"نگاشت دنبالهبهدنباله با استفاده از شبکههای عصبی"
ترجمه ساراناز عبداللهی از مقاله Sequence to Sequence Learning with Neural Networks

مقدمه
شبکههای عصبی عمیق (DNN) مدلهای قدرتمندی هستند که عملکرد چشمگیری در در یادگیری مسائل پیچیده دارند. با وجود اینکه شبکههای عصبی عمیق در مسائلی که مجموعههای آموزشی برچسبدار بزرگ دارند، بهخوبی عمل میکنند اما برای نگاشت یک دنباله به دنبالهای دیگر مناسب نیستند. به همین منظور، در این مقاله یک رویکرد جامع برای یادگیری دنبالهها پیشنهاد شدهاست که در آن حداقل محدودیتها در ساختار دنباله در نظر گرفته میشود. در ادامه، به معرفی مدل پیشنهادی این مقاله میپردازیم.
مشکل چیست؟
شبکههای عصبی عمیق (DNNها) مدلهای یادگیری ماشین قدرتمند و بسیار مؤثری هستند که در حل مسائل مختلفی مانند تشخیص گفتار و تشخیص اشیاء بصری عملکرد خوبی بهدست آوردهاند. یکی از دلایل قدرتمندیDNN ها، این است که میتوانند محاسبات زیادی را در مراحل کم و بهصورت موازی انجام دهند. برای مثال، یک شبکهی DNN از مرتبهی دو و تنها با 2 لایۀ پنهان، میتواند N عدد N بیت را مرتب کند، که این نمایشی چشمگیر از قدرت محاسباتی آنها است.
اگرچه شبکههای عصبی شباهتهایی به مدلهای آماری معمولی دارند، اما قادر به یادگیری محاسبات پیچیده هستند. بهطور خاص، شبکههای DNN بزرگ را میتوان با استفاده از تکنیکی به نام پسانتشار با نظارت، بهطور موثر آموزش داد. این فرآیند شامل تنظیم کردن پارامترهای شبکه در طول آموزش است به گونهای که میزان خطا بین خروجیهای هدف و خروجیهای پیشبینی شده به حداقل برسد. اگر مجموعه آموزشی برچسبدار حاوی اطلاعات کافی برای تعیین پارامترهای شبکه باشد، پسانتشار با نظارت، میتواند پارامترهای بهینه را برای دستیابی به نتایج بهتر پیدا کند. این فرآیند نشاندهنده تطبیقپذیری و سازگاری DNNها در یافتن راه حل برای وظایف پیچیده است.
اگر چه DNNها بسیار انعطافپذیر و قدرتمند هستند، اما محدودیتهایی نیز دارند. این شبکهها فقط در مسائلی به کار برده میشوند که ورودیها و اهداف آنها را بتوان با بردارهایی با ابعاد ثابت کدگذاری کرد. این یک محدودیت قابل توجه است، زیرا در بسیاری از مسائل مهم، ورودیها طول یکسانی ندارند. بهعنوان مثال، در وظایفی مانند تشخیص گفتار و ترجمه ماشینی، ورودی و خروجی بردارهایی با اندازه ثابت نیستند، بلکه دنبالههایی با طول متغیر هستند.
یادگیری دنبالههایی با طولهای متفاوت، DNNهای سنتی را با چالش روبرو میکند، چراکه در این شبکهها نیاز است ابعاد ورودی و خروجی مشخص و ثابت باشد. چالش دیگری که در یادگیری دنبالهها با آن مواجهیم، بلند بودن طول دنبالهها است. در این پست میخواهیم با کمک مقاله توضیح دهیم که LSTM چگونه میتواند بهطور موثر مسائل نگاشت دنبالهبهدنباله را حل کند.
