مدلهای ترنسفورمر: مقدمه و کاتالوگ
ترجمه مریم سادات هاشمی از مقاله transformer models: an introduction and catalog

چکیده
در چند سال گذشته، شاهد ظهور سریع مدلهای پایهی مختلفی از خانواده ترنسفورمرها بودهایم. هدف از این پژوهش ارائة یک معرفی نسبتاً جامع و ساده از محبوبترین مدلهای ترنسفورمر است. این پژوهش همچنین مقدمهای بر جنبههای اساسی و نوآوریهای موجود در مدلهای ترنسفورمر را ارائه میکند. معرفی ما شامل مدلهایی است که با استفاده از یادگیری خود نظارتی (مانند BERT یا GPT3) آموزش داده شدهاند و همچنین مدلهایی که با کمک انسان برای انجام تصمیمگیری ساخته شدهاند (مانند مدل InstructGPT که توسط ChatGPT استفاده میشود).
-
مقدمه: ترنسفورمر چیست؟
ترنسفورمر دستهای از مدلهای یادگیری عمیق است که با ویژگیهای معماری خاصی تعریف میشود. این مدل برای اولین بار در مقاله معروف «Attention is All you Need» توسط محققان Google در سال 2017 معرفی شد و تنها در 5 سال 38 هزار استناد به دست آورده است.
معماری اصلی ترنسفورمر یک نمونهی خاص از مدلهای کدگذار - کدگشا است که این مدلها طی 2 تا 3 سال قبل شهرت یافته بودند. با این حال، تا آن زمان، توجه تنها یکی از مکانیزمهای مورد استفاده این مدلها بود که بیشتر بر اساس LSTM (Long Short Term Memory) و دیگر گونههای RNN (Recurrent Neural Networks) بودند. ایده کلیدی مقاله ترنسفورمر این بود که توجه میتواند به عنوان سازوکار و یک مکانیزم مهم برای استخراج وابستگی بین ورودی و خروجی مورد استفاده قرار گیرد.
ورودی ترنسفورمر دنبالهای از توکنها است. پس از پردازش ورودی توسط کدگذار، هر توکن ورودی، با یک بردار بازنمایی با ابعاد ثابت نشان داده میشود در حالی که یک بردار تعبیه جداگانه نیز برای کل دنباله ورودی ایجاد میشود. کدگشا از خروجی کدگذار به عنوان ورودی خود استفاده میکند و دنبالهای از توکنها را به عنوان نتیجه تولید میکند. در پردازش زبان طبیعی، توکنها میتوانند کلمه یا زیرکلمه باشند. زیرکلمه یا زیرواژه کوچکتر از یک کلمه است؛ یعنی کلمات را به چند قسمت تقسیم میکنیم، فایده این کار این است که میتوانیم واژگان جدیدی که قبلاً در لغتنامه نبوده است را بسازیم و حجم لغتنامه کاهش پیدا میکند. برای مثال کلمه «دانشجویان» به زیر کلمات «دانش» + «جو» + «یان» تقسیم میشود. در اینجا، «دانش» و «جو» به عنوان دو زیرکلمه مستقل استفاده میشوند و زیرکلمه «یان» به عنوان پسوندساز کلمه عمل میکند. زیرکلمهها در همه مدلهای ترنسفورمر استفاده میشوند. به خاطر سادگی، از اصطلاح «توکن» برای اشاره به ورودی و خروجیهای دنباله استفاده میکنیم که این توکنها زیرکلمههای سیستم پردازش زبان طبیعی را نشان میدهند. هنگامی که از ترنسفورمرها برای پردازش تصاویر یا ویدئو استفاده میشود، توکنها میتوانند قسمتی از تصاویر یا اشیا را نشان دهند.
از زمان انتشار مقاله ترنسفورمر، مدلهای محبوب مانند BERT و GPT فقط از بخش کدگذار یا کدگشای معماری اصلی ترنسفورمر استفاده کردهاند. در نتیجه، وجه اشتراک اصلی این مدلها در جنبه کدگذار - کدگشا نیست، بلکه در معماری لایههای جداگانه درون بخش کدگذار و کدگشا است. معماری لایه ترنسفورمر بر اساس یک مکانیزم توجهبهخود و یک لایهی روبهجلو ساخته شده است. جنبه اصلی این معماری این است که هر توکن ورودی در مسیر خود از این لایهها عبور میکند و همزمان با این عمل، به صورت مستقیم به هر توکن دیگری در دنباله ورودی وابسته است. این موضوع محاسبات موازی و مستقیم برای بازنمایی توکنهای متنی را امکانپذیر میکند که قبلاً با مدلهای متوالی مانند RNN غیرممکن بود.
-
معماری کدگذار/کدگشا
یک معماری کدگذار/کدگشای (شکل 1) از دو بخش تشکیل شده است. کدگذار ورودی را پردازش کرده و آن را به یک بردار با طول ثابت تبدیل میکند. پس از آن، کدگشا آن بردار را گرفته و به دنباله خروجی موردنظر تبدیل میکند. کدگذار و کدگشا به صورت مشترک آموزش داده میشوند تا احتمال شرطی log-likelihood خروجی را با توجه به ورودی به حداکثر برسانند. پس از آموزش، کدگذار/کدگشا میتواند یک دنباله ورودی را به دنباله خروجی تبدیل کند یا میتواند یک جفت دنباله ورودی/خروجی را امتیازدهی کند.
