا عدم وجود چهره روی صفحه نیز بهخوبی پیدا کرده است.
در پایان امیدواریم این مقاله برایتان مفیده بوده باشد و از آن لذت برده باشید.
منبع

نظرات