چگونه قرار است مشکل را حل کنیم؟
شبکه عصبی بازگشتی (RNN) تعمیمی از شبکههای عصبی روبهجلو است که برای پردازش دادههای دنبالهای مانند عکسهای متحرک، موسیقی، متن و غیره طراحی شده است. RNN قادر است دادههای دنبالهای را که بهصورت مرتبط و متوالی هستند، پردازش کند. RNN با نگهداری اطلاعات بهدست آمده از مراحل قبلی و به کارگیری آنها در مراحل بعدی دنبالهها را پردازش میکند. یک RNN استاندارد با توجه به دنبالهی ورودی ![]() ، دنبالهی خروجی
، دنبالهی خروجی ![]() را با تکرار فرمول زیر محاسبه می کند:
را با تکرار فرمول زیر محاسبه می کند:
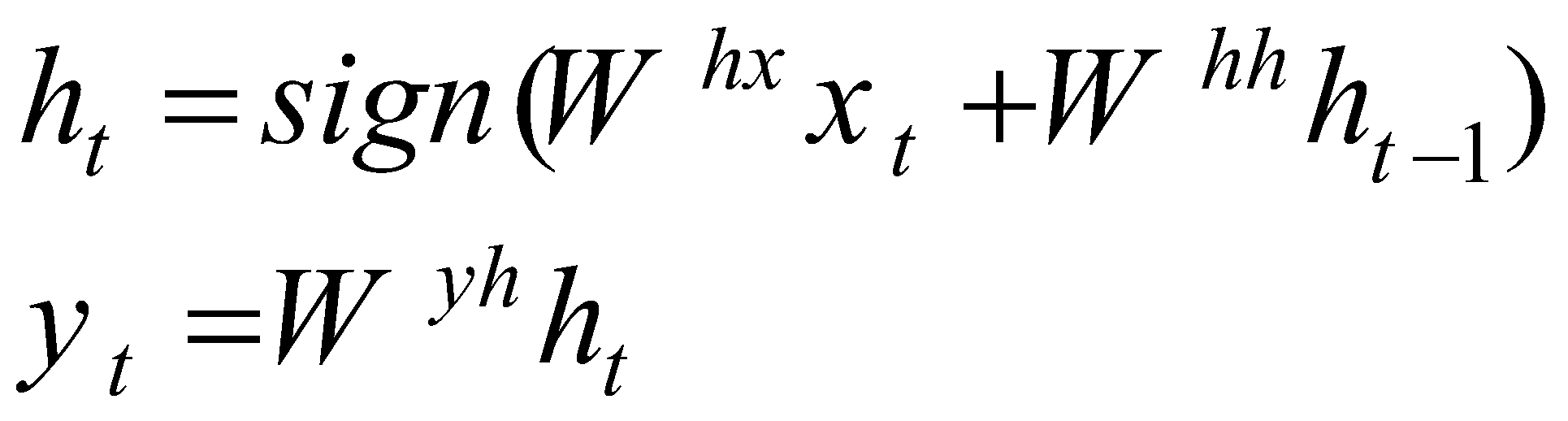
فرمول اول شیوهی بهروزرسانی وضعیت پنهان را نشان میدهد. در این فرمول ht نماینده وضعیت پنهان در زمان t، sign نماینده تابع فعالسازی،Whx نشاندهنده ماتریس وزن بین ورودی Xt و وضعیت پنهان ht و Whh نشاندهنده ماتریس وزن بین وضعیت پنهان قبلی ht-1 و وضعیت پنهان فعلی ht است. با توجه به این فرمول، وضعیت پنهان در هر مرحله با توجه به ورودی فعلی و اطلاعات بدست آمده از ورودیهای قبلی که در وضعیت پنهان ht-1 ذخیره شده است، به روزرسانی میشود. این فرمول نشان میدهد که هر ورودی، با توجه به اطلاعات دنبالهای بدست آمده در طول زمان، پردازش میشود.
فرمول دوم روش تولید خروجی را نشان میدهد. در این فرمول yt نماینده خروجی در زمان t ، Wyh نشاندهنده ماتریس وزن بین وضعیت پنهان ht و خروجی yt است. با توجه به فرمول دوم، خروجی براساس وضعیت پنهان فعلی تولید میشود.
اگر بدانیم که هر عنصر یا کلمه در دنباله ورودی با یک عنصر یا کلمه در دنباله خروجی متناظر است، مدل RNN بهراحتی میتواند این تطابق را درک کند و دنباله ورودی را به دنباله خروجی نگاشت کند. با این حال، استفاده از RNN برای حل مسائلی که در آن دنبالههای ورودی و خروجی دارای طولهای متفاوت با روابط پیچیده و غیر یکنواخت هستند، با چالش هایی روبروست.
بهطور کلی سادهترین روش برای یادگیری دنبالهها، توسط چو ارائه شدهاست. آنها در این روش با استفاده از RNN، دنباله ورودی را به یک بردار با اندازه ثابت نگاشت میکنند. سپس بردار بهدست آمده را به دنباله هدف نگاشت میکنند. ایده استفاده از RNN در این رویکرد از نظر تئوری امکانپذیر به نظر میرسد زیرا RNN به تمام اطلاعات لازم دسترسی دارد، اما RNN در یادگیری دنبالههای طولانی به دلیل وجود وابستگیهای طولانیمدت، عملکرد خوبی ندارد.