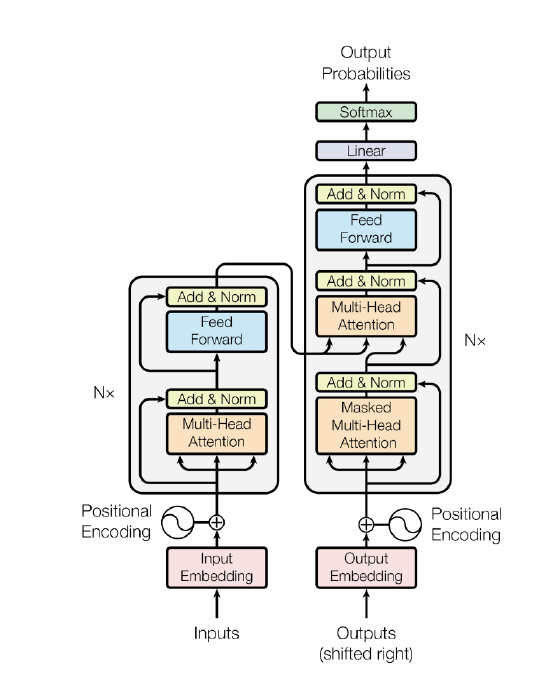
شکل 1: معماری ترنسفورمر
ترجمه سمت چپ به ترتیب از پایین به بالا:
Inputs: ورودی
Input Embedding: تعبیه ورودی
Positional Encoding: کدگذاری مکانی
Multi-Head Attention: توجه چند سر
Add & Norm: لایه جمع و نرمالسازی
Feed Forward: لایه روبهجلو
ترجمه سمت راست از پایین به بالا:
Outputs (shifted right): خروجی (به سمت راست شیفت شده)
Output Embedding: تعبیه خروجی
Positional Encoding: کدگذاری مکانی
Masked Multi-Head Attention: توجه چند سر ماسک شده
Add & Norm: لایه جمع و نرمالسازی
Multi-Head Attention: توجه چند سر
Feed Forward: لایه روبهجلو
Linear: لایه خطی
Softmax: لایه سافتمکس
Output Probabilities: احتمالهای خروجی
در معماری اولیه ترنسفورمر، هر دو بخش کدگذار و کدگشا از شش لایه یکسان تشکیل شده بودند. هر یک از این لایهها در کدگذار شامل دو زیرلایه است: یک لایه توجهبهخود چند سر و یک شبکه روبهجلو. لایه توجهبهخود، بازنمایی خروجی هر توکن ورودی را با در نظر گرفتن اطلاعات تمام توکنهای ورودی محاسبه میکند. هر زیرلایه همچنین دارای یک اتصال باقیمانده و یک لایه نرمالسازی است. اندازه بازنمایی خروجی کدگذار 512 است. لایه توجهبهخود چند سر در کدگشا کمی با لایه متناظر آن در کدگذار متفاوت است. در کدگشا، تمام توکنهایی که در سمت راست توکن مورد نظر قرار میگیرند، اصطلاحاً ماسک یا پوشانده میشوند(در زبانهایی که مثل انگلیسی از چپ به راست نوشته میشوند) تا اطمینان حاصل شود که کدگشا فقط میتواند به توکنهایی که قبل از توکن هدف برای پیشبینی قرار دارند، توجه کند. این موضوع در شکل 1 به عنوان «masked multi-head attention» نشان داده شده است. علاوه بر این، زیرلایه دیگری در کدگشا قرار دارد که توجه چند سر را روی تمام خروجیهای کدگذار به کار میبرد.
-
توجه
از توضیحات بخش قبل مشخص میشود که لایههای توجه چندسر عناصر منحصربهفرد و شگفتانگیز معماری مدل ترنسفورمر هستند و دقیقاً جایی هستند که تمام قدرت مدل متمرکز میشود؛ بنابراین، در این بخش میخواهیم به این سؤال پاسخ دهیم که توجه چیست. به طور ساده تابع توجه یک نگاشت بین یک کوئری و مجموعهای از جفتهای کلید - مقدار است که به یک خروجی میانجامد. در لایهی توجه، هر توکن ورودی با استفاده از سه ماتریس متناظر به سه بردار کوئری، کلید و مقدار تبدیل میشود. بازنمایی خروجی هر توکن با استفاده از جمع وزندار مقادیر همه توکنها محاسبه میشود که در آن وزن اختصاص داده شده به هر مقدار توسط تابع سازگاری کلید مرتبط با آن و کوئری توکنی که بازنمایی آن در حال محاسبه است؛ حساب میشود. تابع سازگاری مورد استفاده در ترنسفورمرها تابع ضرب نقطهای مقیاسپذیر است. یکی از جنبههای مهم مکانیزم توجه در ترنسفورمرها این است که هر توکن مسیر محاسباتی خود را دنبال میکند و امکان محاسبه موازی بازنماییها برای همه توکنها در دنباله ورودی فراهم میشود. اکنون که متوجه شدیم توجه چگونه کار میکند، بهتر است به این سوال پاسخ دهیم که توجه چند سر چیست؟ توجه چند سر شامل بلوکهای توجه متعددی است که به طور مستقل بازنماییهایی را برای هر توکن محاسبه میکنند. سپس این بازنماییها با هم ترکیب میشوند تا بازنمایی نهایی توکن را تشکیل دهند. شکل 2 از مقاله اصلی ترنسفورمر به صورت بصری مفهوم توجه را نشان میدهد.
لایههای توجه نسبت به شبکههای بازگشتی و کانولوشنال مزیتهای زیادی دارد. دو مورد از مهمترین آنها پیچیدگی محاسباتی کمتر و اتصالات بیشتر هستند که بهویژه برای یادگیری وابستگیهای طولانی در دنبالهها مفید هستند.