گزینهای جایگزین در حل این چالش، مدل حافظه کوتاهمدت بلندمدت (LSTM) است. این مدل در یادگیری وظایف مربوط به وابستگیهای طولانیمدت(دوربرد) توانمند است. وابستگی طولانیمدت مربوط به عناصر یک دنباله است و زمانی اتفاق میافتد که هر عنصر در دنباله بهصورت مستقیم یا غیرمستقیم به عناصر قبل یا بعد از خود وابسته باشد. این وابستگیها میتوانند مستقیم روی تولید خروجی تأثیر داشته باشند و یا برای درک کامل دنباله لازم باشند.
در معماری پیشنهادی این مقاله با استفاده از شبکهی LSTM، ابتدا دنبالهی ورودی به یک بردار میانی(بردار بازنمایی) تبدیل و در مرحلهی بعد بردار بازنمایی به دنبالهی هدف نگاشت میشود. به این ترتیب یک دنباله با طول متغیر توسط شبکه پردازش شده و دنبالهی خروجی متناظر با آن تولید میشود.
در اینجا هدف LSTM تخمین احتمال شرطی ![]() است که در آن
است که در آن ![]() یک دنباله ورودی و
یک دنباله ورودی و ![]() دنباله خروجی متناظرِ آن است که در آن طول T` با T می تواند متفاوت باشد. LSTM ابتدا بردار بازنمایی v از بردار ورودی را با توجه آخرین حالت پنهان LSTM محاسبه میکند. سپس احتمال خروجی
دنباله خروجی متناظرِ آن است که در آن طول T` با T می تواند متفاوت باشد. LSTM ابتدا بردار بازنمایی v از بردار ورودی را با توجه آخرین حالت پنهان LSTM محاسبه میکند. سپس احتمال خروجی ![]() را با فرمول استاندارد LSTM-LM محاسبه میکند(حالت پنهان اولیه در فرمول، با بردار بازنمایی v مقداردهی شدهاست):
را با فرمول استاندارد LSTM-LM محاسبه میکند(حالت پنهان اولیه در فرمول، با بردار بازنمایی v مقداردهی شدهاست):
در این فرمول، ![]() نماینده دنباله خروجی،
نماینده دنباله خروجی، ![]() نماینده دنباله ورودی و T` طول دنباله خروجی است. این فرمول نشان میدهد که احتمال کل دنباله خروجی به شرط دنباله ورودی با استفاده از قاعده زنجیرهای، با ضرب احتمالهای شرطی حساب شده برای اضافه شدن هر کلمهی جدید به عناصر قبلی جمله، بهصورت ترتیبی محاسبه میشود. به بیان سادهتر، مدل هر کلمه ی جدید در دنبالهی خروجی را با توجه به دنبالهی ورودی و کلمات قبلی پیشبینی شده در دنباله ی خروجی، تولید میکند. به این ترتیب وابستگی بین کلمات در دنباله مدل میشوند.
نماینده دنباله ورودی و T` طول دنباله خروجی است. این فرمول نشان میدهد که احتمال کل دنباله خروجی به شرط دنباله ورودی با استفاده از قاعده زنجیرهای، با ضرب احتمالهای شرطی حساب شده برای اضافه شدن هر کلمهی جدید به عناصر قبلی جمله، بهصورت ترتیبی محاسبه میشود. به بیان سادهتر، مدل هر کلمه ی جدید در دنبالهی خروجی را با توجه به دنبالهی ورودی و کلمات قبلی پیشبینی شده در دنباله ی خروجی، تولید میکند. به این ترتیب وابستگی بین کلمات در دنباله مدل میشوند.
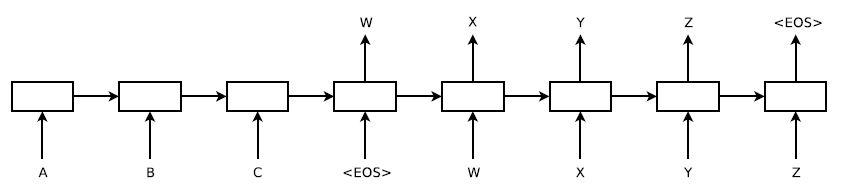
در این فرمول، هر توزیع ![]() با یک تابع softmax بر روی تمام کلمات موجود در مجموعه واژگان نشان داده میشود. در این مقاله از فرمول LSTM گریوز استفاده شدهاست. باید توجه داشت که هر جمله باید با یک نماد پایان جمله خاص "" پایان یابد. این نماد مدل را قادر میسازد تا توزیعی را روی دنبالههایی با تمام طولهای ممکن تعریف کند. براساس طرح کلی در شکل 1، LSTM بازنمایی "A","B","C","" را محاسبه میکند و سپس از این بازنمایی برای محاسبه احتمال "W","X","Y","Z","" استفاده میکند.
با یک تابع softmax بر روی تمام کلمات موجود در مجموعه واژگان نشان داده میشود. در این مقاله از فرمول LSTM گریوز استفاده شدهاست. باید توجه داشت که هر جمله باید با یک نماد پایان جمله خاص "" پایان یابد. این نماد مدل را قادر میسازد تا توزیعی را روی دنبالههایی با تمام طولهای ممکن تعریف کند. براساس طرح کلی در شکل 1، LSTM بازنمایی "A","B","C","" را محاسبه میکند و سپس از این بازنمایی برای محاسبه احتمال "W","X","Y","Z","" استفاده میکند.
مدل پیادهسازی شده این مقاله از سه جهت مهم، با توضیحات تئوری بالا متفاوت است:
- اول، در این پژوهش از دو LSTM متمایز یکی برای پردازش دنباله ورودی و دیگری برای دنباله خروجی استفاده شدهاست زیرا انجام این کار اگرچه تعداد پارامترهای مدل را با هزینه محاسباتی ناچیز افزایش میدهد ولی آموزش LSTM را روی چندین جفت زبان مختلف بهطور همزمان امکانپذیر میسازد.
- دوم، پژوهشگران دریافتند که LSTM های عمیق بهطور قابل توجهی بهتر از LSTM های کم عمق عمل میکنند، بنابراین آنها برای این مقاله از یک LSTM چهار لایه استفاده کردهاند.
- سوم، براساس یافتههای پژوهشگران معکوس کردن ترتیب کلمات در جمله ورودی بسیار مفید است. بهعنوان مثال، بهجای نگاشت جمله a,b,c به جمله α,β,γ, از LSTM خواسته میشود که c,b,a را به α,β,γ نگاشت کند. به این ترتیب، a در مجاورت نزدیک α، b نسبتا نزدیک به β، c نزدیک به γ قرار میگیرد. این واقعیت برقراری ارتباط بین ورودی و خروجی را برای SGD آسان میکند. براساس نتایج، این تبدیل داده ساده عملکرد LSTM را تا حد زیادی بهبود میبخشد.
آزمایشات
مجموعه داده
این مقاله از مجموعه داده انگلیسی به فرانسوی WMT'14 استفاده کردهاست. پژوهشگران مدلهای خود را بر روی زیرمجموعهای از 12 میلیون جمله متشکل از حدود 300 میلیون کلمه فرانسوی و انگلیسی آموزش دادهاند. دلیل انجام ترجمه در این زیرمجموعه خاص، دسترسی عمومی به دادههای آموزشی توکنگذاریشده و تست 1000 لیست برتری است که توسط سیستم ترجمه ماشینی پایه SMT ارائه شده است. این دادهها به پژوهشگران امکان میدهد تا عملکرد سیستم خود را با سیستم پایه مقایسه و تحلیل کنند.
'از آنجایی که مدلهای زبان عصبی معمول بر یک بازنمایی برداری برای هر کلمه تکیه میکنند، این مقاله از یک مجموعه واژگان ثابت برای هر دو زبان استفاده کردهاست. پژوهشگران 160هزار کلمه پرتکرار برای زبان مبدأ و 80هزار کلمه پرتکرار برای زبان مقصد را مورد استفاده قرار دادهاند و هر کلمه خارج از مجموعه واژگان با توکن خاص "UNK" جایگزین کردند.