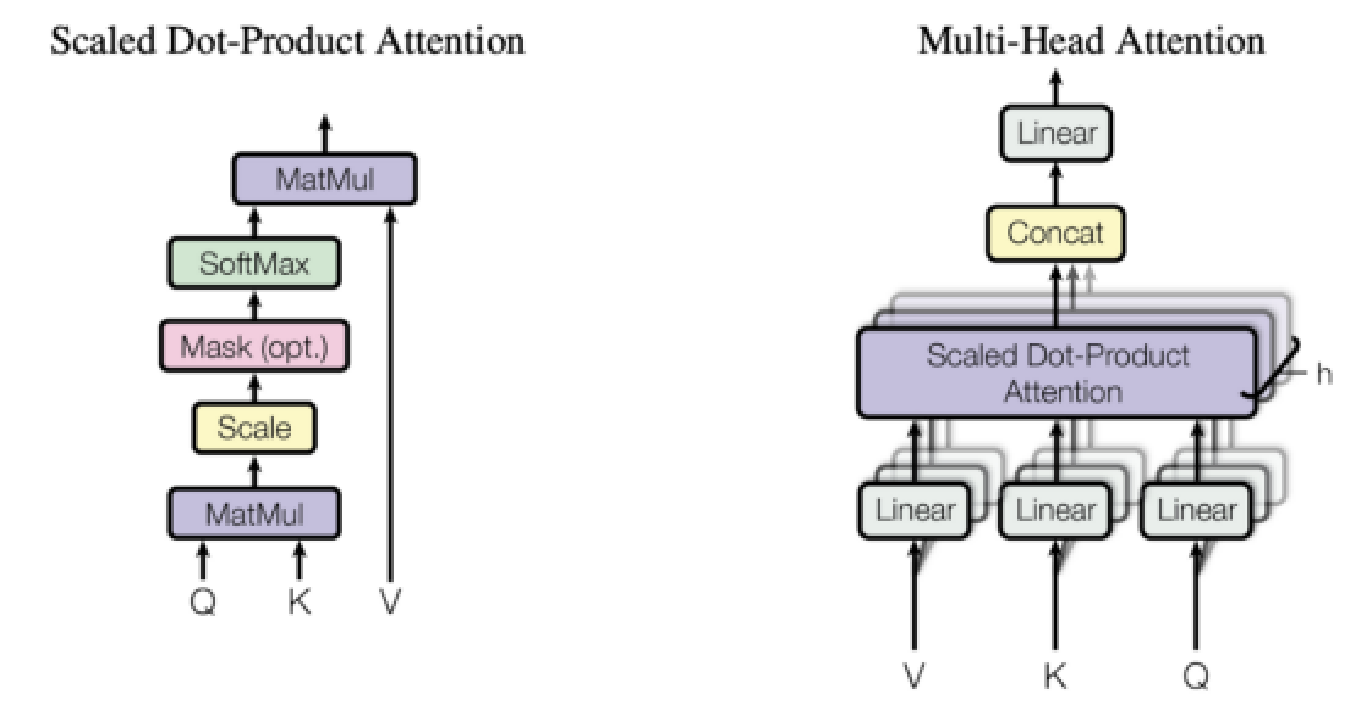
شکل 2: مکانیزم توجه
ترجمه سمت چپ از پایین به بالا:
MatMul: ضرب ماتریسی
Scale: مقیاس
Mask (opt.): عملیات مقیاس
SoftMax: لایه سافتمکس
Scaled Dot-Product Attention: توجه ضرب نقطهای مقیاسپذیر
ترجمه سمت راست از پایین به بالا:
Linear: لایه خطی
Scaled Dot-Product Attention: توجه ضرب نقطهای مقیاسپذیر
Concat: لایه الحاق
Multi-Head Attention: لایه توجه چند سر
-
مدلهای پایه در مقابل مدلهای دقیق تنظیم شده
مدل پایه به هر مدلی اطلاق میشود که بر روی دادههای گسترده و متنوع آموزشدیده باشد که معمولاً از خود نظارتی در مقیاس بزرگ استفاده میکند و میتواند برای وظایف مختلف پاییندستی تطبیق داده شود (به عنوان مثال، برای وظیفه ترجمه یا پرسش و پاسخ تنظیم دقیق شود) . هنگامی که مدل پایه بر روی مقدار کمی از دادههای خاص هدف آموزش داده میشود، به آن مدل دقیق تنظیم شده میگویند.
مقاله BERT رویکرد پیش آموزش و تنظیم دقیق برای پردازش زبان طبیعی را رایج کرد؛ بنابراین بسیاری از محققان از این رویکرد برای بسیاری از وظایف مختلف استفاده کردند. در نتیجه، مدلهای مبتنی بر ترنسفورمر، مانند BERT، بهترین نتیجه را در وظایف مختلف یادگیری ماشین مرتبط با زبان کسب کردند (برای مثال، بهترین مدلهای موجود در وظیفه SQUAD که یک مسئله پرسشوپاسخ در زبان است و یا وظیفه GLUE که برای درک عمومی زبان است، از ترنسفورمر استفاده میکنند).
در اصل، «تنظیم دقیق» به بهینهسازی یک مدل پایه برای یک کار خاص، مانند دستهبندی هرزنامه یا پاسخ به سؤال اشاره دارد. مدلهایی مانند BERT، بازنماییهایی از توکنهای ورودی تولید میکنند؛ اما بهخودیخود هیچ وظیفهای را انجام نمیدهند. به همین دلیل است که باید آنها را با افزودن لایههای اضافی و آموزش کل مدل برای وظایف موردنظر، تنظیم دقیق کرد.
برای مدلهای موّلد مانند GPT، روند تا حدودی متفاوت است. GPT یک مدل زبانی کدگشا است که به منظور پیشبینی توکن بعدی یک جمله با توجه به تمام توکنهای قبلی آموزش داده شده است. با توجه به این که مدل GPT بر روی مجموعههای گستردهای از وب که موضوعات مختلف را پوشش میدهند، آموزش دیده است؛ میتواند خروجیهای معقولی برای درخواستهای ورودی تولید کند. GPT توانست این کار را با حدس زدن کلمه بعدی بر اساس ورودی و کلماتی که قبلاً پیشبینی کرده بود انجام دهد. در واقع، این مدل زبانی وظایفی مانند پاسخ دادن به سؤالات مربوط به دانش عمومی وب، نوشتن شعر و غیره را تا حدودی به خوبی انجام میدهد؛ اما گاهی اوقات خروجیهای GPT نادرست هستند یا برای کاربر مفید نیستند. برای رفع این مشکل، محققان OpenAI ایده آموزش GPT را برای پیروی از دستورالعملهای انسانی مطرح کردند که منجر به توسعه مدلهای InstructGPT شد. محققان این کار را با استفاده از مقدار کمی از دادههای برچسبگذاری شده توسط انسان از انواع مختلفی از وظایف برای آموزش بیشتر GPT انجام دادند که نوعی تنظیم دقیق نیز در نظر گرفته میشود. مدل InstructGPT به دست آمده میتواند وظایف مختلفی را انجام دهد و پایه و اساس مدلهای محبوبی مانند ChatGPT است. به دلیل توانایی آنها در انجام وظایف مختلف، این مدلها به عنوان مدلهای پایه نامیده میشوند.
تنظیم دقیق برای ایجاد انواع مدلهای دیگر استفاده شده است که به طور خاص برای موارد کاربردی خارج از مدلسازی زبان (پیشبینی توکن بعدی در یک دنباله) طراحی شده است. به عنوان مثال، مدلهایی برای یادگیری تعبیههای رشتههای متنی وجود دارند که توسط تنظیم دقیق بهبود یافتهاند که باعث میشود این مدلها مستقیماً برای کارهای معنایی سطح بالاتر مانند دستهبندی متن، خوشهبندی و بازیابی اطلاعات مفید باشند. به برخی از نمونههای این مدلها، مانند مدلهای تعبیه شرکت OpenAI، E5 و InstructOR میتوان اشاره کرد. مدلهای کدگذار ترنسفورمر نیز با موفقیت در چارچوبهای یادگیری چندوظیفهای تنظیم شدهاند تا بتوانند چندین کار معنایی مختلف را با استفاده از یک مدل ترنسفورمر مشترک انجام دهند.
بنابراین، همانطور که میبینید، در ابتدا، مدلهای پایه برای وظایف خاص و گروههای خاصی از کاربران
تنظیم میشدند، اما امروزه، تنظیم دقیق برای ایجاد نسخههای بیشتری از مدلهای پایه نیز به کار میرود تا تعداد
زیادی از کاربران بتوانند از آنها بهرهمند شوند. روش استفاده شده توسط ChatGPT و عاملهای گفتگوی مشابه مانند
BlenderBot3 یا Sparrow نسبتاً ساده است: از یک مدل زبانی از پیش آموزشدیده مثل GPT، برای تولید پاسخهای مختلف به
درخواستهای ورودی (دستورات ورودی) استفاده میشود و
انسانها نتایج را رتبهبندی میکنند. سپس این رتبهبندیها (همچنین به عنوان
ترجیحات یا بازخورد شناخته میشوند) برای آموزش یک مدل
پاداش استفاده میشوند. مدل پاداش به هر خروجی برای یک دستور ورودی خاص امتیاز اختصاص میدهد. پس از این، فرایند
یادگیری تقویتی با بازخورد انسانی (RLHF) برای آموزش مدل بر روی دستورالعملهای ورودی
اجرا میشود، اما بهجای استفاده از انسان برای تولید بازخورد، از مدل پاداش برای رتبهبندی خروجیهای مدل استفاده
میشود. اگر علاقهمند به یادگیری بیشتر هستید، میتوانید به 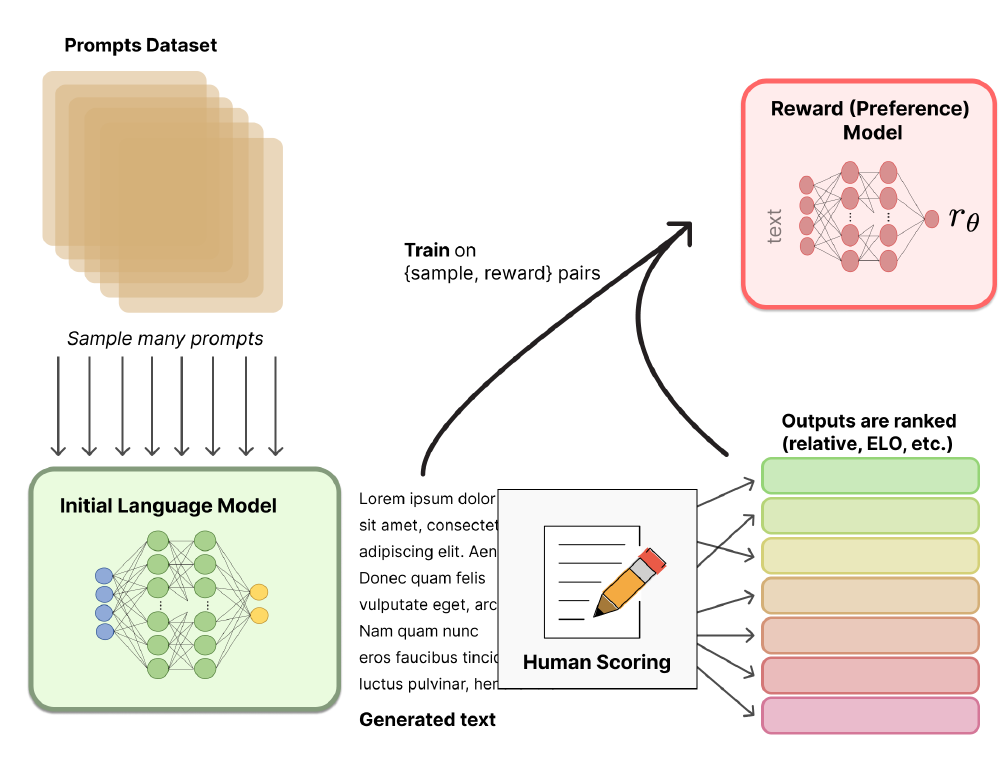 این دو مقاله از Huggingface و Ayush
Thakur مراجعه کنید.
این دو مقاله از Huggingface و Ayush
Thakur مراجعه کنید.
ترجمه عکس:
Prompts Datastet: مجموعه داده محرکها
Sample many prompts: نمونهبرداری از تعداد زیادی محرک
Initial Language Model: مدل زبانی اولیه
Generated text: متن تولید شده
Human Scoring: امتیاز توسط انسان
Outputs are rankek: خروجیها امتیاز داده میشود
Train on (sample, reward) pairs: آموزش بر روی دوتاییهای (نمونه، پاداش)
Reward (preference) Model: مدل پاداش (ترجیح)
-
تأثیر ترنسفورمرها
در مقاله ترنسفورمر، ترجمه زبان به عنوان کاربرد اصلی معرفی گردید. علاوه بر این، این مقاله نشان داد که معماری ترنسفورمر میتواند به طور مؤثر به سایر وظایف مرتبط با زبان گسترش یابد. متعاقباً، محققان دریافتند که مدلهای ترنسفورمر توانایی درک دانش زبانی قابلتوجهی را با پیش آموزش بر روی حجم وسیعی از متنها بدون نظارت دارند. این دانش بهدستآمده را میتوان با آموزش مدل بر روی مجموعهای محدود از دادههای برچسبگذاری شده برای وظایف خاص مورداستفاده قرار داد.