کدگشایی و امتیازدهی مجدد
هسته اصلی آزمایشات این مقاله شامل آموزش یک LSTM عمیق بزرگ بر روی تعداد زیادی جفت جمله بوده است. پژوهشگران این شبکه را با هدف بیشینه کردن احتمال لگاریتمی ترجمه صحیح T با توجه به جمله مبدأ S آموزش دادهاند. بنابراین هدف آموزش بهصورت زیر فرمول میشود:
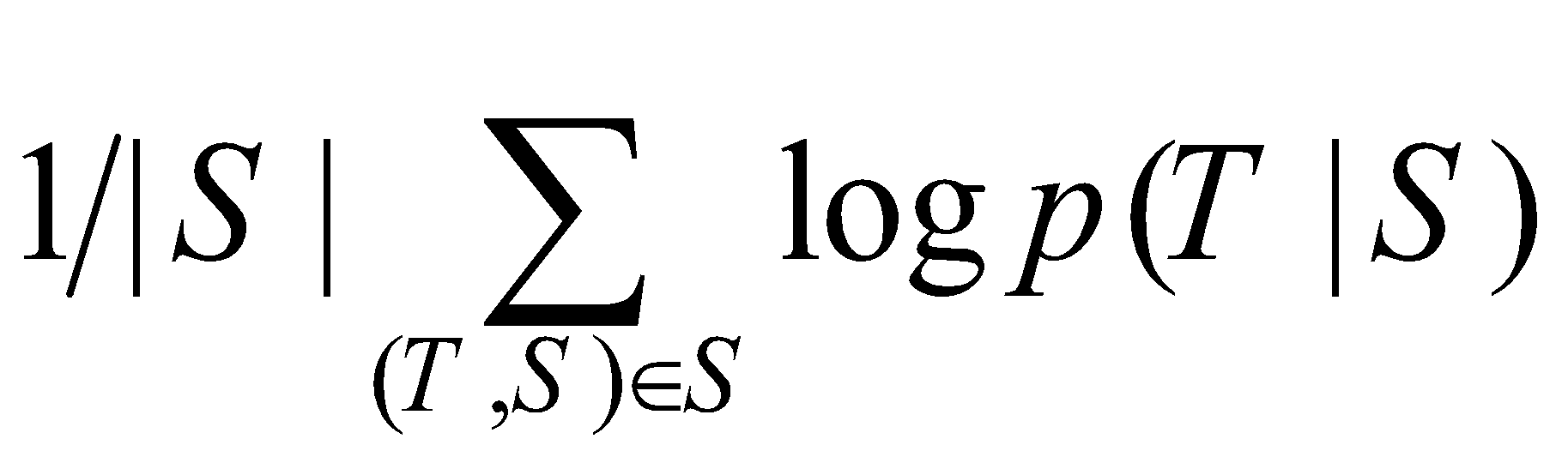
در این فرمول |S| تعداد جملات مبدأ در مجموعه داده است. پس از تکمیل آموزش، محتملترین ترجمه با توجه به LSTM آموزش داده شده استخراج میشود:
در این پژوهش برای یافتن محتملترین ترجمه، از کدگشای ساده جستجوی بیم چپ-به-راست استفاده شدهاست. جستجوی بیم تکنیکی است که برای کاوش چندین ترجمه ممکن در طول کدگشایی استفاده میشود، که در آن اندازه بیم تعداد فرضیههای موردنظر در هر مرحله را تعیین میکند. در واقع در هر مرحله از فرآیند کدگشایی، کدگشا هر کلمه ممکن را در مجموعه واژگان در نظر میگیرد و آن را به انتهای هر فرضیه جزئی در بیم اضافه میکند. این امر تعداد زیادی فرضیه را ایجاد میکند، زیرا کلماتِ ممکن زیادی وجود دارد که میتوان به هر فرضیه اضافه کرد. با این حال، کدگشا نمیتواند همه این فرضیهها را پیگیری کند، بنابراین همه فرضیههای احتمالی B را براساس احتمالات لگاریتم مرتبط با آنها که توسط مدل پیشبینی میشود، کنار میگذارد تا فقط محتملترین فرضیهها برای پردازش بیشتر نگهداری شوند.
هنگامی که نماد "" که پایان یک جمله را نشان میدهد، به یک فرضیه اضافه میشود، آن فرضیه کامل در نظر گرفته شده و دیگر بخشی از فرآیند کدگشایی در حال انجام در نظر گرفته نمیشود. در عوض، با حذف از بیم، به مجموعه فرضیههای تکمیل شده اضافه میشود.
اگرچه این رویکرد کدگشایی دقیق نیست و بهترین ترجمه مطلق را تضمین نمیکند، اما اجرای آن نسبتاً ساده است. سیستم مورد استفاده در این مقاله عملکرد خوبی را حتی با اندازه بیم 1 نشان میدهد (به این معنی که در هر مرحله فقط محتملترین فرضیه را در نظر میگیرد). بهعلاوه، مطابق شکل 2، استفاده از اندازه بیم دو، بیشترِ مزایای جستوجوی بیم با اندازه های بزرگتر را فراهم میکند. این نشان میدهد که اندازه بیم بزرگتر ممکن است کیفیت ترجمه را بهطور قابل توجهی در این مقاله بهبود ندهد. بهطور معمول، اندازه بیم بزرگتر اجازه میدهد تا فرضیههای متنوعتری بررسی شوند، که بهطور بالقوه منجر به ترجمه بهتر میشود. با این حال، در این زمینه حتی با اندازه بیم کوچکتر 2، سیستم به اکثر مزایای مرتبط با جستوجوی بیم دست مییابد. این نشان میدهد که سیستم میتواند با در نظر گرفتن فرضیههای جایگزین نسبتاً کمتر ترجمههایی با کیفیت بالا تولید کند و فرآیند کدگشایی را کارآمدتر کند.