اگرچه ترنسفورمرها در درجه اول برای کارهای مرتبط با زبان در نظر گرفته شده بودند، اما بهمرور در حوزههای مختلف دیگر مانند تولید تصویر، تولید صدا و موسیقی کاربرد گستردهای پیدا کرد. این تطبیقپذیری قابلتوجه، ترنسفورمر را به عنوان یک عنصر اساسی در قلمرو نوظهور "هوش مصنوعی موّلد" معرفی کرده است. پتانسیل گسترده هوش مصنوعی موّلد و کاربردهای متنوع آن در حال حاضر باعث تحولات قابلتوجهی در جنبههای مختلف جامعه شده است.
مطمئناً، اگر ابزارهای فراوانی که تنها با چند خط کد مدلهای مبتنی بر ترنسفورمر را برای هر کسی در دسترس قرار میداد، نبود، این همه کاربردهای متنوع امکانپذیر نبودند. مدلهای ترنسفورمر بهسرعت به فریمورکهای اصلی هوش مصنوعی مانند Pytorch و TensorFlow اضافه شدند و حتی منجر به تولد یک شرکت شدند. Huggingface، استارتآپی که تاکنون بیش از 60 میلیون دلار جمعآوری کرده است، تقریباً حول محور ایده کسب درآمد از کتابخانه منبعباز Transformers ساخته شد.
استفاده از مدلهای ترنسفورمر با توسعه سختافزارهای تخصصی توسط غولهای تجاری برای بهبود آموزش مدل و سرعت استنتاج، شتاب بیشتری میگیرد. به عنوان مثال، NVIDIA's Hopper Tensor Cores میتوانند از دقت FP8 و FP16 استفاده کنند تا محاسبات هوش مصنوعی را برای ترنسفورمرها به طور چشمگیری تسریع کنند.
در آخر، ما نمیتوانیم تأثیر قابلتوجه ChatGPT در مشهورشدن مدلهای ترنسفورمر را نادیده بگیریم. هنگامی که OpenAI مدل ChatGPT را در نوامبر 2022 منتشر کرد، به سریعترین برنامه درحالرشد تاریخ تبدیل شد و 1 میلیون کاربر در کمتر از یک ماه و 100 میلیون کاربر در کمتر از دو ماه به استفاده از آن پرداختند. ChatGPT در اصل یک برنامه چتبات است و بر روی مدل Instruct-GPT ساخته شده است که GPT-3.5 نیز نامیده میشود. چندی بعد، OpenAI از انتشار یک مدل قدرتمندتر به نام GPT-4 خبر داد که به تواناییهای انسانی در وظایفی مانند قبولی در آزمون USMLE برای پزشکان یا آزمون وکالت برای وکلا دستیافت.
-
نکتهای در مورد مدلهای Diffusion
مدلهای Diffusion بهعنوان رویکرد پیشرفتهای برای تولید تصویر پدیدار شدهاند و به طور مؤثر جایگزین روشهای قبلی مانند GAN (Generative Adversarial Network) شدهاند. توجه به این نکته مهم است که مکانیزم Diffusion به معماری ترنسفورمر وابسته نیست. با این حال، در اکثر رویکردهای مدرن Diffusion، ترنسفورمر به عنوان پایه و اساس گنجانده شده است.
مدلهای Diffusion متعلق به دسته مدلهای متغیرهای پنهان هستند و با استفاده از variational inference آموزش داده میشوند. معنی این در عمل این است که ما یک شبکه عصبی عمیق را آموزش میدهیم تا نویز را از تصاویری که با یک تابع نویز خاص تار شدهاند حذف کند. با آموزش به این روش، شبکهها به طور مؤثر فضای بازنمایی زیربنایی آن تصاویر را یاد میگیرند (شکل 4 را ببینید).
مدلهای Diffusion با سایر مدلهای مولد مانند Denoising Autoencoder و شبکههای GAN شباهت دارند و در بسیاری از برنامهها جایگزین شدهاند. برخی از نویسندگان تا آنجا پیش میروند که میگویند مدلهای Diffusion فقط یک نمونه خاص از کدگذارهای خودکار هستند. با این حال، آنها همچنین اذعان میکنند که تفاوتهای کوچک، کاربردشان را از بازنمایی پنهان کدگذارهای خودکار به ماهیت تولیدی مدلهای Diffusion تبدیل میکند.

شکل 4: معماری مدل Diffusion احتمالی از مقاله «Diffusion Models: A Comprehensive Survey of Methods and Applications»
ترجمه تصویر:
Data: داده
Destructing data by adding noise: خراب کردن داده با اضافه کردن نویز
Noise: نویز
Score function: تابع امتیازدهی
Probability of perturbed data: احتمال دادههایی که نویز به آنها اضافه شده است.
One denoising step: یک مرحله از حذف نویز
Generating samples by denoising: تولیده کردن نمونهها به وسیله حذف نویز
ترجمه متن زیر شکل: شکل 2. مدلهای diffusion به آرامی دادهها را با اضافه کردن نویز مختل میکنند، سپس این فرآیند را معکوس میکنند تا دادههای جدیدی از نویز تولید شود. هر مرحله از حذف نویز در فرآیند معکوس معمولاً نیاز به تخمین تابع امتیاز دارد (سمت راست شکل را مشاهده کنید)، که یک گرادیان است که به جهت دادهها با احتمال بالاتر و نویز کمتر اشاره میکند.
-
کاتالوگ ترنسفورمرها
-
ویژگیهای ترنسفورمر
در این بخش به معرفی فهرستی جامع از مهمترین مدلهای ترنسفورمر که امروزه توسعه یافتهاند میپردازیم. ما هر مدل را بر اساس ویژگیهای زیر دستهبندی میکنیم: خانواده، معماری پیشآموزش، وظیفه پیشآموزش یا تنظیم دقیق، افزونه، کاربرد، تاریخ، تعداد پارامترها، پیکره، مجوز و آزمایشگاه. درک برخی از آنها نسبتاً ساده است: خانواده نشان میدهد که یک مدل بر اساس کدام مدل پایه اصلی ساخته شده است. افزونه توضیح میدهد که مدل چه چیزی را به مدلی که از آن مشتق شده است اضافه میکند. تاریخ زمانی است که مدل برای اولینبار منتشر شد. تعداد پارامترها مشخص میکند که چه تعداد پارامتر در مدل از پیش آموزش دیده استفاده شده است. پیکره منابع دادهای است که مدل از قبل آموزش دیده یا تنظیم شده است. مجوز توضیح میدهد که چگونه میتوان از مدل به طور قانونی استفاده کرد و آزمایشگاه به موسسهای که مسئول انتشار مدل است اشاره میکند. سایر ویژگیها را در ادامه توضیح میدهیم.