کدگشایی و امتیازدهی مجدد
معکوس کردن جملات مبدأ
در حالیکه LSTM قادر به حل مسائل با وابستگیهای طولانی مدت است، پژوهشگران دریافتند که LSTM زمانی که جملات مبدأ معکوس میشوند(جملات هدف معکوس نمیشوند) بسیار بهتر یاد میگیرد. با انجام این کار، تست پیچیدگی LSTM از 5.8 به 4.7 کاهش یافته و نمرات تست BLEU ترجمههای کدگشایی شده آن از 25.9 به 30.6 افزایش یافته است. با وجود اینکه پژوهشگران توضیح کاملی برای این پدیده ندارند اما معتقدند که دلیل آن بهخاطر وجود وابستگیهای کوتاه مدت متعدد در مجموعه داده است.
بهطور معمول هنگامی که در مدل یک جمله مبدأ و یک جمله هدف بهصورت پشتسرهم در نظر گرفته میشوند، هر کلمه در جمله مبدأ معمولاً از کلمه متناظر خود در جمله هدف فاصله میگیرد که منجر به مشکل"حداقل تاخیر زمانی" میشود. در مقاله برای حل این مشکل، از تکنیکی به نام وارونگی کلمه استفاده میشود. با معکوس کردن کلمات در جمله مبدأ، میانگین فاصله بین کلمات متناظر در زبان مبدأ و هدف یکسان و بدون تغییر باقی میماند. در این حالت، چند کلمه اول در زبان مبدأ با چند کلمه اول در زبان هدف همسو (نزدیک) میشوند. در نتیجه، مشکل حداقل تاخیر زمانی بهطور قابل توجهی کاهش مییابد و بهبود قابل توجهی در عملکرد کلی ایجاد میکند.
در ابتدا، پژوهشگران معتقد بودند که معکوس کردن جملات ورودی تنها منجر به پیشبینیهای مطمئنتر در قسمتهای اولیه جمله هدف و پیشبینیهای با اطمینان کمتر در قسمتهای بعدی میشود. با این حال در جملات طولانی، LSTM هایی که بر روی جملات مبدأ معکوس آموزش داده شدهاند، بسیار بهتر از LSTM های آموزش داده شده بر روی جملات مبدأ خام عمل میکنند.
جزئیات آموزش
براساس یافتههای این مقاله، آموزش مدلهای LSTM نسبتاً آسان است و با استفاده از الگوریتمهای آموزشی مناسب، میتوان مدلهای LSTM را با دقت و کارایی قابلقبولی آموزش داد. یکی از دلایل آسانی آموزش مدلهای LSTM، وجود وابستگیهای کوتاه مدت در حافظه این مدلها است که به مدل کمک میکند تا الگوهای موجود در حافظه خود را در دادههای ورودی تشخیص دهد. دلیل دیگر، توانایی LSTM در بهخاطر سپردن حالتهای پیچیده برای دادههای طولانی است.
در این مقاله از LSTM عمیق با چهار لایه استفاده شدهاست. هر لایه شامل 1000 سلول است و بردار تعبیه کلمات 1000 بُعدی می باشد. LSTM عمیق از برداری با 8000 عدد حقیقی برای بازنمایی یک جمله استفاده میکند. پژوهشگران دریافتند که LSTMهای عمیق نسبت به LSTMهای کمعمق بهطور قابل توجهی موفقیت بیشتری در پیشبینی متن داشتهاند. علاوه بر این، با اضافه شدن هر لایه، عدم قطعیت یا شاخص سختی حدود 10 درصد کاهش پیدا کردهاست. در این مقاله از یک softmax ساده بر روی بردار خروجی با 80هزار کلمه استفاده شدهاست.
اگرچه شبکههای LSTM از مشکل محو شدن گرادیان رنج نمیبرند اما ممکن است با مشکل انفجار گرادیان مواجه شوند. یکی از راهکارهای مقابله با آن استفاده از الگوریتمهای بهینهسازی با روشهایی مانند نرمالسازی گرادیان است. در این روش، مقادیر گرادیان را که بهسرعت افزایش یافته به محدوده مقادیر قابل قبول باز میگرداند. به این منظور، در این مقاله یک محدودیت سخت بر روی مقدار گرادیان اعمال شده تا مقدار آن در بازه [25، 10] باقی بماند. در صورتی که نُرم گرادیان بیش از آستانه تعیین شده باشد، پژوهشگران آن را با مقیاس کردن تغییر میدهند. بهعنوان مثال اگر در هر دسته آموزشی، مقدار ![]() (که در آن g گرادیان تقسیم بر 128 است.) بیشتر از 5 (آستانه مدنظر) شود، مقدار گرادیان g را بهصورت
(که در آن g گرادیان تقسیم بر 128 است.) بیشتر از 5 (آستانه مدنظر) شود، مقدار گرادیان g را بهصورت ![]() مقیاس میکنیم.
مقیاس میکنیم.
در مجموعه دادهها جملههای گوناگون با طولهای مختلفی وجود دارند. اغلب جملات کوتاه هستند (با طول 20-30 کلمه) اما برخی از جملات بلند هستند (طولی بزرگتر از 100 کلمه دارند)، بنابراین یک زیردستهی تصادفی با اندازهی 128 از جملههای آموزشی، تعداد زیادی جملهی کوتاه و چند جملهٔ بلند خواهد داشت و در نتیجه بسیاری از محاسبات در زیر دسته هدر میرود. برای پرداختن به این موضوع یک رویکرد این است که جملات با طولهای مشابه را با هم گروهبندی کنیم. با انجام این کار، میتوانیم اختلاف در مقدار محاسبات مورد نیاز برای پردازش هر جمله را به حداقل برسانیم و بهطور بالقوه به افزایش سرعت دست یابیم. به این منظور پژوهشگران این مقاله اطمینان حاصل کردند که تمام جملات در یک زیردسته تقریباً طول یکسانی داشته باشند که این امر باعث افزایش دو برابری سرعت محاسبات شدهاست.
نتایج تجربی
در این پژوهش از امتیاز BLEU برای ارزیابی کیفیت ترجمهها استفاده شدهاست. نتایج این مقاله در شکل 2و 3 ارائه شدهاست. بهترین نتایج باترکیب چندین LSTM با مقداردهی اولیه تصادفی متفاوت و ترتیب تصادفی زیر دستهها بهدست آمده است. در ترجمه ماشینی، مدلهای LSTM نسبت به مدل پایه SMT با دقت بهتری عمل میکنند، اگرچه هنوز در کنترل کلمات خارج از مجموعه واژگان ناتوان هستند.

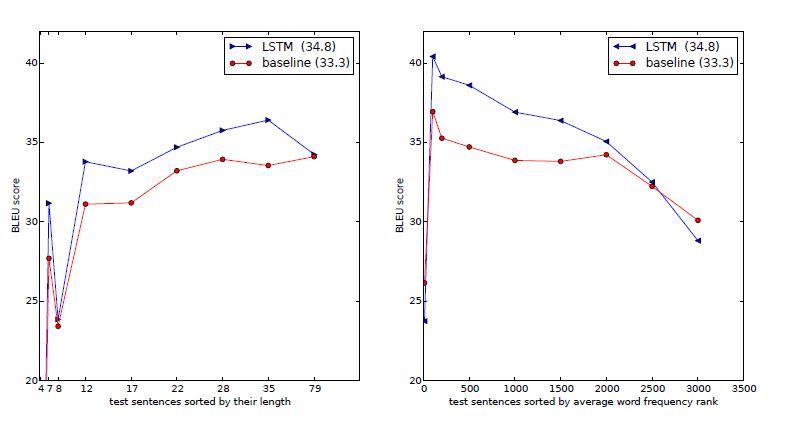
عملکرد در دنبالههای طولانی
براساس یافتههای پژوهشگران، LSTM در جملات طولانی بهخوبی عمل میکند، که خلاصهای از عملکرد آن در شکل 4 نشان داده شدهاست. شکل 5 چندین نمونه از جملات طولانی و ترجمه آنها را ارائه میدهد.

آنالیز مدل
یکی از ویژگیهای مدل پیشنهادی این مقاله، توانایی آن در تبدیل دنبالهای از کلمات به برداری با ابعاد ثابت است. شکل 6 برخی از بازنماییهای آموخته شده در این مدل را به تصویر میکشد. براساس شکل، بازنماییها به ترتیب کلمات حساس هستند، در حالیکه نسبت به تغییر مفهوم فعل نسبتاً غیر حساس هستند (همانطور که در شکل6 سمتچپ مشخص است، با تغییر مفهوم فعل، تغییر کمی در امتیازها مشاهده میشود، برخلاف شکل6 سمتراست که امتیازها به میزان زیادی تغییر کردهاند). در این مقاله مصورسازی پیشبینیهای دو بعدی با استفاده از PCA انجام شده است.