-
معماری پیشآموزش
ما معماری ترنسفورمر را متشکل از یک کدگذار و یک کدگشا توصیف کردیم که برای ترنسفورمر اصلی صادق است. با این حال، از آن زمان، پیشرفتهای مختلفی صورت گرفته است که مشخص شده است در برخی موارد، استفاده از مدل فقط کدگذار یا فقط کدگشا و یا هر دو مفید است.
پیشآموزش مدلهای کدگذار
این مدلها که کدگذاری دوطرفه یا خودکار نیز نامیده میشوند، فقط از کدگذار در هنگام پیش آموزش استفاده میکنند که معمولاً با پوشاندن یا ماسک کردن توکنها در جمله ورودی و آموزش مدل برای بازسازی آن توکنها انجام میشود. در هر مرحله در طول پیشآموزش، لایههای توجهبهخود میتوانند به تمام توکنهای ورودی خود دسترسی داشته باشند. این خانواده از مدلها برای کارهایی که نیاز به درک جملات یا عبارات کامل دارند، مانند طبقهبندی متن، استنتاج متن و پرسش پاسخ استخراجی بسیار مفید هستند.
پیشآموزش مدلهای کدگشا
این مدلها فقط از کدگشا در طول دوره پیشآموزش استفاده میکنند. به آنها مدلهای زبانی رگرسیون خودکار نیز میگویند، زیرا برای پیشبینی توکن بعدی بر اساس توکنهای قبلی آموزشدیدهاند. لایههای توجهبهخود فقط میتوانند به توکنهایی که قبل از یک توکن داده شده در جمله قرار گرفتهاند؛ دسترسی داشته باشند. این مدلها برای کارهای مربوط به تولید متن مناسب هستند.
پیشآموزش مدلهای کدگذار - کدگشا
مدلهای کدگذار - کدگشا که دنبالهبهدنباله نیز نامیده میشوند، از هر دو بخش معماری ترنسفورمر استفاده میکنند. لایههای توجهبهخود کدگذار میتوانند به تمام توکنهای ورودی خود دسترسی داشته باشند، در حالی که لایههای توجهبهخود کدگشا فقط میتوانند به توکنهایی که قبل از یک توکن داده شده قرار دارند دسترسی داشته باشند. همانطور که قبلاً توضیح داده شد، لایه توجه اضافهای که در کدگشا است امکان دسترسی به تمام بازنماییهای کدگذار را فراهم میکند.
یک مدل کدگذار - کدگشا را میتوان با بهینهسازیdenoising یا ترکیبی از denoising and causal language modeling از پیش آموزش داد. این توابع هدف در مقایسه با توابع مورد استفاده برای پیشآموزش مدلهای فقط کدگذار یا مدلهای فقط کدگشا پیچیده هستند. مدلهای کدگذار - کدگشا برای کارهایی که حول محور تولید جملات جدید بسته به ورودی داده شده، مانند خلاصهسازی، ترجمه، یا پرسش پاسخ تولیدی میچرخند، مناسبتر هستند.
-
وظیفه پیشآموزش یا تنظیم دقیق
هنگام آموزش یک مدل، باید هدف یا وظیفهای را تعریف کنیم تا مدل بتواند آن را یاد بگیرد. برخی از وظایف معمولی، مانند پیشبینی توکن بعدی یا یادگیری بازسازی توکنهای ماسکدار قبلاً در بالا ذکر شد. مقاله «Pre-trained Models for Natural Language Processing: A Survey » شامل یک طبقهبندی کاملاً جامع از وظایف پیشآموزشی است که همه آنها را میتوان تحت عنوان یادگیری خود نظارتی در نظر گرفت:
- Language Modeling (LM): به پیشبینی توکن بعدی (در مدلهای زبانی یکطرفه) یا پیشبینی توکن قبلی و بعدی (در مدلهای زبانی دوطرفه) اشاره میکند.
- Causal Language Modeling (Causality-masked LM): وظیفه پیشبینی یک دنباله به صورت رگرسیون خودکار را (به طور کلی از چپ به راست) مانند مدلهای زبانی یکطرفه انجام میدهد.
- Prefix Language Modeling (Prefix LM): در این وظیفه بخش جداگانهای به نام «پیشوند» وجود دارد که از دنباله اصلی متمایز است. در داخل پیشوند، هر توکنی میتواند به هر توکن دیگری توجه کند. خارج از پیشوند، فرایند کدگشایی از یک رویکرد رگرسیون خودکار پیروی میکند.
- Masked Language Modeling (MLM): توکنهای خاصی در جملات ورودی، پنهان یا «ماسک شده» هستند. سپس این مدل برای پیشبینی این نشانههای ماسکدار بر اساس متون اطراف توکن آموزش داده میشود.
- Permuted Language Modeling (PLM): PLM مشابه LM استاندارد است، اما بر اساس یک جایگشت تصادفی از دنبالههای ورودی عمل میکند. یک جایگشت تصادفی از بین همه جایگشتهای ممکن انتخاب میشود و سپس توکنهای خاصی به عنوان هدف انتخاب میشوند. این مدل برای پیشبینی این توکنهای هدف آموزش داده میشود.
- Denoising Autoencoder (DAE): در Denoising Autoencoder هدف، گرفتن یک ورودی تا حدی خراب و بازگرداندن آن به شکل اصلی و بدون تحریف آن است. ورودی را میتوان به روشهای مختلفی خراب کرد، مانند نمونهبرداری تصادفی از توکنها و جایگزینی آنها با توکن ماسک، حذف تصادفی توکنها یا بههمریختن جملات بهصورت تصادفی.
- Replaced Token Detection (RTD): در Replaced Token Detection، با استفاده از یک مدل «موّلد» توکنهای خاصی در متن به صورت تصادفی جایگزین میشوند. سپس «متمایزکننده» وظیفه دارد پیشبینی کند آیا هر توکن متعلق به متن اصلی است یا از مدل تولید کننده میآید.
- Next Sentence Prediction (NSP): پیشبینی جمله بعدی شامل آموزش مدل برای تشخیص اینکه آیا دو جمله ورودی، بخشهای متوالی استخراج شده از مجموعه آموزشی هستند یا خیر.
توجه داشته باشید که در مورد مدلهای تنظیمشده، این ویژگی برای توصیف وظیفهای استفاده میشود که مدل برای آن تنظیم شده است، نه اینکه مدل چگونه از قبل آموزش داده شده است.
-
کاربرد
در اینجا به کاربردهای عملی مدل ترنسفورمر اشاره خواهیم کرد. بیشتر این کاربردها در حوزه زبان (مانند پرسش پاسخ، تجزیه و تحلیل احساسات، یا تشخیص موجودیت) خواهند بود. با این حال، همانطور که قبلاً ذکر شد، برخی از مدلهای ترنسفورمر نیز کاربردهایی فراتر از NLP پیدا کردهاند
-
شجرهنامه
نمودار شکل 5 نمای سادهای از خانوادههای مختلف ترنسفورمرها و نحوه ارتباط آنها با یکدیگر را نشان میدهد.
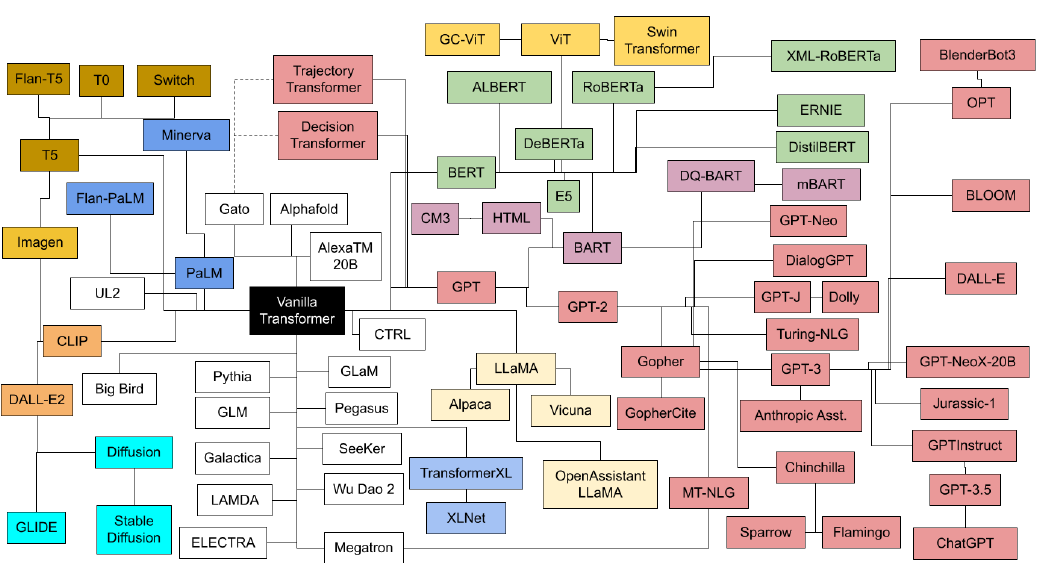
شکل 5: شجرهنامه مدلهای ترنسفورمر
-
جدول زمانی
در شکل 6، ترنسفورمرهای موجود را میبینید که بر اساس تاریخ انتشارشان مرتب شدهاند. محور Y در شکل 6 برای گروهبندی ترنسفورمرها بر اساس اجداد یا خانوادهشان استفاده شده است. در شکل 7، محور Y اندازه مدل (تعداد پارامترها برحسب میلیون) را نشان میدهد. با توجه به زمان و اندازههای مشابه بسیاری از مدلها، همه مدلها در این تصویر قابلمشاهده نیستند، بنابراین میتوانید برای مشاهده کامل به شکل 6 مراجعه کنید. از زمان معرفی chatGPT، جامعه منبعباز LLM فعالیت قابلتوجهی داشته است. هر هفته که میگذرد، مدلهای پیشرفتهتری عرضه میشود که با استفاده از جدیدترین فناوریها تنظیم شدهاند. در نتیجه، این مدلها به طور مداوم در حال بهبود هستند و قویتر و قدرتمندتر میشوند. شکل 8 مدلهای اخیراً منتشر شده از فوریه 2023 را نشان میدهد.