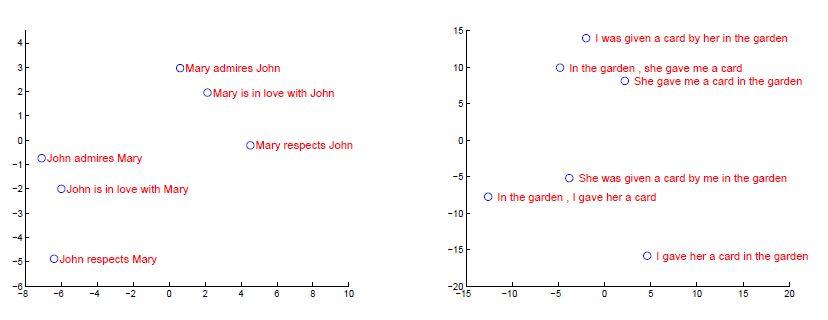
PCA، یک روش آماری برای تجزیه و تحلیل دادهها و کاهش ابعاد است که کمک میکند تا اطلاعات بیشمار موجود در دادهها را بهصورت خلاصه و جامع درک کنیم. PCA با توجه به نمونههای داده، به دنبال محورهای اصلی است که بیشترین واریانس را در دادهها توضیح میدهند. با تعیین این محورهای اصلی، میتوان اطلاعات را به چند بُعد کاهش داده و بهصورت گروههای کوچکتر و قابل تحلیلتر مدل کنیم.
پژوهشهای مرتبط
این مقاله ارتباط نزدیکی با پژوهش کالچبرنر و بلونسوم دارد. آنها اولین کسانی بودند که جمله ورودی را به یک بردار نگاشت و سپس به یک جمله تبدیل کردند. آنها از شبکههای عصبی کانولوشنیبرای نگاشت جملات به بردارها استفاده کردند، اگرچه در آن ترتیب کلمات از دست میرود. مشابه این پژوهش، چو از معماری شبیه به LSTM برای نگاشت جملات به بردارها و بالعکس استفاده کردند، اگرچه تمرکز اصلی آنها بر روی یکپارچهسازی شبکه عصبی خود در یک سیستم SMT بود. برای غلبه بر عملکرد ضعیف در جملات طولانی ترجمه شده توسط مدل چو، بهداناو از یک شبکه عصبی همراه با مکانیزم توجه برای ترجمه مستقیم استفاده کردند و به نتایج قابل قبولی دست یافتند.
نتیجهگیری و کارهای آینده
در این مقاله، پژوهشگران نشان دادند که یک شبکه LSTM عمیق بزرگ با مجموعه واژگان محدود و بدون داشتن پیشفرض درباره ساختار مسئله، میتواند در یک وظیفه مترجمی مقیاسِ بزرگ، عملکرد بهتری نسبت به یک سیستم مبتنی بر SMT استاندارد با واژگان نامحدود داشته باشد. موفقیت رویکرد ساده مبتنی بر LSTM این مقاله در ترجمه ماشینی نشان میدهد که با شرط داشتن دادههای آموزش کافی، این رویکرد احتمالاً در بسیاری از مسائل یادگیری دنباله بهخوبی عمل خواهد کرد.
پژوهشگران براساس میزان بهبود حاصل از معکوس کردن کلمات در جملات مبدأ، به این نتیجه رسیدند که پیدا کردن شیوهای برای کد کردن مساله که بیشترین وابستگی های کوتاه مدت را دارد، بسیار مهم است و مساله یادگیری را بسیار ساده تر می کند. به صورت خاصتر، در حالی که پژوهشگران قادر به اموزش یک RNN استاندارد بر روی مساله ترجمه با جملات عادی نبودند، اما باور دارند که با معکوس کردن جملات مبدأ، یک شبکه RNN استاندارد به راحتی قابل آموزش خواهد بود.(اگرچه این فرضیه را به صورت عملی آزمایش نکردند.)
براساس نتایج ضعیف دیگر پژوهشها در ترجمه جملات بلند با مدلی مشابه با مدل این مقاله، پژوهشگران گمان میکردند که LSTM بر روی جملات بلند به دلیل حافظه محدود خود شکست خواهد خورد. اما مطابق با رویکرد این مقاله، LSTM هایی که بر روی مجموعه داده معکوس آموزش دیدهاند، در ترجمه جملات بلند با مشکلی رو به رو نشدند. مهمتر از همه، نتایج این مقاله نشان داد که یک رویکرد ساده و نسبتاً بهینه نشده میتواند از سیستم SMT عملکرد بهتری داشته باشد. بنابراین، کارهای آتی احتمالاً منجر به دقت بیشتر در ترجمه و سایر مسائل چالشی نگاشت دنبالهبهدنباله خواهد شد.

نظرات