شکل 6: جدول زمانی مدلهای ترنسفورمر
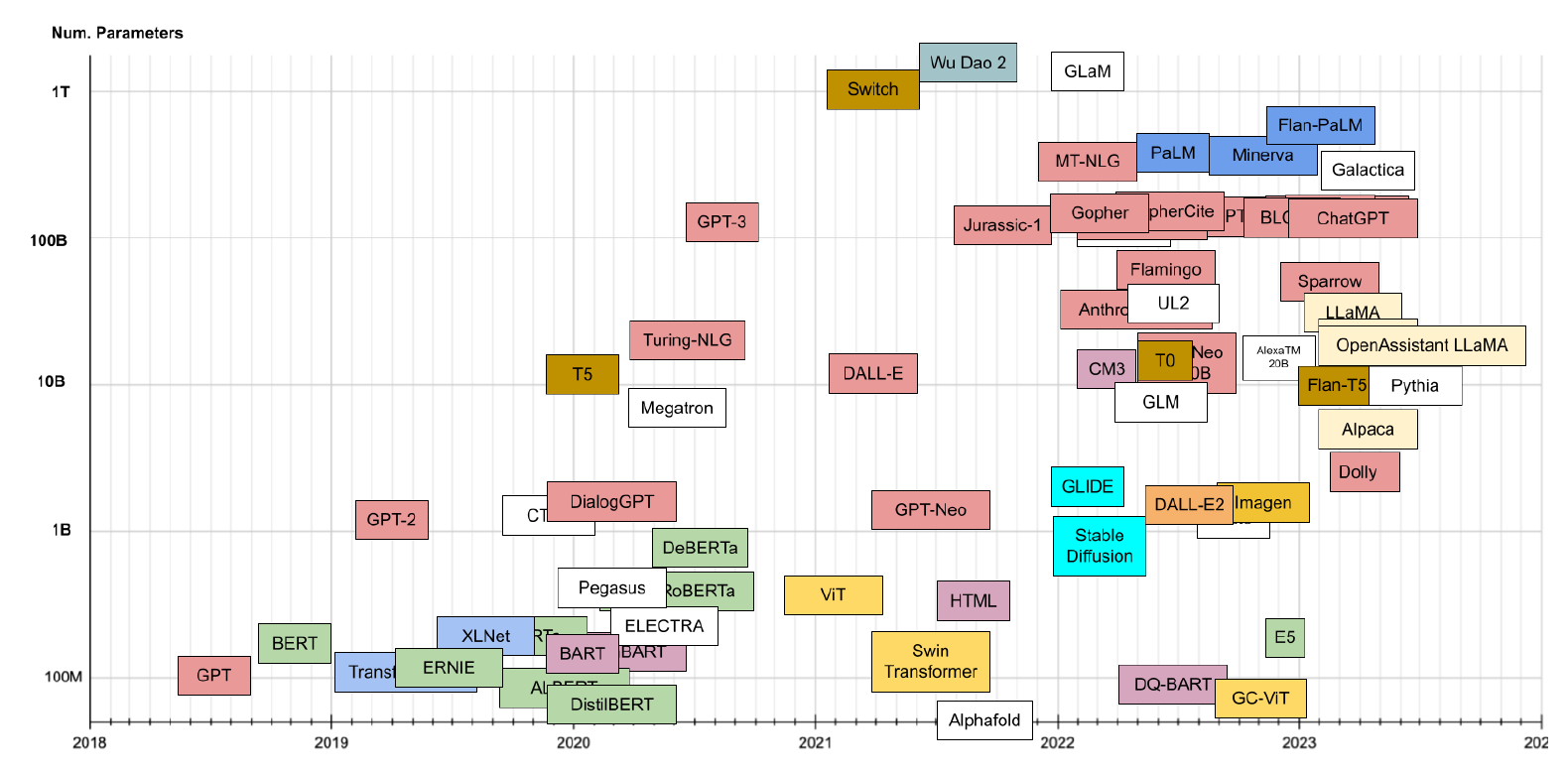
شکل 7: جدول زمانی مدلهای ترنسفورمر
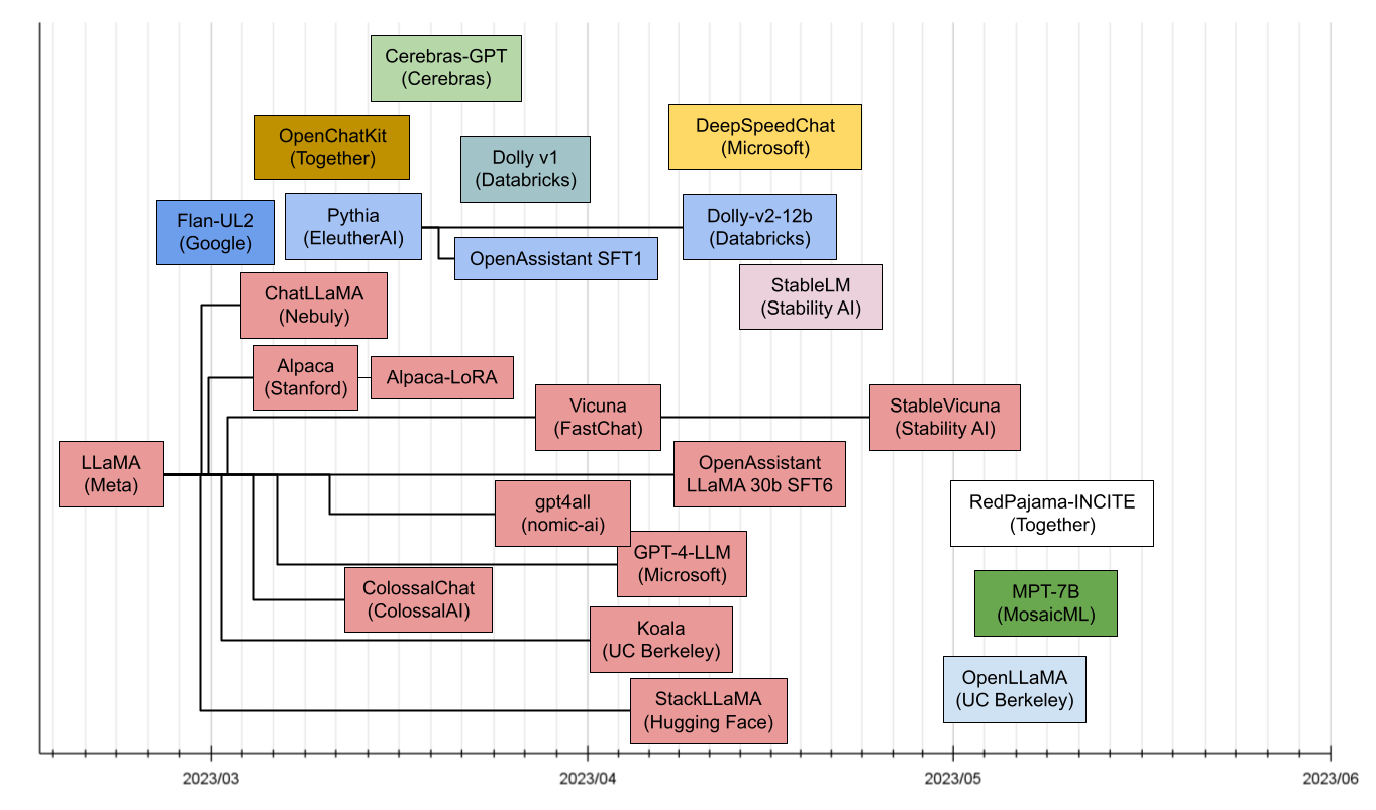
شکل 8: مدلهای زبانی بزرگ اخیراً منتشر شده

نظرات